1 連絡と準備
- 小テスト❾ を実施します。
- シラバス記載のように、小テストは最終評価の 35% に相当します。
- 遅刻・欠席等により追試験を希望する場合は第01回講義で案内した手続きをしてください。
1.1 ハンズオン学習の準備
次の手順でSQL演習環境の立ち上げと、教材の更新を取得してください。
- SQL演習環境の動作確認@ 第04回講義
- 教材の更新の取得@ 第04回講義
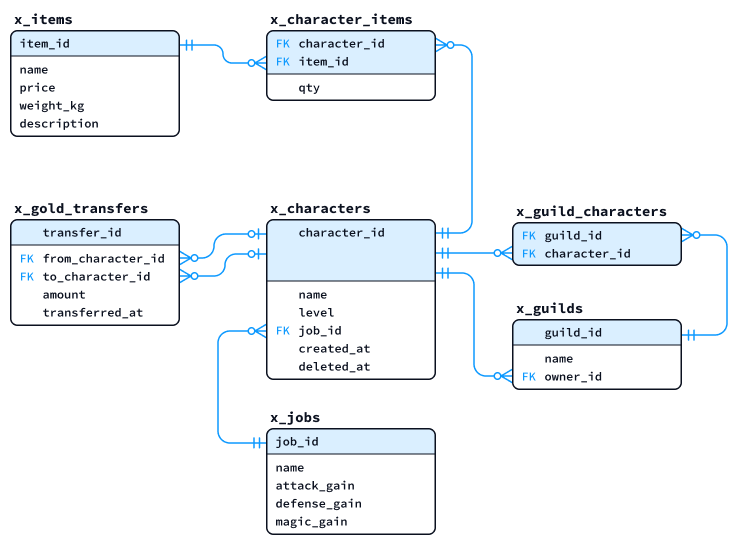
今回の講義では from-teacher/12/init-y_db.sql
で作成するテーブルを使用します。あらかじめ実行して以下のテーブル群 (y_****)
を作成しておいてください。
- y_jobs
- y_items
- y_characters
- y_character_items

また、第10回講義で使用したテーブル群 (x_****)
も使用します。演習環境の from-teacher/10/create-x_db.sql および
insert-x_db_01.sql を再実行し、次のテーブル群を初期化しておいてください。
- x_items
- x_jobs
- x_characters
- x_guilds
- x_guild_characters
- x_character_items
- x_gold_transfers
1.2 今回の講義の概要
今回の講義では、
LEFT JOINとWHEREを組み合せる場合の注意- SELECT文の出力をCSVにエクスポートする方法
- サブクエリを用いてレコードを挿入・更新する方法
- データベースのバックアップ (ダンプ) とリストア
…について学んでいきます。
2 外部結合とWHERE句を組み合せる場合の注意
前回講義では、外部結合
(LEFT JOIN、RIGHT JOIN、FULL JOIN)
について学びました。これら外部結合を含む SQL において、WHERE
句を使用するときは十分に注意してください。
「何をどのように注意すべきか」を実例 (y_**** のテーブル群)
を使って考えていきます。
まず、ジョブを基準にすべてのキャラを列挙する処理 を考えてみます。これは
LEFT JOIN を使って、次のような SQL で記述することができます。
SELECT
j.job_id,
j.name AS "job",
c.name,
c.deleted_at,
CASE
WHEN c.deleted_at IS NULL THEN ''
ELSE 'YES'
END AS "is_deleted"
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON j.job_id = c.job_id -- ◀ 外部結合
ORDER BY
j.job_id;実行結果は、次のようになります。
job_id | job | name | deleted_at | is_deleted
--------+---------+---------+---------------------+------------
1 | Fighter | Tom | |
1 | Fighter | Oscar | |
2 | Monk | | |
3 | Ninja | Zach | 2025-12-31 07:10:00 | YES
4 | Samurai | | |
5 | Priest | Alice | 2025-12-31 07:10:00 | YES
5 | Priest | Marvin | |
6 | Wizard | Charlie | 以上のように LEFT JOIN を使うことで、そのジョブに就いているキャラが存在しなくても、当該ジョブの行 (=
Monk や Samurai ) を結果セットのなかに含めることが可能になりました。
- このことの意味が分からないときは、第11行目 の
LEFT JOIN(左外部結合) をJOIN(内部結合) に変更して結果セットを比べてみてください。
ところで、この結果セットには Alice と Zach という 論理削除されたキャラ (=deleted_at に値が入っているキャラ) が含まれています。
論理削除
y_characters テーブルには、NULL 許容の TIMESTAMP 型の
deleted_at というカラムがあり、このカラムに値が入っていれば その日時で削除されたキャラ、NULL であれば まだ削除されていないキャラ (=現在も有効なキャラ)
という意味を持たせています。
- このように「削除日時を保持するカラム」をテーブルに持たせることによってレコードの有効/無効を管理する方法は、論理削除を実装するための典型的なパターンとなります。
(プロンプト例)
RDBMS および SQL に関する質問です。「論理削除」とは、どのようなテクニックですか。物理削除と比較してのメリットとデメリットについて解説してください。
RDBMS および SQL に関する質問です。論理削除の代表的な実装パターンについて解説してください。
また、ジョブを基準にキャラ人数 (論理削除済みのキャラも含む) を集計する処理 は、次のような SQL で記述することができます。
SELECT
j.job_id,
MAX(j.name) AS "job",
COUNT(c.character_id)
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON j.job_id = c.job_id
GROUP BY
j.job_id
ORDER BY
j.job_id;実行結果は、次のようになります。結果が 0 名になるものを含めて、各ジョブに就いているキャラ人数がカウントできています。
job_id | job | count
--------+---------+-------
1 | Fighter | 2
2 | Monk | 0
3 | Ninja | 1
4 | Samurai | 0
5 | Priest | 2
6 | Wizard | 1いずれの結果も、論理削除済みのキャラ (Alice と Zach) を含んだ 列挙や集計の結果セットとなっています。ここからは、論理削除済みのキャラを除外して列挙・集計する処理 を「どのように行なうか」を考えていきます。
2.1 WHERE 句を用いた処理 (不適切な処理)
「論理削除済みのキャラ」つまり「y_characters.deleted_at
に値 (日時) が格納されているキャラ」を 除外
した列挙・集計するような SQL、つまり y_characters.deleted_at = NULL のキャラだけを対象に列挙・集計する
SQL を考えていきます。
このような要求には、WHERE が利用できそうであり、たとえば、次のような SQL
(先ほどの select-outer_join_01.sql に WHERE c.deleted_at IS NULL
を追加したような SQL) を記述したくなります。
-- ジョブを基準にキャラを列挙 (論理削除済みキャラを含めない)
-- NG な SQL の例
SELECT
j.job_id,
j.name AS "job",
c.name,
CASE
WHEN c.deleted_at IS NULL THEN ''
ELSE 'YES'
END AS "is_deleted"
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON j.job_id = c.job_id
WHERE
c.deleted_at IS NULL -- ◀ WHERE句で論理削除されていないキャラだけを選択
ORDER BY
j.job_id;
-- ジョブを基準にキャラ人数を集計 (論理削除済みキャラを含めない)
-- NG な SQL の例
SELECT
j.job_id,
MAX(j.name) AS "job",
COUNT(c.character_id)
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON j.job_id = c.job_id
WHERE
c.deleted_at IS NULL -- ◀ WHERE句で論理削除されていないキャラだけを選択
GROUP BY
j.job_id
ORDER BY
j.job_id;しかし、この SQL を実際に実行してみると、次のように期待する結果が得られません。
job_id | job | name | is_deleted
--------+---------+---------+------------
1 | Fighter | Tom |
1 | Fighter | Oscar |
2 | Monk | |
4 | Samurai | |
5 | Priest | Marvin |
6 | Wizard | Charlie |
(6 行)
job_id | job | count
--------+---------+-------
1 | Fighter | 2
2 | Monk | 0
4 | Samurai | 0
5 | Priest | 1
6 | Wizard | 1
(5 行)LEFT JOIN を使って、左側テーブル (ジョブ側)
の行は全て結果セットに含めるように意図していましたが、実際には job_id が 3 (=Ninja) が欠落した結果
となってしまいました。
なお、ここで欠けてしまった行は 論理削除されたキャラだけが、当該ジョブに就いていたケース となります。
以上のように LEFT JOIN と WHERE
を組み合わせる場合、外部結合を適用した結果セットに対して WHERE
が適用されるため、(初学者には) 意図せぬ結果となることがあるので注意してください。特に
LEFT JOIN の右側テーブル (ここでの例では y_character)
のカラムを参照する抽出条件を与えると問題が起きやすいので注意してください。
2.2 ON 句で条件抽出処理
論理削除済みのキャラを除外して適切に列挙・集計を行なうためには、LEFT JOIN の
ON 句のなかで c.deleted_at IS NULL
という条件抽出条件を指定します。
