1 連絡
- 小テスト❷ を実施します。
- 遅刻・欠席等により追試験を希望する場合は第01回講義で案内した手続きをしてください。
2 SQL演習環境の構築
前回の第02回講義では、PostgreSQLの
Dockerコンテナ を作成・起動し、docker container exec コマンドで
psql を呼び出しました。そして、psql の対話モード
(コマンドライン入力)
で「テーブル作成」や「レコード抽出」などのSQLが実行できることを確認しました。
しかし、今後、ハンズオン形式で SQL を学んでいくにあたって、コマンドラインから直接 SQL を打ち込んで実行する方法は効率が悪くなります。そこで、VSCode で SQL を書いて、それを PostgreSQLコンテナ に対して簡単に発行できるように SQL演習用の環境 を構築していきます。また、同時に TypeScriptプログラムから PostgreSQLコンテナ に接続できるようにも環境を整えていきます。
2.1 リポジトリのクローン
ターミナル (PowerShell) を開いて「SQL演習用の環境」を置きたいフォルダ
(例えば C:\Users\xxxx\Documents など) に移動してください。
- OneDriveで同期しているフォルダはトラブルの原因になるため避けてください。
- パスに日本語が含まれているフォルダもトラブルの原因になるため避けてください。
次のコマンドで、SQL演習用環境 (教材) のリポジトリをクローンしてください。
git clone https://github.com/TakeshiWada1980/DB-2025-PostgreSQL.git DB-PostgreSQLクローンが完了すると、カレントフォルダのなかに DB-PostgreSQL
というフォルダが作成されます。次のコマンドでフォルダ内に移動して VSCode
を起動してください。
cd DB-PostgreSQL
code .2.2 依存関係のインストール
VSCode で [Ctrl]+[J]
を押下してターミナルを開き、プロジェクトの実行に必要なパッケージをインストールしてください。
npm iプログラミング3で学んだように、npm i
は package-lock.json あるいは package.json
に書かれた情報をもとに、プロジェクトが依存するライブラリを自動でインストールするコマンドです。
npm installと入力しても同じ意味になります。
2.3 環境変数の設定
プロジェクトのルートフォルダに .env (環境変数の設定ファイル)
を新規作成してください。そして、.env.dummy ファイルを参考に、次のように
PostgreSQL への接続文字列を記述してください。
DATABASE_URL="postgresql://student:secret123@localhost:5432/playground?schema=public"上記の データベース接続文字列 (DB Connection String) は
docker/docker-compose.yaml のデフォルト設定に対応しています。
docker-compose.yamlは、複数の Docker コンテナの起動方法や接続設定をまとめて管理するための設定ファイルです。
(プロンプト例)
次の docker-compose.yaml を解説してください。
(ここに、プロジェクトのなかの docker/docker-compose.yaml の内容を貼り付ける)
2.4 リモートリポジトリの作成
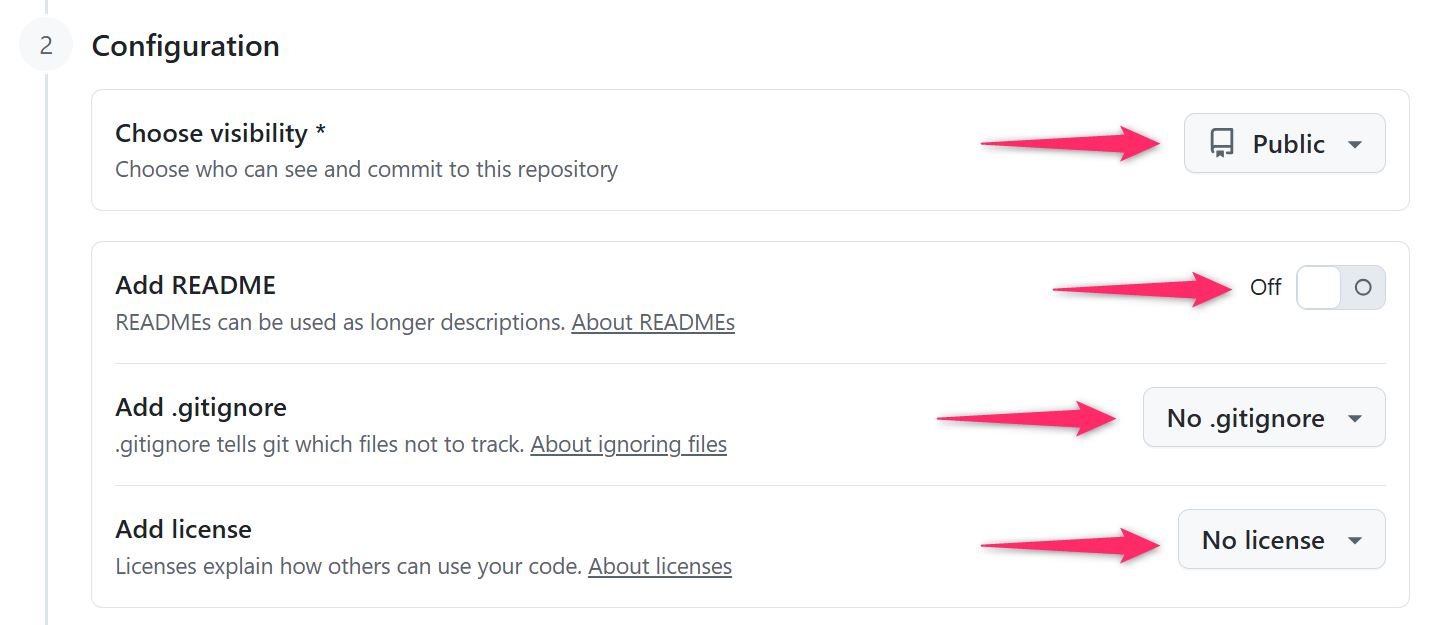
ウェブブラウザから自分のGitHubにアクセスして、DB-PostgreSQL
という名前で「空」の パブリックリポジトリ
を作成してください。この際、以下のように
README.md、.gitignore、LICENSE
などは含めずに、完全に空の状態で作成するようにしてください。
作成したリポジトリのURL https://github.com/xxxx/DB-PostgreSQL.git
をメモしておいてください。
2.5 リモートリポジトリの設定変更
VSCode のターミナルから、次のコマンドを使って、教員が教材として提供したリモートリポジトリを
upstream という名前に変更します。
git remote rename origin upstreamつづいて、先ほど作成した 自分のリモートリポジトリ
(https://github.com/xxxx/DB-PostgreSQL.git) を origin
という名前で追加し、初回の push を実行してください。
git remote add origin https://github.com/xxxx/DB-PostgreSQL.git
git push -u origin mainウェブブラウザから https://github.com/xxxx/DB-PostgreSQL.git
にアクセスして、プッシュが成功していることを確認してください。
ここまで適切に作業できていれば、git remote -v
コマンドの応答が次のようになります。
origin https://github.com/xxxx/DB-PostgreSQL.git (fetch)
origin https://github.com/xxxx/DB-PostgreSQL.git (push)
upstream https://github.com/TakeshiWada1980/DB-2025-PostgreSQL.git (fetch)
upstream https://github.com/TakeshiWada1980/DB-2025-PostgreSQL.git (push)上記は、現在のローカルリポジトリ (PCのプロジェクトフォルダ) が、2つのリモートリポジトリ と接続していることを示しています。
origin は 自分のGitHubアカウント上にあるリポジトリ
を指し、upstream は 教員が公開している元の教材配付リポジトリ
を指しています。教材が更新されたときは upstream から fetch
で変更を取り込み、自分の作業内容 (=演習や課題の取り組み) は
origin に push します。
upstream に対するプッシュを無効化する設定
皆さんが誤って upstream に対してプッシュ操作しても、GitHub
側の権限設定によって操作は拒否されます
(教材が書き換えられることはないので安心してください)。
より安全のために、次のコマンドで、ローカル側で upstream
に対するプッシュを無効化することもできます。
git remote set-url --push upstream DISABLEDこの設定を行うと、git remote -v コマンドの出力は次のようになります。
origin https://github.com/xxxx/DB-PostgreSQL.git (fetch)
origin https://github.com/xxxx/DB-PostgreSQL.git (push)
upstream https://github.com/TakeshiWada1980/DB-2025-PostgreSQL.git (fetch)
upstream DISABLED (push)2.5.1 教材の更新を取得するとき
教材リポジトリ (upstream)
に更新されたときは、次の手順で自分のローカルリポジトリに最新の変更を取り込みます。
以下の作業をする前に自分側のファイル変更は、全てコミットしておいてください。
git fetch upstream
git switch main
git merge upstream/main最後の git merge upstream/main コマンドを実行すると、以下のように VSCode
が自動的にエディタを開き、マージコミットのメッセージを表示します。内容を確認して「続行」ボタンを押してください。
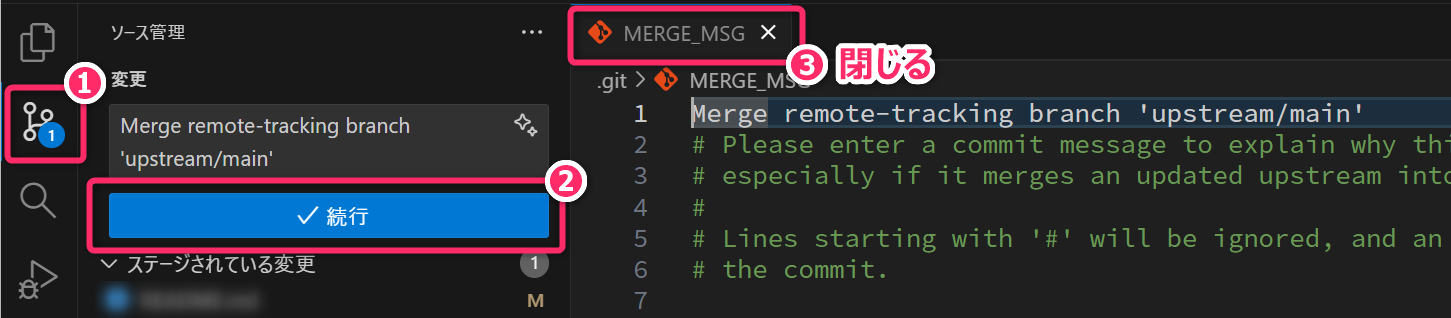
マージが完了したら、MERGE_MSG
のタブは閉じて問題ありません。その後、VSCodeの「変更の同期」のボタンを押下して、自分のリモートリポジトリ
(origin) に変更を反映させます。
2.5.2 演習や課題の取り組みを自分のリモートリポジトリに保存するとき
演習や課題の取り組みを、自分のリモートリポジトリに保存するときは、次のコマンドを実行してください。
git add .
