1 ガイダンス
1.1 概要
本科目では、「リレーショナルデータベース」について、その概念から保守運用に至るまでを体系的に学んでいきます。具体的には、環境構築 (Docker での PostgreSQL コンテナ構築)、設計 (概念設計・論理設計)、操作 (Raw SQL/ORM)、保守運用 について、ハンズオン形式で (=実際に手を動かしながら) 学んでいきます。また、「ドキュメント指向データベース」についても、基本概念や環境構築、操作などの概要を学んでいきます。
- リレーショナルデータについては PostgreSQL
を使用します。
- Programming3 で利用した Supabase も PostgreSQL を基盤としています。
- ドキュメント指向データベースについては MongoDB を使用します。
具体的には、次のような「知識・理解」および「実践的スキル」を習得することを目指していきます。
- データの永続化や管理における データベースマネジメントシステム (DBMS) の位置付けと、その導入効果を説明できる。
- 主要なデータベースモデル(リレーショナル/ドキュメント指向など)の特性を理解し、要件に応じた適切な選択ができる。
- Docker を使用して PostgreSQL の実行環境を構築し、コンソール や DbGate (ウェブベースのデータベースクライアント) から接続して、SQL や ユーティリティコマンド を実行できる。
- 現実世界の要件を分析し、ER図を用いた概念設計ができる。
- リレーショナルモデルについて、正規化や外部キー制約制約、インデックス設計などの論理設計ができる。
- SQL を用いてリレーショナルデータベースに対する各種クエリが実行できる。
- TypeScriptからpg(DBドライバ) や、Prisma・Drizzle(ORM) による PostgreSQL の利用ができる。
- PostgreSQL のユーティリティを用いて、データベースのバックアップ/リストア、実行計画の表示などができる。
- Docker を使用して MongoDB の実行環境を構築ができる。
- TypeScript から MongoDB に接続して基本的な CRUD 操作ができる。
1.2 授業の位置づけ
この授業は、次のような位置付けになります。
1.2.1 基本情報
- 学年・学科: 4年 総合工学システム学科 知能情報コース の基盤専門科目
- 単位数: 2単位 (後期・学修単位)
- 卒業要件との対応: DP-D
- 自己の基盤となる専門分野について実践的な知識と技術を修得し、工学的諸問題に適用する能力
- 担当教員: Takeshi Wada (知能情報コース)
学修単位
本科目は「プログラミング3」や「アルゴリズムとデータ構造2」と同じく「学修単位」の科目であり「30時間 (相当) の対面授業」と「60時間 (相当) の授業時間外学習」を前提とした内容 (ボリュームと学習難易度) の科目となります。
授業については 毎週90分 を実施し、これを2時間と見なして全15回の講義によって「30時間相当の対面授業」を確保しています。これに加えて、皆さんには授業1回につき、授業時間外に 4時間相当の自主的な学習 (復習や演習、発展的探求) が求められています。
1.2.2 関連科目
2年 前期 (学修単位)「情報2」 - 教科書「キタミ式 ITパスポート」の「Chapter7 データベース」pp.160-191。
- 第10回と第11回の講義で「リレーショナルデータベースの基礎」について学習済み。
- 教科書「キタミ式 ITパスポート」の「Chapter7 データベース」pp.160-191。
- 情報2 第10回/第11回の講義資料PDF(学内のみ)
- SQLite3 を使用した SQL の基礎演習 (テーブルの作成、レコードの挿入、SELECT、正規化、結合)。
- 第10回と第11回の講義で「リレーショナルデータベースの基礎」について学習済み。
2年 通年 (履修単位)「プログラミング1」(Python)
3年 後期 (学修単位)「プログラミング3」(TypeScript/Next.js/Supabase)
- ウェブアプリのデータの永続化
- Prisma (TypeSCript ORM) + Supabse (PostgreSQL)
3年 後期「知能情報実験実習1」
- サーバ構築 (Linux, Apache)、Docker
4年 前期「知能情報実験実習2」
- SQLAlchemy (Python ORM) + SqLite3
- Prisma (TypeSCript ORM) + SqLite3