具体的には、以下のような SQL を記述します。
-- ジョブを基準にキャラを列挙 (論理削除済みキャラを含めない)
SELECT
j.job_id,
j.name AS "job",
c.name,
CASE
WHEN c.deleted_at IS NULL THEN ''
ELSE 'YES'
END AS "is_deleted"
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON (
j.job_id = c.job_id AND
c.deleted_at IS NULL -- ◀ ON句で論理削除してないキャラのみを選択
) -- ◀ 括弧は省略可
ORDER BY
j.job_id;
-- ジョブを基準にキャラ人数を集計 (論理削除済みキャラを含めない)
SELECT
j.job_id,
MAX(j.name) AS "job",
COUNT(c.character_id)
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON (
j.job_id = c.job_id AND
c.deleted_at IS NULL -- ◀ ON句で論理削除してないキャラのみを選択
) -- ◀ 括弧は省略可
GROUP BY
j.job_id
ORDER BY
j.job_id;実行結果は、以下のようになります。論理削除済みキャラ (Alice と Zach) を除外したうえで、ジョブを基準にキャラを適切に列挙・集計できていることが分かります。
job_id | job | name | is_deleted
--------+---------+---------+------------
1 | Fighter | Tom |
1 | Fighter | Oscar |
2 | Monk | |
3 | Ninja | |
4 | Samurai | |
5 | Priest | Marvin |
6 | Wizard | Charlie |
(7 行)
job_id | job | count
--------+---------+-------
1 | Fighter | 2
2 | Monk | 0
3 | Ninja | 0
4 | Samurai | 0
5 | Priest | 1
6 | Wizard | 1
(6 行)2.2.1 SQLドリル💻
以下、y_**** テーブル群を使用する演習問題です。
ex-01_1👉 (削除されたキャラのジョブ傾向を分析するために) ジョブを基準に 論理削除されたキャラだけ を列挙・集計をしたい。この要求に対して、次のような SQL を記述したが、実行してみると期待する実行結果とはならなかった。「期待する実行結果」が得られるように SQL を修正せよ。
-- 論理削除済みキャラのみを対象として、ジョブを基準にキャラを列挙
SELECT
j.job_id,
j.name AS "job",
c.name,
CASE
WHEN c.deleted_at IS NULL THEN ''
ELSE 'YES'
END AS "is_deleted"
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON j.job_id = c.job_id
WHERE
c.deleted_at IS NOT NULL
ORDER BY
j.job_id;
-- 論理削除済みキャラのみを対象として、ジョブを基準にキャラ人数を集計
SELECT
j.job_id,
MAX(j.name) AS "job",
COUNT(c.character_id)
FROM
y_jobs AS j
LEFT JOIN y_characters AS c ON j.job_id = c.job_id
WHERE
c.deleted_at IS NOT NULL
GROUP BY
j.job_id
ORDER BY
j.job_id;▼ 上記の SQL を実行した結果
job_id | job | name | is_deleted
--------+--------+-------+------------
3 | Ninja | Zach | YES
5 | Priest | Alice | YES
(2 行)
job_id | job | count
--------+--------+-------
3 | Ninja | 1
5 | Priest | 1
(2 行)▼ 期待する実行結果
job_id | job | name | is_deleted
--------+---------+-------+------------
1 | Fighter | |
2 | Monk | |
3 | Ninja | Zach | YES
4 | Samurai | |
5 | Priest | Alice | YES
6 | Wizard | |
(6 行)
job_id | job | count
--------+---------+-------
1 | Fighter | 0
2 | Monk | 0
3 | Ninja | 1
4 | Samurai | 0
5 | Priest | 1
6 | Wizard | 0
(6 行)ex-01_2👉 次に示すように「すべてのアイテムについて、その所持キャラを列挙」したい。ただし、論理削除済みのキャラを除く。この要件を満たすような SQL を記述せよ。
item_id | item | name | qty
---------+---------+--------+-----
1 | Potion | Marvin | 3
1 | Potion | Tom | 2
2 | Map | | 0
3 | Compass | Marvin | 1
4 | Rope | | 0
5 | Knife | | 0ex-01_3👉 次に示すように「すべてのアイテムについて、キャラ通算の総所持数 (total_qty) と、所持キャラ人数 (holder_cnt) を集計」したい。ただし、論理削除済みのキャラを除く。この要件を満たすような SQL を記述せよ。
item_id | item | total_qty | holder_cnt
---------+---------+-----------+------------
1 | Potion | 5 | 2
2 | Map | 0 | 0
3 | Compass | 1 | 1
4 | Rope | 0 | 0
5 | Knife | 0 | 03 CSVのインポートとエクスポート
第05回講義では、CSVファイル から PostgreSQL にレコードを取り込む方法 (インポートする方法) を学びました。本科目の演習環境 (PostgreSQL 17 の Dockerコンテナ) において CSV ファイルをテーブルにレコードとして取り込む手順は、以下のようなものでした。
- ホストOS環境 (ローカル環境) 側で「CSVファイル」を準備する。
- CSVファイルは 文字コード「UTF-8」、改行コード「LF」 を原則とする。
- docker cp コマンドを使って Docker コンテナ (
pg17) に CSV をコピーする。docker cp from-teacher/05/insert-s_users.csv pg17:/tmp/
- 次のような SQL (
COPY文) を用いて CSV からテーブルにレコードを挿入する。
COPY public.s_users (id, name, age)
FROM
'/tmp/insert-s_users.csv'
WITH
(FORMAT csv, HEADER TRUE, NULL 'NULL', ENCODING 'UTF8');今回の講義では、SELECT
文の実行結果を「CSVファイルに出力する方法」について紹介します。
3.1 SELECT文の出力をCSVにエクスポート
次のように COPY (...) TO ... WITH (...) という構文を使って、任意の
SELECT の出力 (結果セット) を
CSVファイルにエクスポートすることができます。
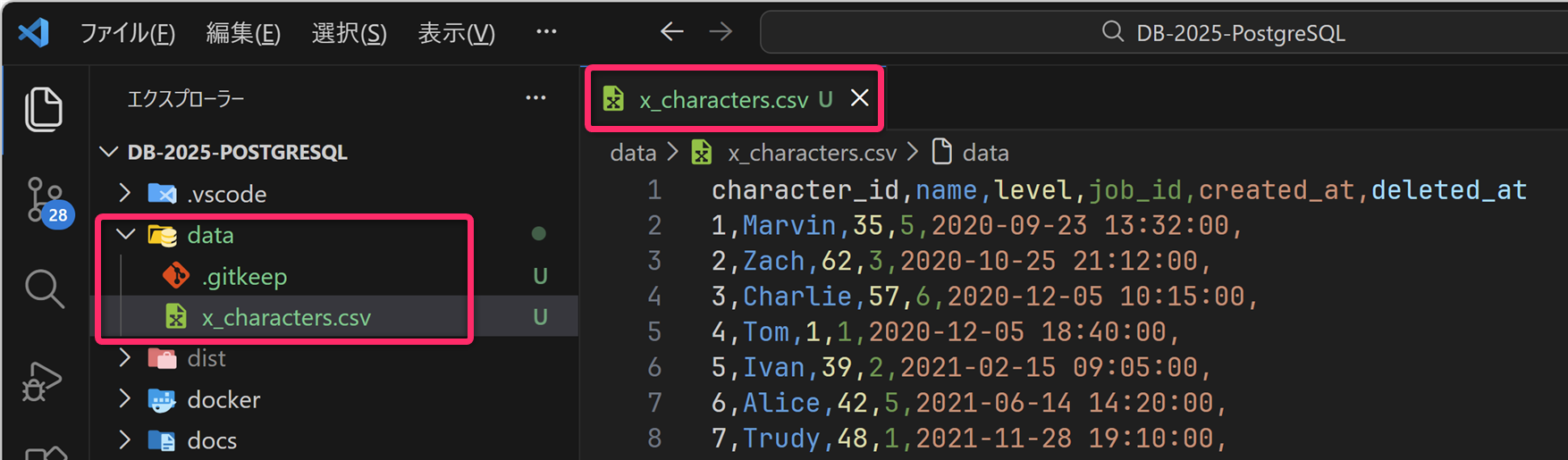
COPY (
SELECT
*
FROM
x_characters
) TO '/tmp/x_characters.csv'
WITH
(FORMAT csv, HEADER TRUE, ENCODING 'UTF8');上記を実行して成功すると、コンソールには次のような応答が表示されます。
COPY 19ここで 19 は 19件分のレコードを出力したこと
を表しています。
CSVファイルは、Docker コンテナ内部の TO
で指定したパス (ここでは 第06行目 で指定した
/tmp/x_characters.csv )
に作成されます。これをホストOS側にコピーするためには、VSCode
のターミナルから以下のコマンドを実行します。
docker cp pg17:/tmp/x_characters.csv ./dataこれにより、docker ps コマンドを実行した位置 (=VSCodeプロジェクトのルート) を基点に data
というフォルダのなかに x_characters.csv がコピー (作成)
されます。実際に実行してみてください。
プロンプト例
PostgreSQL において
COPYコマンドを使用して結果セットを CSVファイル に出力する際、WITH句には、どのようなオプションが設定可能か (どのような出力内容の制御が可能か) 教えてください。
3.1.1 定着確認
- Docker コンテナ
pgの/tmp/out.csvを、ホストOSのカレントフォルダにout_0115.csvという名前で複製したい。この操作を行うための Docker コマンド (ホストOS側で実行) を1行で記述せよ。- 答え:
docker cp pg:/tmp/out.csv ./out_0115.csv
- 答え:
- PostgreSQL において、
SELECT * FROM table1による結果セットをデータベースサーバ上の/tmp/table.csvに CSV 形式で保存したい。次の SQL 文の【1】〜【3】に記述すべき語を答えよ。- 答え: 【1】