git commit -m "任意のコミットメッセージ"
git pushVSCode の GUI から実行しても問題ありません。
3 SQL整形のための VSCode の拡張機能の追加
SQL の整形 (フォーマット) のために SQL Formatter VSCode (識別子:
renesaarsoo.sql-formatter-vsc) という拡張機能を追加してください。
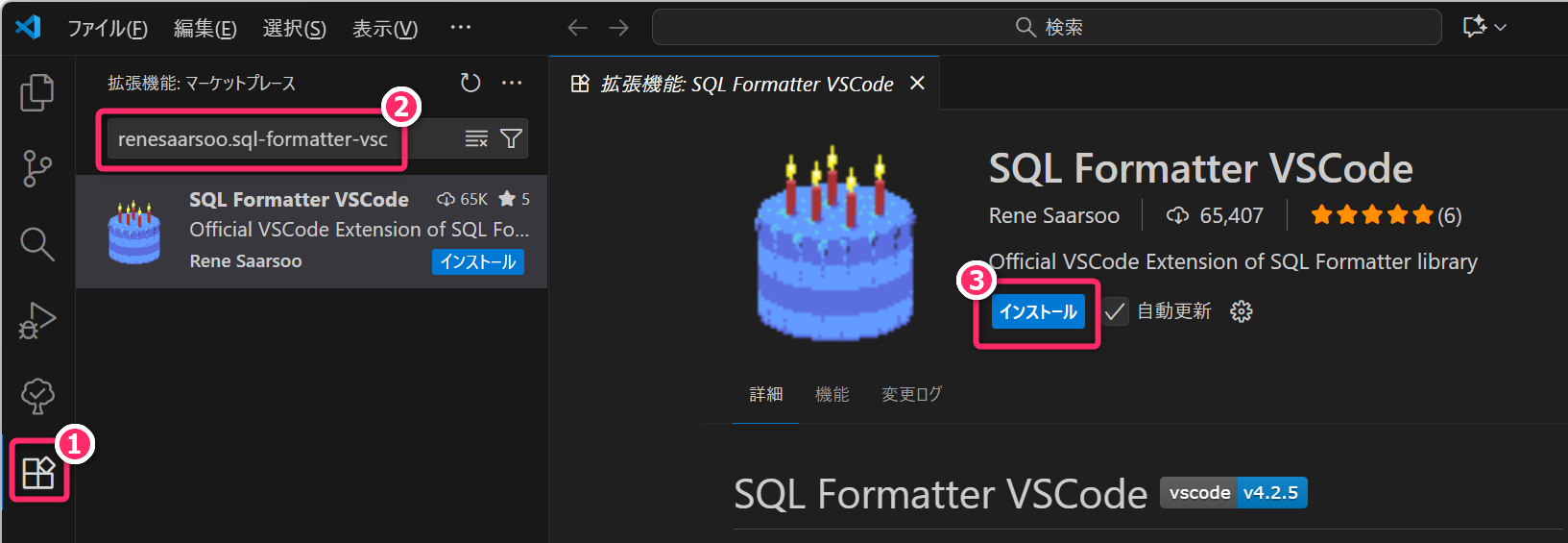
この拡張機能と .vscode/settings.json の設定により、.sql
ファイルの保存時に SQL が自動整形されるようになります。
"[sql]": {
"editor.defaultFormatter": "ReneSaarsoo.sql-formatter-vsc"
},
"SQL-Formatter-VSCode.keywordCase": "upper",
"SQL-Formatter-VSCode.denseOperators": false,
"SQL-Formatter-VSCode.linesBetweenQueries": 1,
"SQL-Formatter-VSCode.expressionWidth": 80,
"SQL-Formatter-VSCode.functionCase": "upper",
"SQL-Formatter-VSCode.logicalOperatorNewline": "after",
"SQL-Formatter-VSCode.dialect": "postgresql"3.1 任意: Code Spell Checker 拡張機能のインストール
SQLの演習に際してCode
Spell Checker(識別子:
streetsidesoftware.code-spell-checker)をインストールしておくことをお勧めします。
この拡張機能は、コード内の英単語のスペルミスを検出して、控えめな下線表示で警告してくれるものです。テーブル名やカラム名は、原則として英語で記述するため、スペルミスを防ぐ目的でスペルチェッカを導入しておくと便利です。
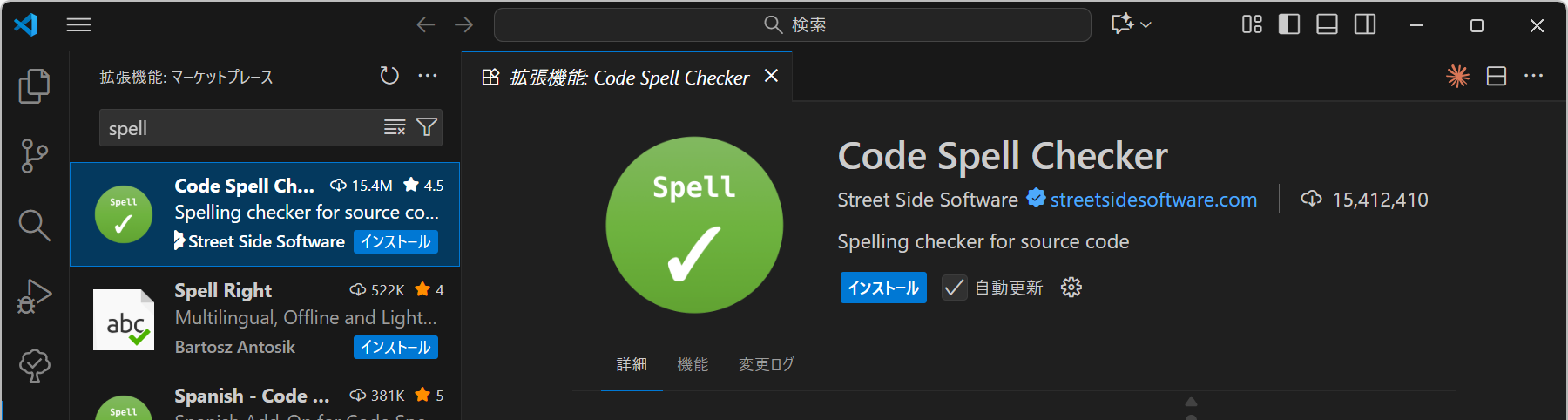
なお、Code Spell Checker
が専門用語や略語を誤って「スペルミス」と判断しないようにするには
.vscode/settings.json に単語を登録してチェック対象外に設定します。
- .vscode /settings.json@ GitHub
4 Docker コンテナの起動と終了
4.1 準備: Docker Desktop の起動確認
はじめに Docker Desktop が起動済みで、ステータスが「Running」となっていることを確認してください。タスクトレイにアイコンが見つからない場合はスタートメニューから「Docker Desktop」を探して手動で起動してください。
4.2 準備: コンテナの確認と削除 (初回のみ)
前回講義で手動で作成した pg17
というコンテナが残っていると、以降の作業に影響するので (コンテナの名前が衝突するので)
削除しておきます。
次のコマンドで、停止中のものを含めて全てのコンテナを表示します。
docker ps --allNAMES が pg17
のコンテナがあれば、次のコマンドで削除してください。
docker container rm pg174.3 コンテナの起動
次のコマンドで PostgreSQL と DbGate のコンテナを起動します。
npm run db:upこれは package.json の scripts
に定義されたコマンドで、実際には次のような docker compose
コマンドが実行されます。Docker Compose とは 複数のコンテナを協調して動かすための仕組み です。
docker compose -f docker/docker-compose.yaml -p pg17dev up -d --wait- package.json@ GitHub
- docker/docker-compose.yaml@ GitHub
docker ps で起動中のコンテナを確認すると、次のように表示されます (紙面の都合で
COMMAND、CREATED、STATUS の3項目は省略しています)。
CONTAINER ID IMAGE PORTS NAMES
5f43ab3cb20a dbgate/dbgate:6.6.3 0.0.0.0:8080->3000/tcp, [::]:8080->3000/tcp dbgate
9f1ae6c1a832 pg17dev-postgres 0.0.0.0:5432->5432/tcp, [::]:5432->5432/tcp pg17この表示から、DbGate (dbgate) と PostgreSQL
(pg17) の2つのコンテナが起動したことが分かります。なお、PORTS
には、割り当てられているポート番号が ホストのポート番号->コンテナのポート番号
の形式の形式で表示されます。すなわち、ホストOS (Windows) の 8080
番ポートから、DbGate コンテナの 3000番ポートにマッピングされていることが分かります。
Docker Desktop からも、次のように2つのコンテナが起動していることが確認できます。
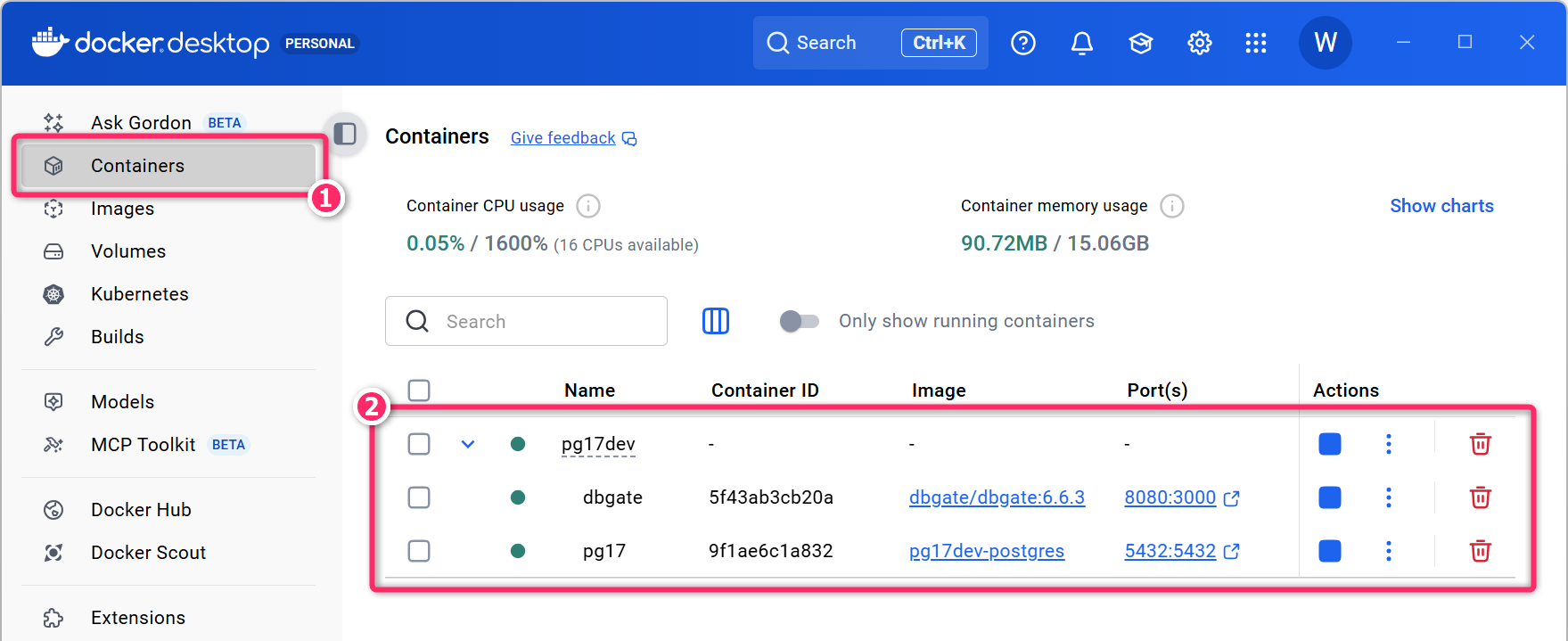
Docker Desktop では、pg17dev という Compose Project
(コンポーズプロジェクト) のなかで、dbgate と pg17
の2つのコンテナが起動していることが確認できます。
4.3.1 定着確認
docker psコマンドを実行した結果、あるコンテナの PORTS の項目が0.0.0.0:8001->80/tcpと表示された。これは、コンテナの8001番ポートが、ホストの80番ポートにマッピングされていることを示す。この説明は「適切である」か「適切ではない」か答えよ。- 答え: 適切ではない
4.3.2 演習
既にコンテナが起動しているとき、再度 npm run db:up
コマンドを実行するとどうなるか確認してください。
4.4 コンテナの停止