以上のように、これまで皆さんは様々な科目を通して多くの知識や技術を学んできました。しかし、それらを独立した「点」と「点」で持っているままでは、卒業研究や仕事の場で求められる実力にはなりません。自分自身で能動的かつ探求的に「点」と「点」を結びつけ、「線」や「面」に広げてこそ、はじめて本当の価値が生まれます。他の人が持っていない「線」や「面」を築けるかどうかが、自分の強み (=自分にしかできないこと) となっていきます。
本科目の受講においても、これまでに培ってきた知識や技術と、新たに学ぶ内容を「どのように結びつけることができるのか?」 を強く意識し、取り組んでください。
この他、データベース (特にリレーショナルデータベース) は「ITパスポート試験」「基本情報技術者試験」「応用情報技術者試験」などの資格試験でも重要分野となっています。
これらはいずれも国家資格です。実践的な開発力とは直結しないものの 就職活動を含めたIT業界におけるキャリア形成 では一定の意義を持つので取得をお勧めします。
1.2.3 教科書と参考書
- 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」は、授業および授業時間外学習で適宜使用します。
- 参考書
1.3 成績評価法と履修上の注意
総合成績(年度末の最終成績)は、シラバス記載のように「試験45%、小テスト35%、課題20%の割合で総合して評価」します。
- 小テストおよび課題は、主として「授業時間外学習の取り組み」を評価するものとなります。
- 小テスト実施するときは、その前回講義でアナウンスします。
各種事情で小テストを受験できなかったときは
遅刻や欠席(公欠や出欠停止を含む)により、授業中に実施する「小テスト」を受験できず追試験を希望するときは、当該授業日を含めて2日以内に、自分から担当教員宛に Teams Chat で「追試験の実施依頼」を申し出てください。例えば、10月9日 (木) 実施の小テストの追受験を希望する場合は、遅くとも 10日 (金) 23:59 までに連絡してください。
- 小テストの追試験は、公欠や出席停止を含めて理由に関わらず「1人あたり最大3回まで」対応します。
- 電子メールや口頭など、Teams Chat 以外による依頼には対応しません。
- 実施依頼には、具体的な希望の日時 (平日 08:40-19:00 を原則) を3案ほど添えてください。
- 「放課後」や「先生の空いている時間」のような抽象表現は使用しないでください。
1.3.1 履修上の注意点
- 毎回、十分に充電したノートPCを持参してください。
- 授業や課題の取り組みにおいて、生成AIの利用に制限はありませんが、これらは「理解を深めるため」「知識の幅を広げるため」に利用してください。「正答を得るため」や「自分では記述できないクエリ
(SQL) を書かせるため」に利用することは推奨しません。
- 推奨する利用方法は、講義資料のなかに (プロンプト例) として示しています。
- ウェブの技術記事やYouTube動画、生成AIを活用し、授業で扱った内容に関する補足的な知識や、最近の技術動向についてキャッチアップに努めてください。
2 データベースとは
データベース (Database) とは、データ (data) と ベース (base) を合わせた複合語になります。データは「記録された情報」や「観測事実」を意味し、ベースは「基盤」「置き場」「土台」を意味します。また、ベースは軍事用語として 「基地」や「補給拠点」 といった意味合いも持っています。このことから、データベースはもともと「情報の基盤」や「知識やデータの倉庫」のような比喩的イメージを持つ言葉となっています。
非情報分野において、一般的に「データベース」という言葉は 「一定の形式や構造に従って整理されたデータの集まり」 を指します。その意味では、電話帳や国語辞典、出席簿といったアナログ資料もデータベースとみなせますし、CSV や JSON などのデジタルファイルもデータベースと呼ぶことができます。
しかし、コンピュータサイエンスやソフトウェア開発の分野では CSV や JSON のような単なるデータファイル を「データベース」と呼ぶことは通常ありません。これらの分野でデータベースという言葉は「一定の形式や構造に従ってデータを蓄積・管理し、必要に応じて検索・更新・削除・集計・加工などを柔軟かつ高速に行える仕組み」を指すことが一般的です。ただし、文脈によっては、データそのものを「データベース (DB)」と呼び、それらを管理する仕組みやソフトウェアを「データベースマネジメントシステム (DBMS)」と区別して呼ぶこともあります。
まとめると、以下のようになります。
- CSV や JSON、Excel などのファイルや、それらの集まりをデータベースとは言わない。