COPY、【2】TO、【3】WITH
- 答え: 【1】
3.2 補足: CSV関連のVSCode拡張機能
VSCode に Rainbow CSV や CSV などの拡張機能を導入すると、CSVファイルの内容が確認しやすくなります。必要に応じて導入してみてください。
▼ Rainbow CSV (識別子: mechatroner.rainbow-csv) の導入例
▼ CSV (識別子: repreng.csv) の導入例
両方の拡張機能をインストール・有効化したときは Rainbow CSV が優先適用されるので注意してください。
3.2.1 定着確認
- Docker コンテナ
hogeに存在する/tmp/fuga.txtを、ホスト側 OS のカレントフォルダ配下にdata/fuga.txtとして保存したい。このときに使用するコマンドを答えよ。- 答え:
docker cp hoge:/tmp/fuga.txt data/fuga.txt
- 答え:
4 サブクエリを用いたレコードの挿入
第04回講義では、INSERT文
(超基礎編) として、以下のように VALUES
句を用いて値を直接指定して、1件ずつレコードを挿入する方法を学びました。このように、挿入する値を明示的に記述する方法は「リテラル挿入」とよばれます。
このセクションでは VALUES
句を用いたリテラル挿入ではなく、サブクエリを用いたレコードの挿入
(つまり、既存のテーブルに格納されているレコードを参照し、その取得結果をもとに新しいレコードを挿入する方法)
について学んでいきます。
4.1 準備
このセクションでは、from-teacher/10/create-x_db.sql
で以下のように定義されている x_gold_transfers
というテーブルを使用します。
このテーブルは、キャラクタ同士、あるいはシステムとのあいだで行われた「ゴールドの送受信履歴」を記録するトランザクションテーブル となります。
CREATE TABLE x_gold_transfers (
transfer_id UUID DEFAULT GEN_RANDOM_UUID() PRIMARY KEY,
from_character_id INTEGER REFERENCES x_characters (character_id),
to_character_id INTEGER REFERENCES x_characters (character_id),
amount INTEGER NOT NULL CHECK (amount > 0),
transferred_at TIMESTAMP NOT NULL DEFAULT LOCALTIMESTAMP(0),
CHECK (
from_character_id IS NOT NULL OR
to_character_id IS NOT NULL
),
CHECK (
from_character_id IS NULL OR
to_character_id IS NULL OR
from_character_id <> to_character_id
)
);このテーブルでは、from_character_id または
to_character_id カラムが NULL
の場合、その送受信相手は「システム」であることを表しています。なお、from と
to の両方が NULL になることは、CHECK制約により許可されていません。
たとえば、
(from_character_id, to_character_id, amount) = (NULL, 6, 1000)は、システムから character_id = 6 のキャラに
1000ゴールドが付与されたこと (たとえば クエスト達成時の報酬が運営から支給されたこと など) を表します。
- 第83行目 から 第86行目 は、from_character_id と to_character_id の どちらか一方は必ず値が指定されていなければならない (=非NULLでなければならない) という制約を与えています。
- 第87行目 から 第91行目 は、from_character_id と to_character_id の両方が 非NULL のとき、両者が同じ値であること を禁止するという制約 (送金者=受領者を禁止する制約) を与えています。
以下の演習の準備として SELECT * FROM x_gold_transfers
を実行し、現状で「テーブルのレコードが空であること」を確認しておいてください。
4.2 VALUES 句を用いたリテラル挿入
VALUES
句を用いた「リテラル挿入」の記述について、一度整理しておきます。たとえば…
- Alice (character_id=
6) から Bob (character_id=8) に 1,600G を送金 - Carol (character_id=
18) から Dave (character_id=12) に 28,000G を送金 - システムから Eve (character_id=
14) に 10,000G を支給
…という処理は第04回講義で紹介したように、INSERT INTO ... VALUES ...
の構文を使用して、次の 第08行目 から 第13行目
のように記述することができます。
-- レコードの全削除(念のため)
TRUNCATE TABLE x_gold_transfers RESTART IDENTITY;
-- トランザクションの開始
START TRANSACTION;
-- リテラル挿入(VALUES句を用いた挿入)
INSERT INTO
x_gold_transfers (from_character_id, to_character_id, amount, transferred_at)
VALUES
(6, 8, 1600, '2025-12-28 10:22'),
(18, 12, 28000, '2025-12-30 01:43'),
(NULL, 14, 10000, '2026-01-01 00:01');
-- 確認
SELECT
LEFT(transfer_id::TEXT, 8) AS "id",
COALESCE(from_character_id::TEXT, 'NULL') AS "from",
COALESCE(to_character_id::TEXT, 'NULL') AS "to",
TO_CHAR(amount, '999,999') AS "amount",
transferred_at
FROM
x_gold_transfers;
-- ロールバックによる処理の取り消し
ROLLBACK;- 第17行目 の
LEFT(transfer_id::TEXT, 8)は、UUID型である transfer_id を TEXT型にキャスト したうえで、左から8文字分のみを取得する処理になります。UUID 全体を表示するとカラム幅が大きくなるので8文字だけ表示するようにしています。::TEXTは、PostgreSQL 独自のキャスト記法です。LEFT(CAST(transfer_id AS TEXT), 8)のように書いても同じ結果になります。CASTは 標準SQLの型キャスト構文です。
- 第18行目 の
COALESCE(from_character_id::TEXT, 'NULL')は、INTEGER型である from_character_id をTEXT型にキャストし、値がNULLの場合には 文字列としての'NULL'に置き換えています。COALESCE関数は 最初に見つかった「非NULL値」を返す関数であり、すべての引数は互換性のあるデータ型である必要 があります。
TO_CHAR の FM接頭辞
TO_CHAR では、数値を文字列に変換する際に 指定した書式に合わせて空白による桁合わせ (空白文字によるパディング)
が行われます。この桁合わせ (fill) を無効化したいときは FM接頭辞
(FMプレフィックス) を使用します。
たとえば、FM接頭辞の有無により、次のように出力結果が変化します。
▼ TO_CHAR(amount, '999,999')
id | from | to | amount | transferred_at
----------+------+----+----------+---------------------
2c3444f8 | 6 | 8 | 1,600 | 2025-12-28 10:22:00
d72c7645 | 18 | 12 | 28,000 | 2025-12-30 01:43:00
d38bb426 | NULL | 14 | 10,000 | 2026-01-01 00:01:00▼ TO_CHAR(amount, 'FM999,999')
id | from | to | amount | transferred_at
----------+------+----+--------+---------------------
4d93d4db | 6 | 8 | 1,600 | 2025-12-28 10:22:00
728ab2aa | 18 | 12 | 28,000 | 2025-12-30 01:43:00
e6878e93 | NULL | 14 | 10,000 | 2026-01-01 00:01:00対話的に結果セットを確認する場合 (=現在のように VSCode のコンソールで結果セットを確認する場合など) では「FM接頭辞なし」のほうが可読性に優れます。
一方で、結果セットをCSVファイルエクスポートするときに「FM接頭辞なし」とすると、␠␠␠1,600
のように 先頭に空白文字を含む文字列 が出力されます (␠
は半角スペースの意味)。このようにスペースを含むと、後続のデータ処理で不具合の原因になりやすいため注意してください。
- CSVファイルエクスポートを前提とする場合は、
TO_CHAR関数などで 数値側を文字列型に変換するようなことはせずに、そのまま数値型として出力するようにしてください。
実行結果は、次のようになります。
TRUNCATE TABLE
START TRANSACTION
INSERT 0 3
id | from | to | amount | transferred_at