次のコマンドで PostgreSQL と DbGate の2つのコンテナ
(Compose Project pg17dev 配下の全てのコンテナ) を停止することができます。
npm run db:downこれも package.json の scripts
に定義されたコマンドで、実際には次のような docker compose
コマンドが実行されます。
docker compose -f docker/docker-compose.yaml -p pg17dev downなお、コンテナを停止しても、データベースに保存された情報は Docker
のボリュームに永続化されているため、そのまま保持されます。そのため、再び
npm run db:up
でコンテナを起動すれば、前回の状態を引き継いで利用することができます。
一方で、データベースを初期状態に戻したい場合 (=Docker ボリュームを含めてすべて削除したい場合) は、次のコマンドを実行してください。
npm run db:resetnpm run db:resetを実行すると、これまでに作成したテーブルやレコードがすべて消去されます。完全にゼロから演習をやり直したいときや、データベースを初期状態に戻したい場合に使用してください。- コンテナを削除 (≠停止) しても、Docker ボリュームを削除しない限り、データベースの内容は永続化されて残ります。そのため、同じボリュームを指定して新たにコンテナを作成すれば、以前と同じデータを引き続き利用することができます。
- Docker ボリュームの一覧は
docker volume lsコマンドで確認ができます。また、Docker Desktop からも確認ができます。
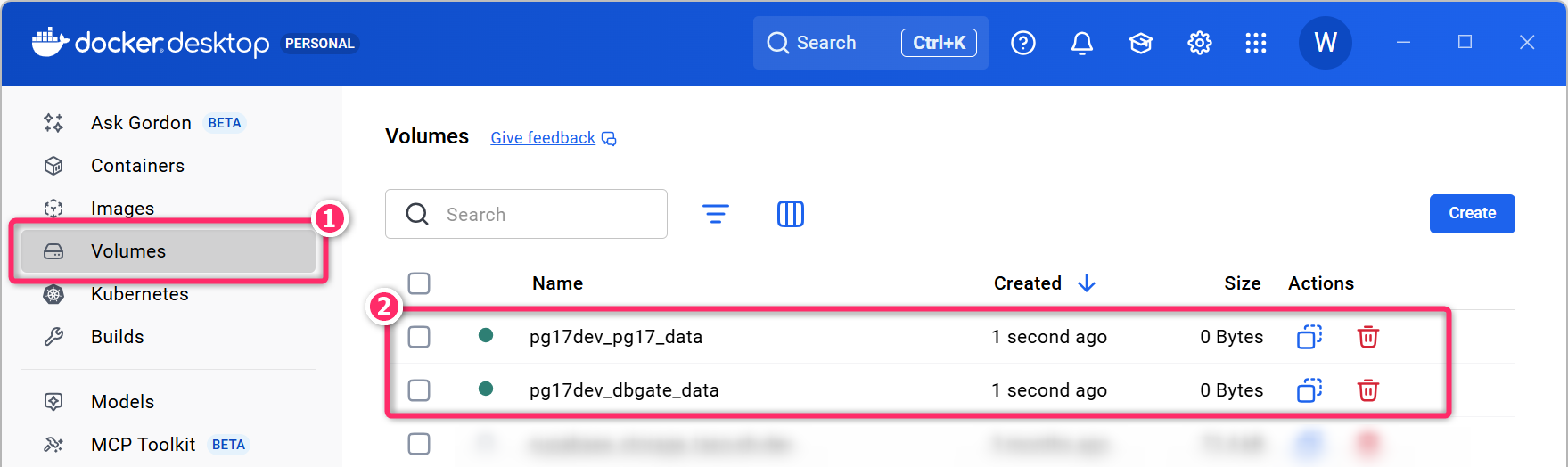
Docker Volume について
本科目では、Docker Volume については詳しく扱いませんが、実務で Docker を利用する場合、ボリュームは非常に重要な概念となります。関心のある学生は、YouTubeやAIなどを利用して概要だけでも把握しておくことをお勧めします。
(プロンプト例)
「Docker ではコンテナを削除しても、ボリュームを削除しない限り、データは永続化されて残り、同じボリュームを指定して再度コンテナを作成すれば、以前と同じデータを引き続き利用することができる」と聞きました。これは、どういうことですか。詳しく説明してください (>_<)/
5 SQLファイルの実行
前のセクションでコンテナを停止させている場合は、再度、npm run db:up
でコンテナを起動しておいてください。
前回講義では、PostgreSQL の CLI クライアントツールである psql に、直接 SQL文
を打ち込んで (またはコピー&ペーストして) クエリを実行しました (参照)。しかし、このような方法は
SQL の 再利用や修正がしづらく、実行内容の記録や共有にも適さない
ため、ここでは SQL をファイルに記述 して、それを psql
に流し込む方法をとります。※ Python
にも対話モードがありますが、それを使って開発することはありませんよね?それと同じです。
5.1 SQLファイルの作成
SQLファイルは、拡張子を .sql
として、原則として sql
フォルダのなかに配置してください。
ファイル整理の観点から、第03回講義なら 03、第04回講義なら 04
のようなサブフォルダを作成し、そこに配置することを推奨します
(フォルダやファイルの名前に日本語を使用すると予期せぬ不具合が生じる可能性があるので注意してください)。
実際に、試してみましょう。SQL演習環境 (プロジェクトフォルダ) のなかに
sql/03/init-s_users.sql を新規作成して…

次の SQL を記述して保存してください。このファイルは、4つのSQL文から構成されています
(文の区切りは ; で判断してください)。
-- 既に同名のテーブルがあれば削除する
DROP TABLE IF EXISTS s_users;
-- ユーザ情報を保持するテーブルを作成する
CREATE TABLE s_users (id INT PRIMARY KEY, name TEXT NOT NULL, age INT);
-- テーブルにレコード(ユーザ情報)を挿入する
INSERT INTO
s_users (id, name, age)
VALUES
(1, 'Alice', 20),
(2, 'Bob', 25);
-- すべてのレコードを抽出する
SELECT * FROM s_users;保存の際、VSCode拡張機能のSQL Formatter
VSCodeが有効に機能していれば、SELECT
文が以下のように自動整形されるはずです。
SQL Formatter VSCode の細かな挙動は、以下のファイルで設定 (カスタマイズ) が可能です。
- .vscode /settings.json@ GitHub
5.2 SQLファイルの実行
この SQL演習環境 において sql/03/init-s_users.sql (SQLファイル)
は、次のコマンドで実行可能です (実行可能なように環境を構成しています)。
npm run sql sql/03/init-s_users.sql- パスは プロジェクトのルートを基準に指定してください。
- 区切り文字 (パスセパレータ) には
\と/のどちらも使用できます。
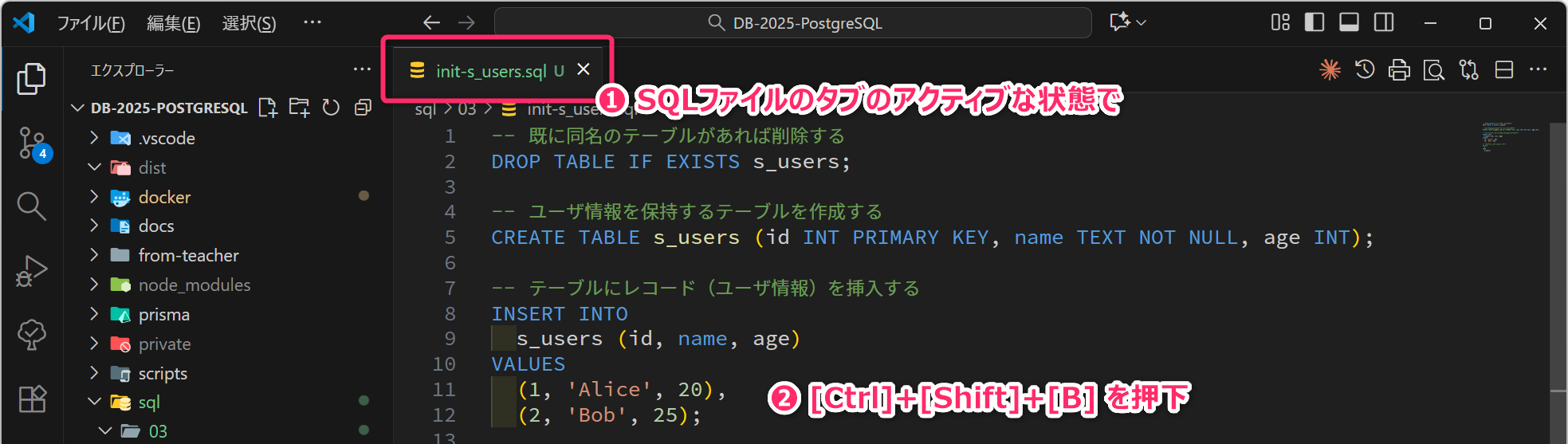
また、.vscode/tasks.json
にビルドタスクを定義しているので、init-s_users.sql
のエディタタブがアクティブな状態で [Ctrl]+[Shift]+[B]
を押下することで、上記コマンドを実行することもできます
(実行できるように環境を構成しています)。
[B]は ビルド (Build) の B です。- .vscode /tasks.json@ GitHub
正常に実行できると、次のような応答が返ってきます。
DROP TABLE
CREATE TABLE
INSERT 0 2
id | name | age
----+-------+-----
1 | Alice | 20
2 | Bob | 25
(2 行)5.2.1 演習