----------+------+----+----------+---------------------
acb42523 | 6 | 8 | 1,600 | 2025-12-28 10:22:00
daac3f23 | 18 | 12 | 28,000 | 2025-12-30 01:43:00
7907a775 | NULL | 14 | 10,000 | 2026-01-01 00:01:00
(3 行)以上のように データを1件ずつ明示的に指定できる という点でリテラル挿入は直感的で分かりやすく、使いやすい方法と言えます。一方で 条件に合致する複数のレコードをまとめて挿入したい ような場合には、記述量が増え、管理も煩雑になるという問題がでてきます。
たとえば、「ギルドクエストの達成報酬」として、次のような処理を行なう場合を考えてみます。
- ギルド「Yamato」に所属するメンバー全員に 5,000G を支給する
- ギルドのオーナー (所有者) には、上記に追加して 10,000G を支給する (つまり 15,000G を支給する)
この処理を「リテラル挿入」で実行しようとすると、まずは対象となるキャラ (= Yamato
のメンバの character_id ) を、以下のような SELECT
文で事前に把握する必要があります。
SELECT
c.character_id,
c.name,
CASE
WHEN c.character_id = g.owner_id THEN '*'
ELSE ''
END AS "is_owner"
FROM
x_guild_characters AS gc
JOIN x_characters AS c ON gc.character_id = c.character_id
JOIN x_guilds AS g ON gc.guild_id = g.guild_id
WHERE
g.name = 'Yamato' AND
c.deleted_at IS NULL
ORDER BY
c.character_id; character_id | name | is_owner
--------------+--------+----------
1 | Marvin | *
6 | Alice |
7 | Trudy |
12 | Dave |そして、この情報をもとに、次の SQL の 第08行目 から
第11行目 ように VALUES
句を1件ずつ記述していく必要があります。
TRUNCATE TABLE x_gold_transfers RESTART IDENTITY;
START TRANSACTION;
INSERT INTO
x_gold_transfers (from_character_id, to_character_id, amount)
VALUES
(NULL, 1, 15000), -- Marvin ギルドオーナー(所有者)
(NULL, 6, 5000), -- Alice
(NULL, 7, 5000), -- Trudy
(NULL, 12, 5000) -- Dave
;
ROLLBACK;このギルドには対象キャラが4名しかいませんが、これが20人、30人と増えていったとき、それらを
VALUES (...) に1件づつ記述していくことは極めて煩雑であり、また 転記ミスや指定漏れの原因 ともなります。
以上のように挿入すべきレコードの内容(たとえば「誰にいくら付与するか」という情報)が 既存のテーブルのレコードによって決まる ケースでは、「リテラル挿入」ではなく、「サブクエリを用いた挿入」を利用していきます。
4.2.1 SQLドリル💻
以下、x_**** テーブル群を使用する演習問題です。
ex-02_1👉insert-value_01.sqlの 第16行目 からのSELECT文を書き換えて、次のように整形した結果セットを出力するようにせよ。
id | from | to | amount | transferred_at
----------+-------+------+----------+---------------------
de0f591f | Alice | Bob | 1,600 | 2025-12-28 10:22:00
a4d5e736 | Carol | Dave | 28,000 | 2025-12-30 01:43:00
568eac47 | _SYS_ | Eve | 10,000 | 2026-01-01 00:01:004.2.2 定着確認
- UUID型のカラム user_id を
SELECT句で出力する際、UUID 全体ではなく、文字列に変換したうえで「先頭8文字のみ」を表示したい。また、結果セットのカラム名 (ヘッダ) は「識別子」として表示したい。このときに用いるべき式を答えよ。PostgreSQLを前提とすること。- 答え :
LEFT(user_id::TEXT, 8) AS "識別子" - 別解1:
LEFT(CAST(user_id AS TEXT), 8) AS "識別子" - 別解2:
SUBSTR(user_id::TEXT, 1, 8) AS "識別子" - 別解3:
LEFT(FORMAT('%s', user_id), 8) AS "識別子"
- 答え :
- UUID型のカラム user_id を
SELECT句で出力する際、UUID 全体ではなく、文字列に変換したうえで先頭8文字のみを、英字は大文字表記に統一 して表示したい。また、結果セットのカラム名 (ヘッダ) は「識別子」としたい。このときに用いるべき式を答えよ。PostgreSQLを前提とすること。- 答え:
UPPER(LEFT(user_id::TEXT, 8)) AS "識別子" - 別解:
LEFT(UPPER(user_id::TEXT), 8) AS "識別子"
- 答え:
- NULL 許容の INTEGER 型のカラム price を
SELECT句で出力する際、数値が存在する場合は3桁区切りの金額表記(例:5,000円、1,900,000円)で表示し、値がNULLの場合は非売品と表示したい。また、結果セットのカラム名 (ヘッダ) は「売価」とする。このときに用いるべき式を答えよ。PostgreSQL を前提とすること。- price の値は 10,000,000 未満を想定すること。
- 空白文字によるパディング (fill) はしないこと。
- 答え:
COALESCE(TO_CHAR(price, 'FM9,999,999') || '円', '非売品') AS "売価"
4.3 サブクエリを用いたレコードの挿入
レコードの挿入は INSERT INTO ... VALUES ...
の他に、INSERT INTO ... SELECT ...
という構文を用いて行なうこともできます。この構文では SELECT文の実行結果を、そのまま挿入対象として利用すること
が可能となります。
この場合、INSERT 文の内部に記述された SELECT
句がサブクエリとなり、挿入されるレコードとその値を動的に生成
します。つまり、サブクエリを用いて 挿入すべきレコードを動的に生成する
という考え方になります。
先ほどの「リテラル挿入」の例では、
- 対象キャラを
SELECT文で取得するinsert-value_02.sql
- その結果に基づき、手作業で
VALUES (...)を記述するinsert-value_03.sql
…という2段階の作業が必要でした。
これに対して、サブクエリを用いた挿入では、対象キャラの抽出と金額の分岐処理を、次のような
1つの SQL 文で完結させること
が可能となります。一見すると複雑に見えますが、以下の 第08行目 から
第21行目 の SELECT 句で記述している内容は
insert-value_02.sql とほぼ同じものとなっています。
TRUNCATE TABLE x_gold_transfers RESTART IDENTITY;
START TRANSACTION;
-- サブクエリを用いたレコードの挿入
INSERT INTO
x_gold_transfers (from_character_id, to_character_id, amount)
SELECT
NULL,
c.character_id,
CASE
WHEN g.owner_id = c.character_id THEN 15000
ELSE 5000
END
FROM
x_guild_characters AS gc
JOIN x_characters AS c ON gc.character_id = c.character_id
JOIN x_guilds AS g ON gc.guild_id = g.guild_id
WHERE
g.name = 'Yamato' AND
c.deleted_at IS NULL;
-- 確認
SELECT
LEFT(gt.transfer_id::TEXT, 8) AS "id",
COALESCE(fc.name, '_SYS_') AS "from",
COALESCE(tc.name, '_SYS_') AS "to",
TO_CHAR(amount, '999,999') AS "amount",
gt.transferred_at
FROM
x_gold_transfers AS gt
LEFT JOIN x_characters AS fc ON gt.from_character_id = fc.character_id
LEFT JOIN x_characters AS tc ON gt.to_character_id = tc.character_id;
ROLLBACK;ここで注意すべき点は、「サブクエリの結果セットに含まれるカラムの個数・順序・データ型」を、INSERT INTO
句で指定しているカラムと一致させる必要があるということです。本例では
第07行目 において…
x_gold_transfers (from_character_id, to_character_id, amount)…としているので、第08行目 以降のサブクエリ (SELECT 句)
が返す結果セットについても、これに対応したカラム構成 (個数・順序・データ型)
にする必要 があります。
実行結果は次のようになります。
id | from | to | amount | transferred_at
----------+-------+--------+----------+---------------------
ac5dc8fc | _SYS_ | Marvin | 15,000 | 2026-01-01 07:30:55
1b31b2ff | _SYS_ | Dave | 5,000 | 2026-01-01 07:30:55
d08d41c6 | _SYS_ | Alice | 5,000 | 2026-01-01 07:30:55
d8876fe5 | _SYS_ | Trudy | 5,000 | 2026-01-01 07:30:554.3.1 SQLドリル💻
以下、x_**** テーブル群を使用する演習問題です。
ex-03_1👉 運営から「お年玉」として、システムから全キャラ (論理削除済みのキャラを除く) に向けて 2026年1月1日午前4時00分 付けで 25,000G ~ 45,000G (1,000G 刻みのランダム値) を支給するような送金レコードを x_gold_transfers テーブルに挿入する SQL を記述せよ。- ヒント: 乱数の生成(第09回講義)
- ここで記述する SQL は
START TRANSACTION、ROLLBACKで囲んで実行すること。以下、同様。
▼ 実行例
id | from | to | amount | transferred_at
----------+-------+---------+----------+---------------------
daa3a581 | _SYS_ | Marvin | 30,000 | 2026-01-01 04:00:00
932cc09c | _SYS_ | Zach | 38,000 | 2026-01-01 04:00:00
f90e8faf | _SYS_ | Charlie | 39,000 | 2026-01-01 04:00:00
5f5d410e | _SYS_ | Tom | 30,000 | 2026-01-01 04:00:00
~ 略 ~
59bcff20 | _SYS_ | Carol | 30,000 | 2026-01-01 04:00:00
fd88bfa0 | _SYS_ | Jack | 26,000 | 2026-01-01 04:00:00
(17 行)ex-03_2👉 各ギルドにおいてメンバからオーナー (所有者) に対して「共益費」として 2,000G を支払うような送金レコードを x_gold_transfers テーブルに挿入する SQL を記述せよ。- transferred_at は 2025年12月15日午前4時00分 とすること。
- 論理削除済みのキャラを除いて処理すること。
- 各ギルドのオーナーは、自分が所有するギルドに対しては共益費を払う必要はない。
- 各ギルドのメンバ構成は第10回講義の「SQLドリル」の
ex-04_1で記述したコードで確認できる (実行結果の検証用)。
▼ 実行例
id | from | to | amount | transferred_at
----------+--------+--------+----------+---------------------
935a0194 | Alice | Marvin | 2,000 | 2025-12-15 04:00:00
dcd184f5 | Trudy | Marvin | 2,000 | 2025-12-15 04:00:00
c3354257 | Dave | Marvin | 2,000 | 2025-12-15 04:00:00
1e06fd6c | Oscar | Bob | 2,000 | 2025-12-15 04:00:00
01cb481f | Dave | Bob | 2,000 | 2025-12-15 04:00:00
6ee41395 | Steve | Bob | 2,000 | 2025-12-15 04:00:00
1ae49a32 | Jack | Bob | 2,000 | 2025-12-15 04:00:00
36f146f1 | Zach | Ellen | 2,000 | 2025-12-15 04:00:00
9d27424b | Alice | Ellen | 2,000 | 2025-12-15 04:00:00
066f056a | Mallet | Ellen | 2,000 | 2025-12-15 04:00:00
2f1cab0f | Eve | Ellen | 2,000 | 2025-12-15 04:00:00
b719e073 | Wendy | Ellen | 2,000 | 2025-12-15 04:00:00
(12 行)ex-03_3👉 キャラ作成後の初期資金として、運営から各キャラに 1,000G を支給する送金レコードを x_gold_transfers テーブルに挿入する SQL を記述せよ。- 論理削除済みのキャラも含めること。
- transferred_at は、各キャラの created_at の「5分後」とすること。
- 時間の加減演算には
INTERVALを使用する。詳細は生成AIなどを利用して各自で調べること。
- 時間の加減演算には
▼ 実行例
id | from | to | amount | transferred_at
----------+-------+---------+----------+---------------------
2ab6215d | _SYS_ | Marvin | 500 | 2020-09-23 13:37:00
f5d8e680 | _SYS_ | Zach | 500 | 2020-10-25 21:17:00
a92c57f6 | _SYS_ | Charlie | 500 | 2020-12-05 10:20:00
ba01915f | _SYS_ | Tom | 500 | 2020-12-05 18:45:00
~ 略 ~
05a68a32 | _SYS_ | Carol | 500 | 2024-05-11 11:47:00
b6a5e35d | _SYS_ | Jack | 500 | 2024-07-12 15:48:00
(19 行)ex-03_4👉 後衛職応援キャンペーンとして、ジョブが「Priest」または「Wizard」のキャラに、level \(\times\) 1,000G を運営から支給する送金レコードを x_gold_transfers テーブルに挿入する SQL を記述せよ。- 論理削除済みのキャラを除いて処理すること。
- transferred_at は現在日時 (デフォルト値) とすること。
▼ 実行例
id | from | to | amount | transferred_at
----------+-------+---------+----------+---------------------
7165e932 | _SYS_ | Marvin | 35,000 | 2026-01-02 13:54:43
a2cda2a8 | _SYS_ | Charlie | 57,000 | 2026-01-02 13:54:43
dd22194e | _SYS_ | Alice | 42,000 | 2026-01-02 13:54:43
3409604e | _SYS_ | Ellen | 51,000 | 2026-01-02 13:54:43
562f2143 | _SYS_ | Mallet | 64,000 | 2026-01-02 13:54:43
65c4bc28 | _SYS_ | Carol | 28,000 | 2026-01-02 13:54:43
891398db | _SYS_ | Jack | 61,000 | 2026-01-02 13:54:435 サブクエリを用いたレコードの更新
第05回講義では
UPDATE文 (基礎編) として、SET 句や WHERE 句に
直接的に値を指定してレコードを更新する方法 について学びました。
このセクションでは、SET 句や WHERE 句に
サブクエリを用いたレコードの更新
(つまり、既存のテーブルに格納されているレコードを参照し、それをもとに更新後の値を動的に与えたり、更新するレコードを指定したりする方法)
について学んでいきます。
5.1 レコードの更新 (固定値)
UPDATE
文による基本的なフィールドの更新について一度整理しておきます。たとえば、x_jobs テーブルの
Samurai (job_id=4) を対象に…
- attack_gain (現在値
3) を5に更新 - defense_gain (現在値
3) を4に更新
…するための SQL は、次のように記述することができました。
START TRANSACTION;
-- 現在値の確認
SELECT
*
FROM
x_jobs
WHERE
job_id = 4;
-- 更新処理 (更新後の値の確認)
UPDATE x_jobs
SET
attack_gain = 5,
defense_gain = 4
WHERE
job_id = 4
RETURNING
*;
ROLLBACK;この SQL の実行結果 (更新前と更新後の値を出力) は、次のようになります。attack_gain と defense_gain の値が更新されていることが確認できます。
START TRANSACTION
job_id | name | attack_gain | defense_gain | magic_gain
--------+---------+-------------+--------------+------------
4 | Samurai | 3 | 3 | 2
(1 行)
job_id | name | attack_gain | defense_gain | magic_gain
--------+---------+-------------+--------------+------------
4 | Samurai | 5 | 4 | 2
(1 行)
UPDATE 1