- 誤ったファイルパスを引数に
npm run sql ...を実行するとどうなるか確認してください。 - コンテナが起動していない状態 (だだし、Doker Desktop は起動している状態) で
npm run sql ...を実行すると ([Ctrl]+[Shift]+[B]のショートカットを実行すると) どうなるか確認してください。 - Doker Desktop が起動していない状態で
npm run sql ...を実行すると ([Ctrl]+[Shift]+[B]のショートカットを実行すると) どうなるか確認してください。
5.3 GitHub Copilot の設定
SQLの構文理解やクエリ設計力を身につけるため、学習段階では SQL についての「GitHub Copilot の補完機能」を OFF にしておくことを推奨します。
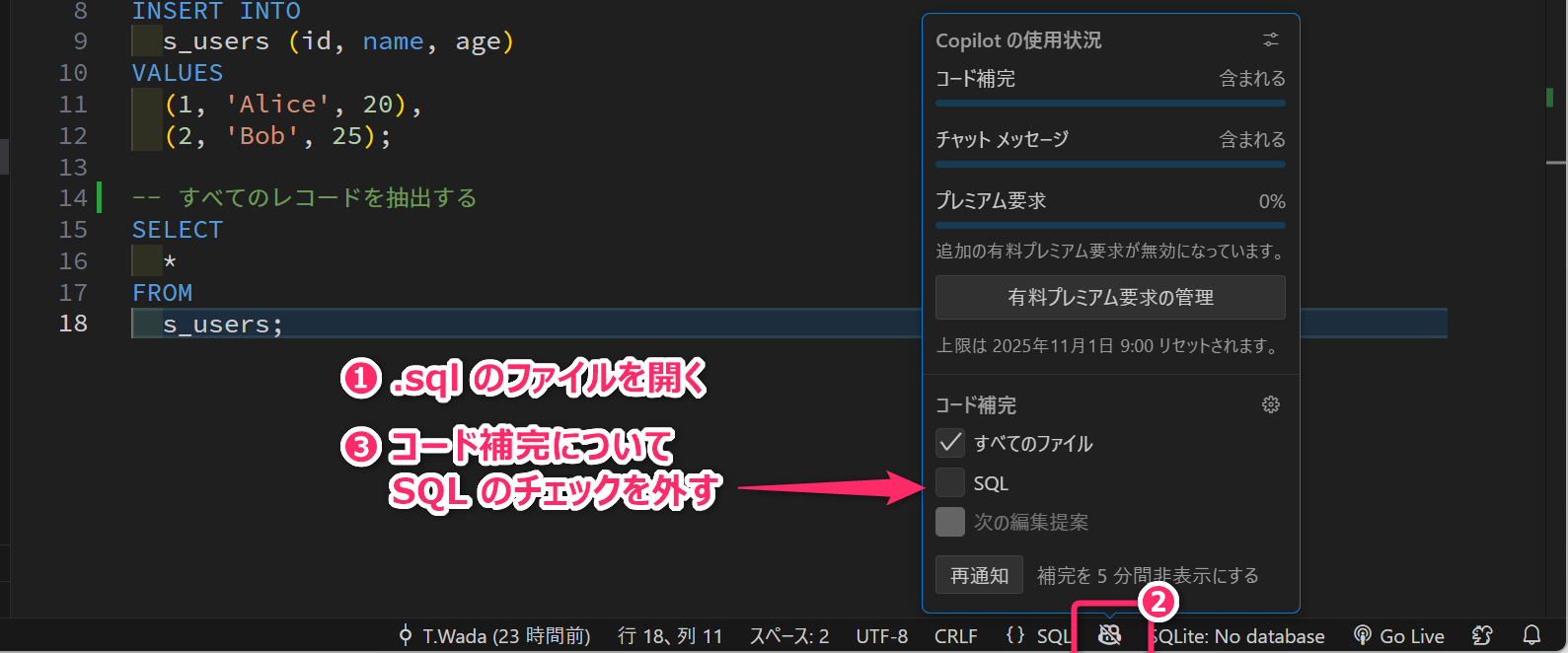
6 TypeScriptファイルの実行
この SQL演習環境 において TypeScriptファイル は、基本的に src
フォルダのなかに、必要に応じてサブフォルダを作成して配置してください。
例えば、src/samples/helloWorld.ts
というファイルは、次のコマンドで実行できるようになっています。
npx tsx src/samples/helloWorld.tsまた、ファイルの変更を検知して自動的に再実行したい場合
(=ホットリロードを利用する場合)
は、次のコマンドを使用してください。停止する場合は、ターミナル上で [Ctrl]+[C]
を入力してください。
npx tsx watch src/samples/helloWorld.tsまたは、次のように npm スクリプト (package.jsonで定義しているスクリプト)
経由で実行もできます。
npm run dev src/samples/helloWorld.ts6.0.1 演習 (授業時間外学習)
この演習については 授業時間外学習 として取り組んでください。授業時間中は、次のセクションに進んでください。
- プロジェクトフォルダのなかの
src/samples/pgSample.tsは、PostgreSQL と Node.js を接続するための公式ドライバである pg を利用した TypeScript の実装例です。実際に、実行してみてください。また、生成AIを活用してプログラムの読解にも挑戦してみてください。- pgSample.ts@ GitHub
- プロジェクトフォルダのなかの
src/samples/drizzleSample.tsは、Drizzle という ORM を使って PostgreSQL と接続するTypeScript の実装例です。実際に、実行してみてください。また、生成AIを活用してプログラムの読解にも挑戦してみてください。- drizzleSample.ts@ GitHub
- プロジェクトフォルダのなかの
src/samples/prismaSample.tsは、Prisma (ORM) を使って PostgreSQL と接続するTypeScript の実装例です。実際に、実行してみてください (事前処理が必要です、ファイル内の説明をよく読んでから実行してください)。また、生成AIを活用してプログラムの読解にも挑戦してみてください。- prismaSample.ts@ GitHub
(プロンプト例)
以前、TypeScript において「Prisma」という ORM を使用したことがあります。きょう、授業のなかで「Drizzle」という ORM もあることを知りました。両者の違いや、使い分けについて分かりやすく教えてください。
7 レコードの抽出
ここからはRDB に対する各種操作 (クエリ) のなかでも、利用頻度の最も高い
レコードの抽出操作 (SELCT 文) について学んでいきます。
- RDB に関する文脈において クエリ (Query) とは、データベースに対する 「要求」「操作」問い合わせ」 を SQL (=Structured Query Language) で記述したものを意味します。
7.1 準備: テーブルの作成とレコードの挿入
プロジェクトフォルダ内の from-teacher/03/init-s_characters.sql
を、sql/03/init-s_characters.sql にコピーしてください。
その後、ターミナルから次のコマンドを実行、もしくは当該ファイルをエディタで開いている状態で
[Ctrl]+[Shift]+[B] を押下して、SQL を実行してください。
npm run sql sql/03/init-s_characters.sql- コマンドの応答を確認し、エラーが発生していないことを確かめてください。正常に実行処理できていれば
CREATE TABLE、INSERT 0 xxのような応答が返ってきます。 - PostgreSQL からのエラーメッセージを英語表示にしたい場合は
npm run sql:en (ファイル名)のようにコマンドを実行してください。
この init-s_characters.sql のなかには、s_characters
というテーブルを作成する CREATE 文と、そのテーブルにレコードを挿入する
INSERT 文が記述されています。これら CREATE 文や、INSERT
文についての詳しい解説は、次週以降の授業で扱っていきます。現段階では、簡単に目を通しておくだけで大丈夫です。
この s_characters (キャラクタ) テーブルは、次のような「8つのカラム」で構成されています。このあと、このテーブルに対してSQL文を書くので概要は把握しておいてください。
id: レコードを一意に識別するID。整数型。主キー。自動採番されNULLは不可。name: キャラクタ名。最大16文字の可変長文字列型。NULLは不可。- 標準 SQL において、格納可能な最大文字数が決められた可変長文字列型を VARCHAR型 といいます。
job: ジョブ (職業)。最大16文字の可変長文字列型。NULLは不可。level: レベル。整数型で、1〜99 の範囲に制約。NULLは不可。buff: バフ(能力補正係数)。全体3桁、小数部2桁の実数型。NULLは不可。- 具体的には