ROLLBACK第18行目 の RETURNING 句は第05回講義で学んだように 更新処理とともに、更新後のレコードをあわせて簡易出力するため
の指定となります。任意のカラムだけを出力したい場合は *
の代わりに、具体的なカラム名を記述します。
5.1.1 演習
update-set_01.sql の RETURNING
句を次のように書き換え、実行結果を確認してください。
5.2 レコードの更新 (現在値を利用した更新)
UPDATE
文では「現在値」あるいは「更新対象のレコードの他のカラムの値」を参照し、更新後の値を動的に設定すること
も可能でした。
- 参考: 第05回講義の現在の値を利用した更新
たとえば、job_id が 3 と 4 の各ジョブについて…
- attack_gain を
現在値+1 - defense_gain を
8 - attack_gain - magic_gain
に更新するような処理は、以下のような SQL で記述することができました。
START TRANSACTION;
SELECT
*
FROM
x_jobs
WHERE
job_id IN (3, 4);
UPDATE x_jobs
SET
attack_gain = attack_gain + 1, -- ◀ 変更
defense_gain = 8 - attack_gain - magic_gain -- ◀ 変更
WHERE
job_id IN (3, 4) -- ◀ 変更
RETURNING
*;
ROLLBACK;実行結果は、次のようになります。
job_id | name | attack_gain | defense_gain | magic_gain
--------+---------+-------------+--------------+------------
3 | Ninja | 5 | -1 | 0
4 | Samurai | 3 | 3 | 2
(2 行)
job_id | name | attack_gain | defense_gain | magic_gain
--------+---------+-------------+--------------+------------
3 | Ninja | 6 | 3 | 0
4 | Samurai | 4 | 3 | 2
(2 行)ここで、更新後の defense_gain は、更新前の値を参照した
8 - attack_gain - magic_gain で計算されていることに注意してください。
5.3 サブクエリを用いた更新
UPDATE 文では、SET 句や WHERE
句に「サブクエリ」を用いることも可能です。
たとえば、ギルド「Yamato」に所属する各キャラのレベルが
- 全キャラ平均レベル以下のときは、レベルを
+2する - 全キャラ平均レベルを超えているときは、レベルを
+1する
…ような処理を、次のように「サブクエリ」を使用して一括して実行することができます。
START TRANSACTION;
-- 確認: 全キャラの平均レベル
SELECT
ROUND(AVG(level), 1) AS "avg_lv"
FROM
x_characters
WHERE
deleted_at IS NULL;
-- 確認: Yamato所属キャラの現在レベル
SELECT
character_id,
name,
level
FROM
x_characters
WHERE
deleted_at IS NULL AND
character_id IN (
SELECT
c.character_id
FROM
x_guild_characters AS gc
JOIN x_characters AS c ON gc.character_id = c.character_id
JOIN x_guilds AS g ON gc.guild_id = g.guild_id
WHERE
g.name = 'Yamato'
);
-- 本体: サブクエリを用いた更新処理
UPDATE x_characters AS c
SET
level = c.level + (
SELECT
CASE
WHEN c.level <= AVG(c1.level) THEN 2
ELSE 1
END
FROM
x_characters as c1
WHERE
c1.deleted_at IS NULL
) -- ◀ レベルの増分値をサブクエリで指定
WHERE
c.deleted_at IS NULL AND
c.character_id IN (
SELECT
c2.character_id
FROM
x_guild_characters AS gc
JOIN x_characters AS c2 ON gc.character_id = c2.character_id
JOIN x_guilds AS g ON gc.guild_id = g.guild_id
WHERE
g.name = 'Yamato'
) -- ◀ 更新対象のレコードをサブクエリで指定
RETURNING
c.character_id,
c.name,
c.level;
ROLLBACK;第32行目 から 第60行目
がメインの更新処理になります。やや複雑な SQL となっているので丁寧に読解してください。特に
x_characters は、3カ所
(第32行目、第41行目、第52行目)
で参照されており、それぞれ c、c1、c2
のエイリアスが設定されています。これらの区別に注意しながら読み解くようにしてください。
第33行目 からの
SET句では、全キャラの平均レベルを求めて、更新対象の行のレベル (c.level) と比較して増分値 (+1or+2) を決定するために「相関サブクエリ」を使用しています。第45行目 からの
WHERE句では、更新対象のレコード (=ギルド「Yamato」に所属するキャラのレコード) を「サブクエリ」を使用して指定しています。
実行結果 (更新前と更新後を出力)
は次のようになります。論理削除済みのキャラを除いた全キャラの平均レベルは 47.4
であり、これ以下のレベルのキャラは +2、それ以外は +1
されていることが確認できます。
character_id | name | level
--------------+--------+-------
1 | Marvin | 35
6 | Alice | 42
7 | Trudy | 48
12 | Dave | 68
(4 行)
character_id | name | level
--------------+--------+-------
1 | Marvin | 37
6 | Alice | 44
7 | Trudy | 49
12 | Dave | 69
(4 行)5.3.1 SQLドリル💻
以下、x_**** テーブル群を使用する演習問題です。SQL は
START TRANSACTION、ROLLBACK
で囲んで実行してください。以下、同様。
ex-04_1👉 ジョブが「Priest」「Wizard」以外のキャラについて、レベルを+1するような SQL を記述せよ。- 論理削除済みのキャラを除いて更新すること。
UPDATE文のWHERE句においてサブクエリを用いること。RETURNINGを使用して、次のようなカラムを持った更新情報を出力すること。
character_id | name | updated_level
--------------+-------+---------------
2 | Zach | 63
4 | Tom | 2
5 | Ivan | 40
7 | Trudy | 49
8 | Bob | 34
10 | Oscar | 45
12 | Dave | 69
14 | Eve | 47
16 | Steve | 71
17 | Wendy | 57
解答例は from-teacher に示していますが、実際には様々な別解が存在します。
「自分で考えた SQL」と「解答例の SQL」を比較し、それぞれの書き方や考え方の違いを整理するためには、生成AIを活用してください。
(プロンプト例)
次の 2 つの SQL は、同じ要件を満たすことを目的としたものです。両者を比較しながら「処理内容としての違い」「可読性・保守性・実行効率」「実務で使用する場合にどちらが適しているか」という観点からレビューしてください。
```
UPDATE … ;
``````
UPDATE … ;
```
ex-04_2👉 アイテム「High Mana Potion」を所持しているキャラについて、レベルを+2するような SQL を記述せよ。- 論理削除済みのキャラを除いて更新すること。
UPDATE文のWHERE句においてサブクエリを用いること。RETURNINGを使用して、次のようなカラムを持った更新情報を出力すること。
character_id | name | updated_level
--------------+---------+---------------
3 | Charlie | 59
13 | Mallet | 66
19 | Jack | 63ex-04_3👉 流通数 (全キャラの所持数合計) が 6個以上のアイテムの価格を 1.2倍 (10円単位に切り上げ) に改定するような SQL を記述せよ。- 論理削除されていないキャラのみを対象にアイテムの所持数合計を計算すること。
UPDATE文のWHERE句においてサブクエリを用いること。RETURNINGを使用して、次のようなカラムを持った更新情報を出力すること。
item_id | name | updated_price
---------+--------------+---------------
1 | Potion | 240
5 | Mana Potion | 1200
7 | Antidote | 360
10 | Chimera Wing | 600
11 | Torch | 990ex-04_4👉 各アイテムの価格を「そのアイテムの所持人数 (論理削除済みのキャラを除く) \(\times\) 50G」だけ値上げし、「所持人数 (論理削除済みのキャラを除く) が 0 のアイテムは 100G」だけ値下げするような SQL を記述せよ。- 例: Potion を所持するキャラの人数は 3 人なので、3 \(\times\) 50G だけ値上げする。200G → 350G。
UPDATE文のSET句においてサブクエリを用いること。RETURNINGを使用して、次のようなカラムを持った更新情報を出力すること。
item_id | name | updated_price
---------+------------------+---------------
1 | Potion | 350
2 | High Potion | 700
3 | Mega Potion | 1350
4 | Giga Potion | 3900
5 | Mana Potion | 1150
6 | High Mana Potion | 5150
7 | Antidote | 500
8 | Paralyze Cure | 500
9 | Angel Feather | 1400
10 | Chimera Wing | 750
11 | Torch | 1020
12 | Climbing Rope | 1050ex-04_5👉 各キャラクタのレベルを「そのジョブに就いているキャラ人数 (論理削除済みのキャラを除く)」だけ上げるような SQL を記述せよ。UPDATE文のSET句においてサブクエリを用いること。RETURNINGを使用して、次のようなカラムを持った更新情報を出力すること。
character_id | name | job_id | updated_level
--------------+---------+--------+---------------
1 | Marvin | 5 | 38
2 | Zach | 3 | 64
3 | Charlie | 6 | 61
4 | Tom | 1 | 5
5 | Ivan | 2 | 41
6 | Alice | 5 | 45
7 | Trudy | 1 | 52
8 | Bob | 2 | 35
10 | Oscar | 1 | 48
11 | Ellen | 6 | 55
12 | Dave | 4 | 70
13 | Mallet | 6 | 68
14 | Eve | 3 | 48
16 | Steve | 4 | 72
17 | Wendy | 1 | 60
18 | Carol | 5 | 31
19 | Jack | 6 | 65
(17 行)5.4 FROM句の利用
UPDATE 文では、FROM
句を用いることで「更新対象」や「更新値」を決めるための 参照用テーブル
を指定することができます。
ただし、実際にレコード更新されるのは、あくまで UPDATE 句で指定したテーブルの
SET 句で指定したカラムだけです。FROM 句に記述したテーブルは 更新処理には関与せず、WHERE 句での条件式や、SET
句で更新値を計算する材料として参照するものであること に注意してください。
たとえば、次のように FROM 句に table2 を指定してSET 句や
WHERE 句で参照するように使用します。
UPDATE table1
SET
value1 = (table1 や table2 を参照する式),
value2 = (table1 や table2 を参照する式)
FROM
table2
WHERE
table1.id IN (table1 や table2を参照する式);このように記述した場合、あくまで更新されるのは table1 の value1 カラムと value2 カラムだけとなります。仮に table2 に value1 や value2 という名前のカラムがあっても、それは影響をうけません。
構文的には、以下のように UPDATE 句と FROM
句に同じテーブルを指定することも可能ですが、あまり意味がありません (実質的に FROM
句を省略した UPDATE 文と同じになります)。
一般的には、以下のように のように、 UPDATE
句で指定したテーブルと他テーブルを結合したものをFROM
句に指定して、更新条件や更新値を与えるという使い方が最も多くなります。
UPDATE table1 as t
SET
value1 = (t1 や t2 を参照する式),
value2 = (t1 や t2 を参照する式)
FROM
table1 AS t1 JOIN table2 AS t2 ON t1.id = t2.id
WHERE
t.id IN (t1 や t2 を参照する式);たとえば、先ほどサブクエリを用いて記述した…
ギルド「Yamato」に所属するキャラのレベルが…
全キャラ平均レベル以下のときは、レベルを +2 する
全キャラ平均レベルを超えているときは、レベルを +1 する
…という処理 (update-set_03-a.sql) は、FROM
句を用いて、以下のように記述することもできます。
START TRANSACTION;
-- 本体: FROM句を用いた更新処理
UPDATE x_characters AS c
SET
level = c.level + CASE
WHEN c.level <= a.avg_level THEN 2
ELSE 1
END
FROM
x_guild_characters AS gc
JOIN x_guilds AS g ON g.guild_id = gc.guild_id
CROSS JOIN (
SELECT
AVG(level) AS avg_level
FROM
x_characters
WHERE
deleted_at IS NULL
) AS a
WHERE
c.character_id = gc.character_id AND
c.deleted_at IS NULL AND
g.name = 'Yamato'
RETURNING
c.character_id,
c.name,
c.level;
ROLLBACK;実行すると、先ほどと同様の結果を得ることができます。なお、RETURNING
による出力順が変わることがあります。
(プロンプト例)
SQLに関する質問です。
UPDATE文はUPDATE tbl_1 SET col_1=xxx, col_2=xxx WHERE col_3=xxx;のように記述しますが、これにくわえてFROM句を記述できると聞きました。UPDATE tbl_1により、既にtbl_1を更新対象として指定しているのに、何のためにFROM句を指定するのですか。
(上記のつづきとして) 更新に使う値を取得するための参照テーブルとして
FROM句を与えるとのことですが、新に使う値を取得にはサブクエリも使えると思います。両者の使い分けを教えてください。
(プロンプト例)
SQLに関する質問です。
UPDATE文にFROM句を記述する場合、UPDATE tabale1 SET ...FROM table2 WHERE ...としたとき、内部的には tabale1 (更新対象) と table2 (参照用テーブル) は、どのように対応づけされるのですか。
(プロンプト例)
SQLに関する質問です。
UPDATE ... FROMにおける「多重マッチ問題」とは何ですか。具体例で説明してください。
5.4.1 SQLドリル💻
以下、x_**** テーブル群を使用する演習問題です。難しめです。SQL は
START TRANSACTION、ROLLBACK
で囲んで実行してください。以下、同様。
ex-05_1👉ex-04_1の要求をFROM句を用いたSQLで記述せよ。ex-05_2👉ex-04_2の要求をFROM句を用いたSQLで記述せよ。
5.4.2 SQLドリル💻 (EX)
以下、x_**** テーブル群を使用する演習問題です。かなり難しめです。SQL は
START TRANSACTION、ROLLBACK
で囲んで実行してください。以下、同様。
ex-05_3👉ex-04_3の要求をFROM句を用いたSQLで記述せよ。- なお
FROM句のなかでサブクエリを使用してもよい。
- なお
ex-05_4👉ex-04_4の要求をFROM句を用いたSQLで記述せよ。- なお
FROM句のなかでサブクエリを使用してもよい。
- なお
ex-05_5👉ex-04_5の要求をFROM句を用いたSQLで記述せよ。- なお
FROM句のなかでサブクエリを使用してもよい。
- なお
6 バックアップとリストア
ここでは PostgreSQL におけるデータベースの バックアップ と リストア (復元) について学んでいきます。
6.1 バックアップ
PostgreSQL におけるデータベースの「バックアップ」には pg_dump というコマンドを使用します。dump (ダンプ) とは、コンピュータ分野では ある時点でのメモリやデータの内容をそのまま外部に書き出すこと を指します。pg_dump コマンドは「PostgreSQL データベースの現在の状態 (テーブル定義やデータなど) を、あとから再現できるようにSQLコマンド列 (テキストファイル) として書き出す機能」を提供するツールです。
- pg_dump は、デフォルトでテキストファイルを出力しますが、オプション指定によりバイナリファイルで出力することもできます。
現在の演習環境では、pg_dump は PostgreSQL が稼働している Docker コンテナ内に用意されています。そのため、VSCode のターミナル (ホスト OS 側) から実行する場合は、以下のような docker exec コマンドと組み合わせて実行します。
docker exec pg17 pg_dump -U student playground > data/playground_db_01.sqldocker execはdocker container execの略表記です。docker container execは第02回講義で登場しています。
ここで、pg17 は コンテナ名、-U student は
pg_dump を実行するユーザ名、playground は
バックアップ対象となるデータベース名 を指定しています。これらの指定は
docker/docker-compose.yaml 記載されている設定と対応している必要があります。
- docker/docker-compose.yaml@ GitHub
上記コマンドを実際に実行してみてください。data/playground_db_01.sql