-9.99〜9.99が格納可能。
- 具体的には
guild: 所属ギルド名。最大 32 文字の可変長文字列型。last_login_at: 最終ログイン日時。日時型。- 標準 SQL において、年・月・日と時刻 (時・分・秒) を格納するデータ型を TIMESTAMP型 といいます。
- PostgreSQL では、さらに タイムゾーン情報 も格納する
TIMESTAMPTZ型 も存在します。
TIMESTAMPTZは、標準 SQL のTIMESTAMP WITH TIME ZONEの別名 (エイリアス) となっています。
created_on: キャラクタ作成日。日付型 (時刻情報を含まない)。- 標準 SQL において、時刻を含まず「年月日」を格納するデータ型を DATE型 といいます。
http://localhost:8080/もしくはhttp://127.0.0.1:8080/から「DbGateコンテナ」にアクセスして、s_characters テーブルの内容を確認してみてください。
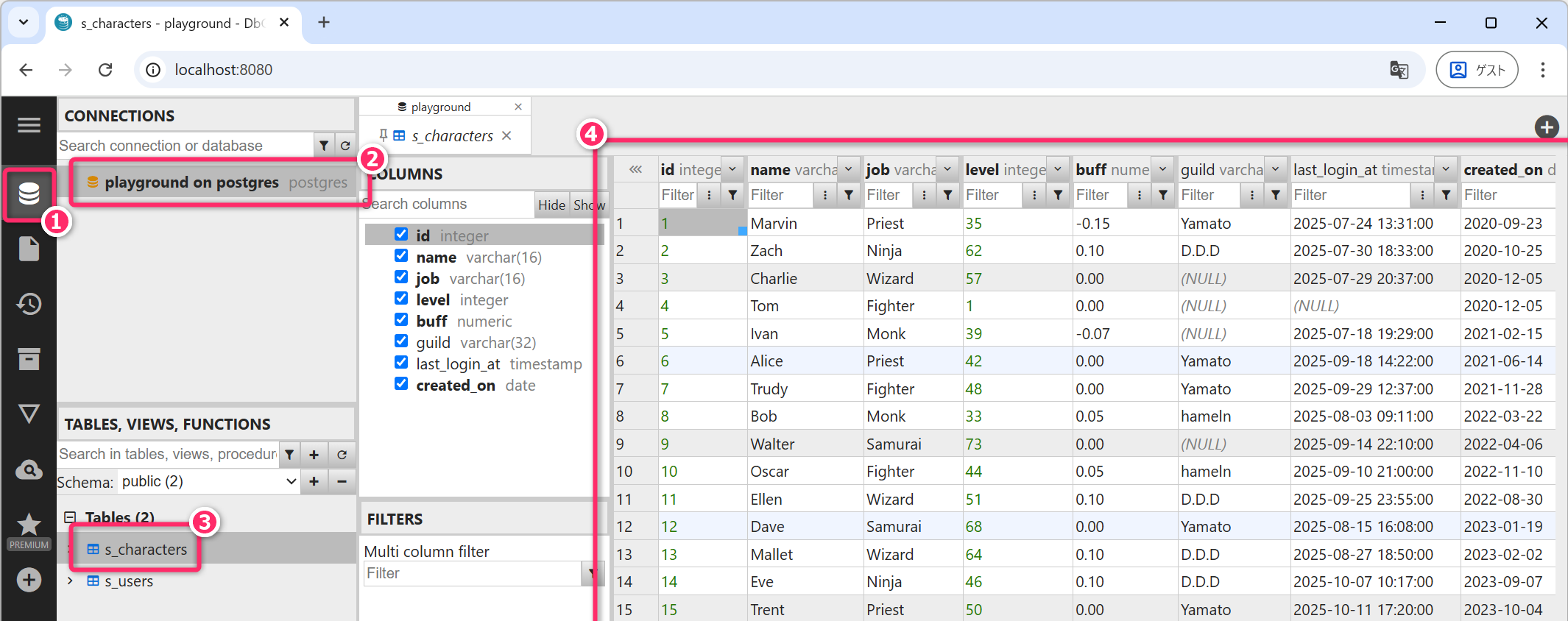
(プロンプト例)
PostgreSQL の
psqlで SQL を実行したところ、CREATE TABLE、INSERT 0 19のようなレスポンスが返ってきました。これらの意味を解説してください。
7.1.1 定着確認
- 標準 SQL において、タイムゾーン情報を含まず日付 (年・月・日) と時刻 (時・分・秒)
を格納するデータ型を答えよ。大文字で答えること。
- 答え: TIMESTAMP。TIMESTAMP WITHOUT TIME ZONE でも可。
- 標準 SQL
において、時刻を含まず、「年月日」を格納するデータ型を答えよ。大文字で答えること。
- 答え: DATE
- 標準 SQL
において、格納可能な最大文字数が決められた可変長文字列型を答えよ。大文字で答えること。
- 答え: VARCHAR
7.2 SELECT文
テーブルから任意のレコード (行) を取り出す操作を、RDB では 選択
(Selection) を呼びます。また、任意のカラム (列) だけを取り出す操作を
射影 (Projection) と呼びます。これらの操作は
SQL (=Structured Query Language) では SELECT
キーワードによって指示します。
第1稿で、上記の「選択」を、誤って「抽出」と書いていました。訂正します。
s_characters テーブルに格納されたすべての情報 (すべてのレコードとカラム)
を取得するには、次のような SELECT 文 (SQLクエリ) を使用します。
この SELECT 文
は、次のように「改行」や「インデント」で整形して記述することもできます。
sql/03/tmp.sqlを作成し、上記のコードを貼り付け、実際に実行してみてください。
本科目の演習環境では、拡張機能SQL Formatter VSCodeにより、ファイル保存時に改行形式に自動整形されます。
7.2.1 定着確認
- テーブルから必要なレコード (行) を取り出す操作を何というか。漢字2文字で答えよ。
- 答え: 選択。英語では Selection。※第1稿では誤って「抽出」としていましたが、「選択」が正しいです。
- テーブルから必要なカラム (列) を取り出す操作を何というか。漢字2文字で答えよ。
- 答え: 射影。英語では Projection
- テーブルから必要なレコードを取得する際に使用する SQL の命令 (キーワード)
を答えよ。大文字のアルファベットで答えること。
- 答え: SELECT
7.3 任意のカラムのみを取得 (射影)
SELECT 文では、テーブルに含まれるカラムのうち「どのカラムを取り出すか
(射影するかSELECT
文により)」を明示的に指定することができます。これは、先ほど *
を書いていた位置に
カンマで区切って「カラム名」を並べることで可能になります。
例えば、id と name と guild
の3つのカラムについてのみレコードを取得したいときには、次のような SELECT 文
(SQLクエリ) を使用します。
また、次のように 同じカラムを2回以上指定 したり、表示順を自由に指定したりすることも可能です。
なお、SELECT name, job, FROM s_characters; のように、最後のカラム名のあとにカンマを付けてしまうと、構文エラー
(Syntax Error) となるので注意してください。
7.3.1 SQLドリル💻
ex-01_1.sql👉 s_characters テーブルのすべてのレコードについてid、name、level、created_onを取得する SQL 文を記述し、実行せよ。なお、問題文に示した順番でカラムが並ぶようにすること。ex-01_2.sql👉 s_characters テーブルのすべてのレコードについてid、last_login_at、created_on,idを取得する SQL 文を記述し、実行せよ。なお、問題文に示した順番でカラムが並ぶようにすること。
SQLドリル💻は、プロジェクトのなかに sql/03/drill/ex-01_1.sql
のようなファイルを作成して取り組むことを推奨します。解答例 (参考) は from-teacher
フォルダのなかに配置しています。
- SQLドリルについては、文法や構文を体で覚える観点から、GitHub Copilot のコード補完を切って、コピペも避けて SQL を手入力することを推奨します。
7.4 カラムに別名 (エイリアス) をつける
次のように SELECT 句において、カラム名のあとに AS "xxxx"
をつけることで、そのカラムに別名 (エイリアス)
を付けることができます。この別名は クエリ結果として表示されるカラムのヘッダ (ラベル)
としても使用されます。
カラム名に記号やスペースが含まれない場合はダブルクォートを省略可能ですが、本科目 (小テストや試験を含む) のなかでは安全のため常にダブルクォートで囲むようにしてください。
実行結果 (上位5件のみ抜粋) は、次のようになります。
id | 名前 | 所属ギルド
----+---------+------------
1 | Marvin | Yamato