というファイルが作成されて playground
の権限・所有者情報、テーブル定義、データなどのすべての情報がダンプされます
(内容を確認してください)。
pg_dump には、ダンプの用途に応じて出力内容を細かく制御できるように多数のオプションが用意されています。以下では、そのなかでも 基本的なもの に絞って紹介します。
(プロンプト例)
PostgreSQL の pg_dump コマンドの代表的なオプション (実務における使用頻度が高いもの) について解説してください。
6.1.1 --clean --if-exists オプション
--clean --if-exists オプションを指定すると、ダンプファイルのなかに
DROP IF EXISTS などの削除系の SQL 文が書き込まれます。これにより、リストア (復元)
のときに同名のテーブルや制約がすでに存在していても、エラーにならずに処理を進めることができます。
なお、このオプションは pg_dump の実行時には何も削除せず、あくまで「削除用の SQL をダンプに含める」だけである点に注意してください。
docker exec pg17 pg_dump -U student playground --clean --if-exists > data/playground_db_02.sql実際に上記コマンドを実行して、ダンプファイルの先頭付近に
ALTER TABLE IF EXISTS ONLY ... DROP CONSTRAINT IF EXISTS ...
といった制約の削除や、DROP TABLE IF EXISTS ... のようなテーブルの削除に関する SQL
が含まれることを確認してください。
6.1.2 --inserts --column-inserts
オプション
--inserts --column-inserts オプションを指定すると、データの挿入方法が COPY 文ではなく INSERT 文 に変更されます。
COPY 文は第05回講義で紹介したように、CSV
や TSV(Tab-Separated
Values)形式のデータを高速に取り込むための文です。COPY 文のほうが リストアの処理速度が速く、ダンプファイルのサイズも小さく
なりますが、MySQL など 他の RDBMS への移行を想定する場合 には、INSERT
文として出力しておくほうが修正箇所を減らしやすくなります。
docker exec pg17 pg_dump -U student playground --inserts --column-inserts > data/playground_db_03.sql実行後、playground_db_01.sql では COPY
文で記述されていた部分が、playground_db_03.sql では INSERT
文に置き換わっていることを確認してください。
6.1.3 --schema-only と
--data-only オプション
--schema-only
オプションを指定すると、テーブル定義、制約、インデックス、ビュー、関数など、データベースの構造
(スキーマ) に関する情報のみ がダンプされます。レコード (行データ)
は一切含まれません。
このオプションは、本番データを含めずに「空のデータベース」を用意したい場合、スキーマ設計の確認やレビューをしたい場合、テーブル構造だけを別環境に再現したい場合などに使用されます。
一方、--data-only
オプションを指定すると、テーブル定義や制約は含めず、レコードのみがダンプ
されます (リストアの際には、レコードに対応したスキーマが存在している必要があります)。
docker exec pg17 pg_dump -U student playground --schema-only > data/playground_db_04-a.sql
docker exec pg17 pg_dump -U student playground --data-only > data/playground_db_04-b.sqlplayground_db_04-a.sqlにはCREATE TABLEやALTER TABLEなどの定義文のみが、含まれることを確認してください。playground_db_04-b.sqlにはCOPY文やINSERT文によるデータ挿入処理のみが含まれることを確認してください。
6.1.4 定着確認
- PostgreSQL において、データベースのバックアップ (ダンプ) に使用するコマンドを答えよ。
- 答え: pg_dump
6.2 リストア
リストアには psql コマンドを使用します。 psql コマンドは、いつも SQL を実行するために使用しているコマンドです (第02回講義)。
リストアについて実験する前に、現在のデータベース (playground)
の内容について確認しておきます。第02回講義以来、久しぶりにアクセスするひとも多いと思いますが、http://localhost:8080/にアクセスして playground
データベースのなかに存在しているテーブル群を確認してください。
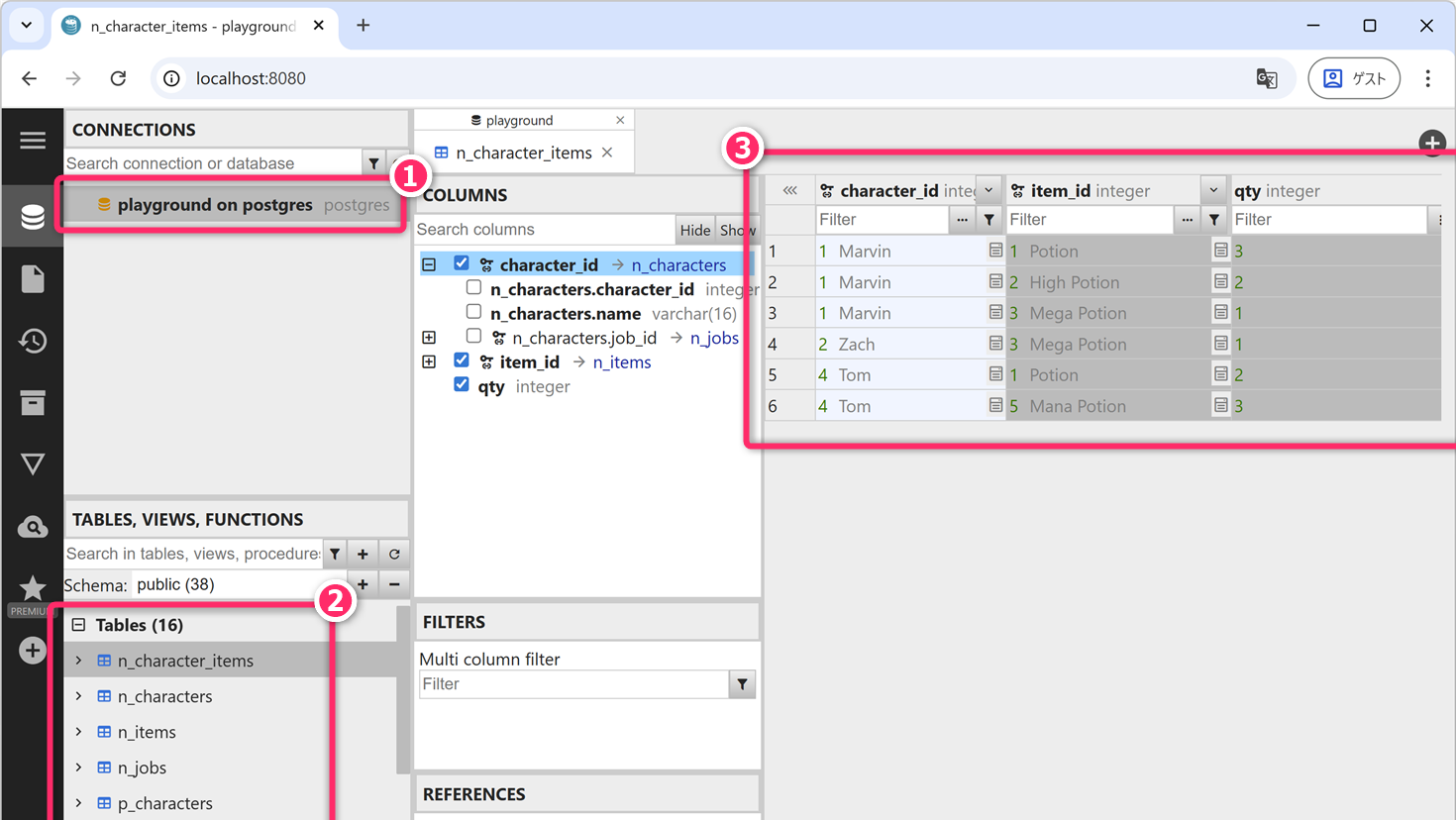
現状で、playground のなかに
n_character_items、n_characters
などの複数のテーブルが存在し、各テーブルには複数のレコードが存在しています。
まずは、リストア (復元) の準備として、pg17 コンテナの ボリュームの削除と初期化 をしていきます。以下のように -v
をつけて down
すると、コンテナのデータを永続化してきたボリューム領域も同時に削除
されます。
docker compose -f docker/docker-compose.yaml -p pg17dev down -v実際に上記コマンドを実行してみてください。
なお、package.json の scripts に定義されているように、本科目の
SQL演習環境では npm run db:reset
というコマンドでも、コンテナの停止とボリュームの削除が実行できます (参照:第03回講義)。
コマンドに成功すると、以下のように pg17 コンテナの内容を永続化をしてきた
pg17dev_pg17_data ボリュームも削除されます。
✔ Container dbgate Removed
✔ Container pg17 Removed
✔ Network pg17dev_default Removed
✔ Volume pg17dev_dbgate_data Removed
✔ Volume pg17dev_pg17_data Removed 👈 注目つづいて、以下のコマンドで、再度、コンテナを起動します。
npm run db:upこの際、以下のようにボリュームが新規作成 (初期化) されます。
✔ Network pg17dev_default Created
✔ Volume pg17dev_pg17_data Created 👈 注目
✔ Volume pg17dev_dbgate_data Created
✔ Container pg17 Healthy
✔ Container dbgate Healthyhttp://localhost:8080/にアクセスして DbGate から
playground データベースの内容を確認してください。以下のように すべてのテーブルが消えていること😭 が確認できます。
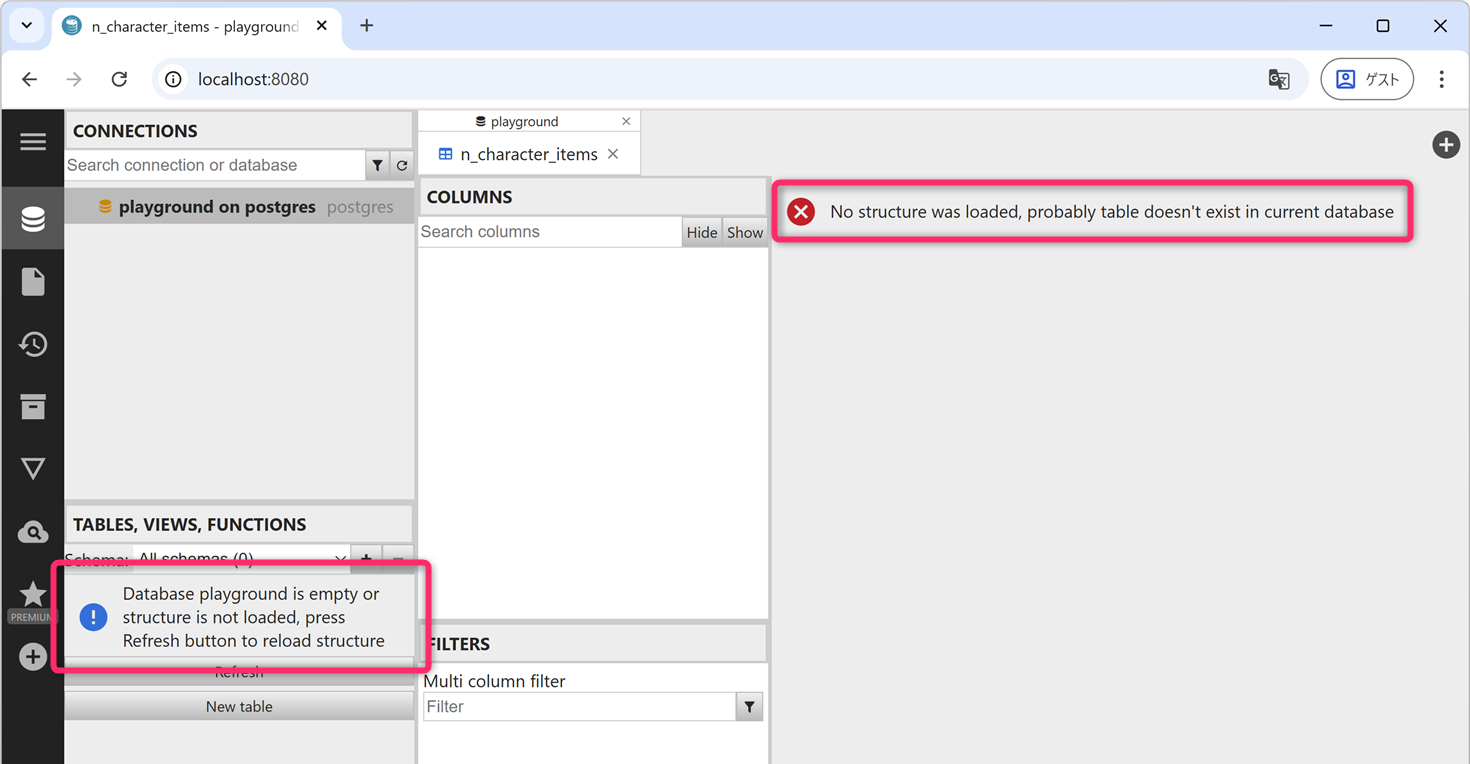
さきほどのダンプファイルを使って、データベースをリストアしています。VSCode のターミナル
(PowerShell) から以下のコマンドを実行してください。ON_ERROR_STOP=1
は、処理の途中でエラーが発生した場合、そこで全処理を停止するオプションです。
gc data/playground_db_01.sql | docker exec -i pg17 psql -U student playground -v ON_ERROR_STOP=1DbGate から playground
データベースの内容を確認してください。リストアできていることが確認できると思います。
上記のコマンドは、PowerShell では bash などで用いられる入力リダイレクト
(<) と同じ書き方ができない関係上、Get-Content
(gc) とパイプを用いて SQL
ファイルの内容を標準入力として渡しているものです。これは、bash や cmd
における次のコマンドと等価です。
docker exec -i pg17 psql -U student playground -v ON_ERROR_STOP=1 < data/playground_db_01.sqlなお、上記のリストアコマンドを再実行すると
ERROR: リレーション"n_character_items"はすでに存在します
のようなエラーで失敗します。これは、既存のテーブルが残っているために生じるもの*です。
既存のテーブルを削除したうえでリストアを実行するときは --clean --if-exists
オプションをつけて pg_dump を実行して生成したファイル (ここでは
playground_db_02.sql) を使用してください。
gc data/playground_db_02.sql | docker exec -i pg17 psql -U student playground -v ON_ERROR_STOP=16.2.1 定着確認
- PostgreSQL において、データベースのリストアに使用するコマンドを答えよ。
- 答え: psql
7 授業時間外学習の指示
🚨本科目は「学修単位科目」であり、1回の講義あたり「4時間相当」の授業時間外学習が求められる科目です🏃
- 次回の講義で「小テスト❿」を実施します。
- 主に SQLドリル、定着確認、演習 から出題します。
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。
- 講義資料内の「演習」や「SQLドリル」に再度取り組んでください。特に、SQLドリル💻 は、授業時間中に1回取り組むだけでは定着しないので注意してください。