2 | Zach | D.D.D
3 | Charlie |
4 | Tom |
5 | Ivan |ASにつづく文字列を ダブルクォート ではなく シングルクォート で囲んで実行した場合、どのようになるかを確認してください。
7.4.1 SQLドリル💻
ex-02_1.sql👉 s_characters テーブルのすべてのレコードについてid、name、level、jobを取得する SQL 文を記述し、実行せよ。なお、カラムは問題文に示した順序で並ぶようにし、それぞれのカラムのヘッダ (ラベル) が「ID」「名前」「レベル」「ジョブ」となるようにせよ。ex-02_2.sql👉 s_users テーブルのすべてのレコードについてid、name、ageを取得する SQL 文を記述し、実行せよ。なお、カラムは問題文に示した順序で並ぶようにし、それぞれのカラムのヘッダ (ラベル) が「出席番号」「名前」「年齢」となるようにせよ。
7.5 SQLの文法上の注意
SQL では、-- を使って コメント
を記述します。また、/* */ で囲んで複数行のコメントアウトができます。VSCode
では [Ctrl]+[/]
のショートカットでコメントの設定と解除ができます。
SQL では、1つの文の終わりを示すためにセミコロン ;
使用します。実行環境によってはセミコロンを省略できることもありますが、本科目の小テストや試験のなかでは、必ずセミコロンをつけるようにしてください
(セミコロン抜けは誤答や減点とします)。
PostgreSQL において SELECT や FROM
などの「キーワード」は 大文字と小文字を区別しません。また、テーブル名やカラム名などの「識別子
(例えば s_characters や id
など)」も大文字と小文字を区別しません。
- ただし、識別子はダブルクォート
"で囲んだ場合のみ、大文字と小文字が「区別される」ので注意してください。
SQLの「文」と「句」について
次のような SQL
があるとき、これ全体を「SELECT文」と言います。また、文を構成している
SELECT id, name, age
の部分を「SELECT句」といい、FROM s_users
の部分を「FROM句」といいます。
同様に、次のような SQL があるとき、全体を「INSERT文」と言います。また
INSERT INTO s_users (id, name, age) を「INSERT
INTO句」といい、VALUES (1, 'Alice', 20), (2, 'Bob', 25)
を「VALUES句」といいます。
7.5.1 定着確認
いま、s_users というテーブルに
id、name、age というカラムが存在している。
- このとき
select id, name form s_users;という SQL は「構文エラーになる」か「構文エラーにならない」かを答えよ。- 答え: 構文エラーになる。
formではなくfromが正しい。</span>
- 答え: 構文エラーになる。
- このとき
select id, name, age, from s_users;という SQL は「構文エラーになる」か「構文エラーにならない」かを答えよ。- 答え: 構文エラーになる。
ageのあとのカンマが不要。
- 答え: 構文エラーになる。
- このとき
select NAME, AGE, ID from S_users;という SQL は「構文エラーになる」か「構文エラーにならない」かを答えよ。- 答え: 構文エラーにならない。テーブル名やカラム名などの「識別子」は大文字と小文字を区別しない。
- このとき
SELECT "name", "age" FROM "s_users";という SQL は「構文エラーになる」か「構文エラーにならない」かを答えよ。- 答え: 構文エラーにならない。
- このとき
SELECT "Name", age FROM s_users;という SQL は「構文エラーになる」か「構文エラーにならない」かを答えよ。- 答え: 構文エラーになる。識別子をダブルクォートで囲むと大文字と小文字が区別される。
- このとき
SELECT 'name', 'age' FROM s_users;という SQL は「構文エラーになる」か「構文エラーにならない」かを答えよ。- 答え: 構文エラーにならない。ただし
SELECT name, age FROM s_users;とは大きく結果が変わってくるので注意すること。後述の定数値カラムの扱いになる。
- 答え: 構文エラーにならない。ただし
- このとき
SELECT * FROM 's_users';という SQL は「構文エラーになる」か「構文エラーにならない」かを答えよ。- 答え: 構文エラーになる。
いずれのケースも、実際に SQL を実行して結果を確認してみてください (=どのようなエラーメッセージが表表示されるのか把握しておいてください)。
7.6 定数値カラムを付加する
SELECT
文では、実際のテーブルには存在しない「定数値」をカラムとして追加して出力することもできます。
このとき、定数値として「文字列」を使うときは
シングルクォート ' で囲んでください。一方で、AS
によるカラムのエイリアス指定では ダブルクォート "
を用いる点も注意してください。
SELECT
8 AS "RegionID", -- 定数値のカラム
'Zipangu' AS "World", -- 定数値のカラム
id AS "ID",
name AS "名前"
FROM
s_characters;実際に実行して結果を確認してください。
注意
SELECT句 において…
- シングルクォートで囲んだ
'Zipangu'は、文字列リテラル (固定値) を表します。- 「Zipangu」という「文字列そのもの」を意味します。
- ダブルクォートで囲んだ
"Zipangu"は 識別子 (カラム名やテーブル名など) を表します。- 「Zipangu」という名前の「カラム」を意味します。
7.6.1 SQLドリル💻
ex-03_1.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなチェックリストを出力する SQL を記述せよ。
id | name | level | buff | 不正行為の疑い?
----+---------+-------+-------+-------------------
1 | Marvin | 35 | -0.15 | 要調査 / 問題なし
2 | Zach | 62 | 0.10 | 要調査 / 問題なし
3 | Charlie | 57 | 0.00 | 要調査 / 問題なし
4 | Tom | 1 | 0.00 | 要調査 / 問題なし
5 | Ivan | 39 | -0.07 | 要調査 / 問題なし
~~ 以下略 ~~ex-03_2.sql👉 s_users テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。- age カラムの出力 (
XX歳) には、次のセクションで解説する「文字列の結合」を使用する必要があります。
- age カラムの出力 (
grade | course | name | age
-------+--------+-------+------
4 | M | Alice | 20歳
4 | M | Bob | 25歳7.7 カラム値に文字列演算と算術演算を適用する
次に示すように、SELECT 句では ||
演算子を使用して「文字列の結合
(連結)」ができます。これにより、複数のカラム値や文字列リテラルを組み合わせて、ひとつの文字列として出力することができます。
実行結果 (上位5件のみ抜粋) は、次のようになります。
Name(Job) | Level
------------------+-------
Marvin (Priest) | Lv.35
Zach (Ninja) | Lv.62
Charlie (Wizard) | Lv.57
Tom (Fighter) | Lv.1
Ivan (Monk) | Lv.39また、数値型のカラムについては基本的な算術演算も可能です。
SELECT
id AS "ID",
name AS "Name",
buff AS "Buff",
(buff + 1) * 100 || '%' AS "BuffApplied(%)"
FROM
s_characters;実行結果 (上位5件のみ抜粋) は、次のようになります。
ID | Name | Buff | BuffApplied(%)
----+---------+-------+----------------
1 | Marvin | -0.15 | 85.00%
2 | Zach | 0.10 | 110.00%
3 | Charlie | 0.00 | 100.00%
4 | Tom | 0.00 | 100.00%
5 | Ivan | -0.07 | 93.00%ROUND()
関数を使えば、桁数を指定しての四捨五入ができます。例えば、BuffApplied(%)
を「整数値%」で出力したい場合は、次のようにします。
SELECT
id AS "ID",
name AS "Name",
ROUND((buff + 1) * 100, 0) || '%' AS "BuffApplied(%)"
FROM
s_characters;その他、切り上げ CEIL()、切り捨て FLOOR()
などの関数が利用できます。詳しくは、PostgreSQL の公式ドキュメント (リファレンス)
を参照してください。
7.7.1 SQLドリル💻
ex_04-1.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。
id | summary
----+------------------------
1 | Marvin (Priest Lv.35)
2 | Zach (Ninja Lv.62)
3 | Charlie (Wizard Lv.57)
4 | Tom (Fighter Lv.1)
5 | Ivan (Monk Lv.39)
~~ 以下略 ~~ex_04-2.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。ただし、Boosted Level は level を「1.2倍」にして切り上げた値とすること。
id | Level | Boosted Level
----+-------+---------------
1 | 35 | 42
2 | 62 | 75
3 | 57 | 69
4 | 1 | 2
5 | 39 | 477.7.2 定着確認
- products というテーブルに value
という数値型のカラムがある。このカラムの値を
小数第3位で四捨五入して、小数第2位までを取得する
SELECT文として、以下のSQLを完成させたい。【 X 】に記述すべき語を答えよ。- 答え:
ROUND(value, 2)
- 答え:
7.8 CASE式を利用する
SELECT 句では「CASE式」というものを利用して 条件に応じて異なる値を出力すること
ができます。この「CASE式」は SELECT 句に限らず、SQL
のなかで条件分岐を実現するための強力な仕組みで、実務でも頻繁に利用されています。
SELECT
id,
name,
level,
CASE
WHEN level >= 80 THEN 'SS'
WHEN level >= 60 THEN 'S'
WHEN level >= 40 THEN 'A'
ELSE 'B'
END AS "class"
FROM
s_characters;実行結果 (上位5件のみ抜粋) は、次のようになります。
id | name | level | class
----+---------+-------+-------
1 | Marvin | 35 | B
2 | Zach | 62 | S
3 | Charlie | 57 | A
4 | Tom | 1 | B
5 | Ivan | 39 | BWHEN 句の「評価式」では 値の等価比較 に ==
ではなく =
使用する点に注意してください。一般的なプログラミング言語とは異なり、SQL では =
が「等しい」を意味します。一方で「等しくない」ことを判定したいとき、PostgreSQL では
!= または <> が使用できます (標準SQLでは <>
が正式な記法とされています)。また、評価式では AND や OR
を利用することができます。
なお、「値が NULL
かどうか」を評価するためには、以下のように IS NULL を使用します
(ISNULLも可)。guild = NULL
のように評価することはできないので十分に注意してください。
SELECT
id,
name,
CASE
WHEN guild IS NULL THEN '(無所属)' -- NULL判定には IS NULL を使用
ELSE guild
END AS "guild"
FROM
s_characters;実行結果 (上位5件のみ抜粋) は、次のようになります。
id | name | guild
----+---------+----------
1 | Marvin | Yamato
2 | Zach | D.D.D
3 | Charlie | (無所属)
4 | Tom | (無所属)
5 | Ivan | (無所属)7.8.1 SQLドリル💻
ex-05_1.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、battle_position は job が「Fighter」「Samurai」「Monk」「Ninja」のときに「frontline」、それ以外のときに「backline」となるようにすること。
id | name | job | battle_position
----+---------+---------+-----------------
1 | Marvin | Priest | backline
2 | Zach | Ninja | frontline
3 | Charlie | Wizard | backline
4 | Tom | Fighter | frontline
5 | Ivan | Monk | frontline
~~ 以下略 ~~ex-05_2.sql👉 s_characters テーブルのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、status は buff が、0.0 のときは「–」、負数の場合は「debuff」、正数の場合は「buff」となるようにすること。
id | name | buff | status
----+---------+-------+--------
1 | Marvin | -0.15 | debuff
2 | Zach | 0.10 | buff
3 | Charlie | 0.00 | --
4 | Tom | 0.00 | --
5 | Ivan | -0.07 | debuff
~~ 以下略 ~~ex-05_3.sql👉 s_characters テーブルのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、class は以下の条件により決定すること。Master: level が「50」以上、かつ、created_on が「2022/12/31」以前Veteran:Masterの条件を満たさず、level が「30」以上、かつ、created_on が「2023/12/31」以前Rookie:Masterの条件も、Veteranの条件も満たさない
id | name | level | created_on | class
----+---------+-------+------------+---------
1 | Marvin | 35 | 2020-09-23 | Veteran
2 | Zach | 62 | 2020-10-25 | Master
3 | Charlie | 57 | 2020-12-05 | Master
4 | Tom | 1 | 2020-12-05 | Rookie
5 | Ivan | 39 | 2021-02-15 | Veteran
~~ 以下略 ~~7.9 NULLを別の値に変換する
前のセクションで説明したように「CASE式」を利用して NULL
を任意の値に置き換えることができました。これと同じ処理は COALESCE (コアレス)
という関数でシンプルに行なうことができます。
COALESCE は 引数のなかから、最初に見つかった
NULL ではない値を返す関数
となります。引数を左から順に評価し、NULL
ではない値が見つかった時点で、それを結果として返します。
たとえば、次のように書くと、guild の値が NULL の場合にだけ
(無所属) が表示されるようになります。
実行結果 (上位5件のみ抜粋) は、次のようになります。
id | name | guild | 所属
----+---------+--------+----------
1 | Marvin | Yamato | Yamato
2 | Zach | D.D.D | D.D.D
3 | Charlie | | (無所属)
4 | Tom | | (無所属)
5 | Ivan | | (無所属)7.9.1 SQLドリル💻
ex-06_1.sql👉 s_characters テーブルのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、guild or (name) の値は、次の条件に従って決定すること。CASE式は使用せず、COALESCE関数を用いること。- guild が
NULLでない場合は、その値 (guild) を表示する。 - guild が
NULLの場合は、name を括弧で囲んで表示する。
- guild が
id | name | guild | guild or (name)
----+---------+--------+---------------
1 | Marvin | Yamato | Yamato
2 | Zach | D.D.D | D.D.D
3 | Charlie | | (Charlie)
4 | Tom | | (Tom)
5 | Ivan | | (Ivan)
~~ 以下略 ~~7.10 レコードの重複を省く
次の SQL を実行すると、s_characters テーブルのすべてのレコードの
job カラムの値を取得することができます。
具体的な実行結果は、次のようになります。
job
---------
Priest
Ninja
Wizard
Fighter
Monk
Priest
Fighter
Monk
Samurai
Fighter
Wizard
Samurai
Wizard
Ninja
Priest
Samurai
Fighter
Priest
Wizard
(19 行)ここで、SELECT 句に DISTINCT (ディスティンクト)
キーワードを使うと 重複するレコードを省いて結果を取得すること
ができます。
この場合の実行結果は次のようになります。
job
---------
Samurai
Ninja
Wizard
Fighter
Monk
Priest
(6 行)7.10.1 SQLドリル💻
ex-07_1.sql👉 s_characters テーブルから、キャラクタが所属しているギルドの一覧を取得する SQL を記述せよ。なお、NULLは「未所属」として出力すること。
ギルド
--------
未所属
Yamato
hameln
D.D.Dex-07_2.sql👉 s_characters テーブルから、次のように各ギルドに所属しているジョブを重複を除いて取得する SQL を記述せよ。なお、ギルドがNULLのときは「未所属」として出力すること。
ギルド | ジョブ
--------+---------
未所属 | Wizard
D.D.D | Wizard
D.D.D | Ninja
hameln | Fighter
hameln | Monk
Yamato | Priest
hameln | Wizard
未所属 | Priest
D.D.D | Fighter
未所属 | Fighter
Yamato | Samurai
Yamato | Fighter
hameln | Samurai
未所属 | Monk
未所属 | Samurai
(15 行)7.11 日付・時刻関数を利用する (授業時間外学習)
TIMESTAMP型のデータから「年」「月」「日」「時」「分」「秒」を「数値」として得たいときは
DATE_PART 関数を使用します。
SELECT
name,
last_login_at,
DATE_PART('year', last_login_at) AS "year",
DATE_PART('month', last_login_at) AS "month",
DATE_PART('day', last_login_at) AS "day",
DATE_PART('hour', last_login_at) AS "hour",
DATE_PART('minute', last_login_at) AS "minute",
DATE_PART('second', last_login_at) AS "second"
FROM
s_characters;DATE_PART関数は、標準SQLに含まれない PostgreSQL 独自の関数です。DATE_PART関数は、DATE型のデータから「年」「月」「日」を取得する場合にも使用できます。
(プロンプト例)
標準SQLを使って、TIMESTAMP型のカラム (
last_login_at) から「年」「月」「日」「時」「分」「秒」を個別に数値として取得したいです。どのような SQL を書けばよいですか。
一方で、TIMESTAMP型のデータから「年」「月」「日」「時」「分」「秒」を「文字列」として得たいときは
TO_CHAR 関数を使用します。DATE型のデータについても使用することができます。
SELECT
name,
last_login_at,
TO_CHAR(last_login_at, 'YYYY"/"MM"/"DD HH24"時"MI"分"SS"秒"')
FROM
s_characters;上記の 第04行目 で使用している YYYY や MI
などの「フォーマット指定子」は、PostgreSQL の公式ドキュメント (リファレンス)
を参照してください。
なお、フォーマット指定子以外の文字 (書式内でそのまま出力したい文字列) は ダブルクォート で囲むようにしてください。そのまま記述しても正しく出力される場合もありますが、確実に意図どおり表示させるためにはダブルクォートで囲むことが推奨されます。
7.11.1 SQLドリル💻
ex-08_1.sql👉 s_characters テーブルのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、created_on は2020-09-01以降の日付であることを仮定してよい。- ヒント: 和暦 (令和) の年は、西暦の値から 2018 を引くことで求めることができる。
id | name | created_on_1 | created_on_2
----+---------+--------------+-----------------
1 | Marvin | 2020-09-23 | 令和2年09月23日
2 | Zach | 2020-10-25 | 令和2年10月25日
3 | Charlie | 2020-12-05 | 令和2年12月05日
4 | Tom | 2020-12-05 | 令和2年12月05日
5 | Ivan | 2021-02-15 | 令和3年02月15日
~~ 以下略 ~~7.11.2 定着確認
- あるテーブルに created_at という
TIMESTAMP型のカラムが存在する。このカラムの値を2025年10月16日のような書式の「文字列」として取得したい。PostgreSQL を想定し、SELECT句にどのような関数や式を用いればよいか答えよ。- 答え:
SELECTTO_CHAR(created_at, 'YYYY"年"MM"月"DD"日"')AS "created_at" FROM ...;
- 答え:
- あるテーブルに created_on という
DATE型のカラムが存在する。このカラムから「年」の値を「数値型」として取得したい。PostgreSQL を想定し、具体的にどのような関数や式を用いればよいか答えよ。- 答え:
DATE_PART('year', created_on)。なお、戻り値はDOUBLE PRECISION型 (実数) となるので、整数にしたい場合はDATE_PART('year', created_on)::INTのようにキャストします。
- 答え:
7.12 現在日時と日数・時間の差を計算する (授業時間外学習)
- 現在の日時を取得するには
LOCALTIMESTAMP(TIMESTAMP型) を使用します。CURRENT_TIMESTAMPを使用すると タイムゾーン情報付き の (TIMESTAMPTZ型) になるので注意してください。
- 現在の時刻を取得するには
LOCALTIME(TIME型) を使用します。CURRENT_TIMEを使用するとタイムゾーン情報付きの (TIMETZ型) になるので注意してください。
- 現在の日付 (時刻を含まない) を取得するには
CURRENT_DATE(DATE型) を使用します。CURRENT_DATEは、もともとタイムゾーン情報を含みません。
いま、s_characters の created_on
カラムは「タイムゾーン情報なしの DATE 型」、last_login_at
カラムは「タイムゾーン情報なしの TIMESTAMP
型」で型定義しています。そのため、s_characters に関して
現在の日時を基準に日時の差分を取りたい場合は LOCALTIMESTAMP
を、日付の差分を取りたい場合は CURRENT_DATE
を用いるのが安全です。
- テーブルのカラムが タイムゾーン情報付き型
である場合は、
CURRENT_TIMESTAMPやCURRENT_TIMEを使用するべきです。
datetime value function (日時値関数) について
LOCALTIMESTAMP、CURRENT_DATE、LOCALTIME は
datetime value function (日時値関数)
というもので、通常は、括弧を付けずに呼び出す特別な形式の関数式になります。括弧は
LOCALTIME(0) のように精度を指定する場合にのみ用いられ、LOCALTIME()
のように引数なしにすると PostgreSQLでは構文エラーになります。
タイムゾーン情報の扱いについて
タイムゾーン情報を「含める」か「含めない」かはシステム設計において非常に重要な判断になります。また、その影響は DB だけでなく、DB に接続するアプリケーションの設計や挙動にも直接関わります。たとえば、サーバとクライアントが異なる地域にある場合、DB 側でタイムゾーンを考慮しない設計をしてしまうと、アプリで表示される時刻が「数時間ずれる」といった問題が発生します。
LOCALTIMESTAMP と CURRENT_TIMESTAMP の違いなどは sql/03/tmp.sql
に、以下のコードを貼り付け、確認してみてください。
例えば、登録日 (created_on) から本日までの経過日数を得たいとき、以下の
第05行目 のように CURRENT_DATE を使用します。DATE
型同士の減算 (DATE - DATE) の結果は 整数型 (日数差)
となります。
また、最終ログイン (last_login_at)
から現在日時までの経過時間を得たいとき、以下の 第05行目 のように
LOCALTIMESTAMP を使用します。TIMESTAMP 同士の減算
(TIMESTAMP - TIMESTAMP) の結果は INTERVAL 型になります。
SELECT
id,
name,
last_login_at,
LOCALTIMESTAMP - last_login_at AS "Elapsed Time Since Last Login"
FROM
s_characters;INTERVAL 型は、DATE 型や TIMESTAMP
型と同様に、DATE_PART 関数や TO_CHAR
関数と組みあわせて利用することができます。
TIMESTAMP 型は、次のように DATE 型にキャスト (型変換)
することができます。
SELECT
id,
name,
last_login_at,
CAST(last_login_at AS DATE) AS "last_login_at(DATE型)"
FROM
s_characters;- PostgreSQL では
CAST(last_login_at AS DATE)をlast_login_at::DATEのように記述することができます (標準SQL構文ではない)。
なお、DATE 型や TIMESTAMP
型の値を直接指定したい場合は、CAST
関数を使って文字列から型を明示的に変換します。たとえば、DATE 型のリテラルは
CAST('2025-04-01' AS DATE)、TIMESTAMP 型のリテラルは
CAST('2025-04-01 13:05:59' AS TIMESTAMP) のように記述します。
7.12.1 SQLドリル💻
ex-09_1.sql👉 s_characters テーブルのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。ただし、最終ログイン は「2025年10月15日」を基準として計算すること。
id | name | last_login_at | 最終ログイン
----+---------+---------------------+--------------
1 | Marvin | 2025-07-24 13:31:00 | 83日前
2 | Zach | 2025-07-30 18:33:00 | 77日前
3 | Charlie | 2025-07-29 20:37:00 | 78日前
4 | Tom | |
5 | Ivan | 2025-07-18 19:29:00 | 89日前
~~ 以下略 ~~ex-09_2.sql👉 s_characters テーブルのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。ただし、Days Since Last Login は「2025年10月15日」を基準として計算し、Is Active User? は最終ログインから「50日以内か」で判断すること。
id | name | Last Login | Days Since Last Login | Is Active User?
----+---------+------------+-----------------------+-----------------
1 | Marvin | 2025-07-24 | 83 days ago | No
2 | Zach | 2025-07-30 | 77 days ago | No
3 | Charlie | 2025-07-29 | 78 days ago | No
4 | Tom | | | No
5 | Ivan | 2025-07-18 | 89 days ago | No
6 | Alice | 2025-09-18 | 27 days ago | Yes
7 | Trudy | 2025-09-29 | 16 days ago | Yes
~~ 以下略 ~~7.12.2 定着確認
- 標準 SQL において、現在の日時をタイムゾーン情報なしの
TIMESTAMP型の値として参照したい。どのような日時値関数を用いればよいか答えよ。- 答え:
LOCALTIMESTAMP
- 答え:
- 標準 SQL において、現在の日付を
DATE型の値として参照したい。どのような日時値関数を用いればよいか答えよ。- 答え:
CURRENT_DATE
- 答え:
8 授業時間外学習の指示 (宿題)
🚨本科目は「学修単位科目」であり、1回の講義あたり「4時間相当」の授業時間外学習が求められる科目です🏃
- 次回の講義で「小テスト❸」を実施します。
- 定着確認 および SQLドリル から主に出題します。
- 講義が進行するにつれて、当然ながら小テストの内容も複雑で高度なものになっていきます。前半で、しっかりと得点をとるようにしてください。
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。
- 講義資料内の「演習」や「SQLドリル」に再度取り組んでください。特に、SQLドリル💻 は、授業時間中に1回取り組むだけでは定着しないので注意してください。