- 単なる CSV の読み書き処理を「データベースから情報を取得して」のように表現すると大きな誤解を与えるので十分に注意すること。
- データの蓄積・管理、柔軟な操作を可能にする仕組みやソフトウェアのことを「データベース」あるいは「データベースマネジメントシステム」と呼ぶ。
- データベースマネジメントシステムには、ユーザごとのアクセス制御、ネットワーク経由での利用、データ整合性の維持、障害時復旧といった機能が標準的に備わっている。
- データベース管理システムと呼ぶこともある。
- データベースは「DB」、データベースマネジメントシステムは「DBMS」という略語で使用される。
- DB について「デービー」という読み方も比較的広く使われている。
実際の開発現場における「データベース」という言葉の使われ方
ややこしいですが、ソフトウェア開発の文脈で「データベース」という用語が使われる場合、以下のように「データそのもの」ではなく、それを「管理・利用する仕組みやソフトウェアを含めた全体」を指すことが一般的です。
- 「この機能では、ユーザーの行動ログをデータベースに保存する必要がありますね」
- 「データベースのスキーマ設計はどうしますか?正規化は第3正規形まででよいでしょうか」
- 「データベースの応答が遅くなっています💦クエリのパフォーマンスを確認してください」
- 「データベースの容量が90%を超えました。ディスク拡張が必要です」
- 「来週末にデータベースのバージョンアップを予定しています」
- 「データベースのセキュリティパッチを適用する必要があります」
- 「性能要件:データベースの応答時間は平均100ms以下であること」
- 「データベースの冗長化により、システムの可用性を99.9%以上確保できます」
このあたりの使い分けは、本科目を学んでいくうちに自然につかめるようになると思います。
2.0.1 定着確認
- DBMS とは何の略語か英語で答えよ。
- 答え: Database Management System
- 次の説明は「適切である」か「適切ではない」か答えよ。
- 答え: 適切ではない
ソフトウェア開発やコンピュータサイエンスの分野では、一般に CSVファイル や JSONファイル などのデータファイルの集合を「データベース」という。
- DBMSが標準的に備えている機能として「適切ではないもの」はどれか。該当するものを全て答えよ。
- ❶ ユーザーごとのアクセス制御
- ❷ ネットワーク経由での利用
- ❸ データ整合性の維持
- ❹ プログラムの自動作成
- ❺ 障害時復旧
- ❻ ウイルス対策
- 答え: ❹❻
- 一般に「DBMSとは言えないもの」はどれか。該当するものを全て答えよ。
- ❶ SQLite3
- ❷ PostgreSQL
- ❸ Oracle Database
- ❹ Microsoft Excel
- ❺ Microsoft Access
- ❻ SQLAlchemy
- ➐ Pandas
- ❽ Prisma
- 答え: ❹❻➐❽
- 開発現場において「データベースのバージョンアップ」という表現が指しているものはどれか。最も適切なものを答えよ。
- ❶ データを最新情報に更新すること
- ❷ DBMSソフトウェアを新しいバージョンに更新すること
- ❸ ファイル形式を変更すること
- ❹ データの量を増やすこと
- 答え: ❷
3 なぜ、DBMS が利用されるのか?
現在、企業の基幹システム (会計システム、人事システム、販売管理システムなど)や、ECサイトなどのウェブサービスのような「複数のユーザやプログラムによって共有・利用されるシステム」においては、ほぼ例外なく DBMS が利用されています。
ここでは「なぜ、データ管理に、OSのファイルシステムではなく、DBMSが使われているのか?」について整理していきます。視点を変えれば、CSVやJSONなどのデータファイルを用いたデータ管理には、どんな制約や問題、リスクがあるのか? について考えていきます。
3.1 データの永続化
一般にプログラムでは「ユーザが入力した情報」や「システムが動的に生成した情報 (=例えば 「最終ログイン日時」や「一時的な計算結果」 など)」は、変数 (メモリ) に保持されますが、これらはプログラムの実行終了とともに失われてしまいます。
プログラムの終了後も、これらの情報 (上記の例で言えば name の値)
を保持して、プログラムを再び起動したときに引き続き利用できるようにするためには「データの永続化」という仕組みが必要となります。
3.2 OSのファイルシステムを直接利用したデータの永続化の問題
最も基本的な「データの永続化」の方法は、OSのファイルシステムを利用して テキストファイル (TXT、CSV、JSONなど) や バイナリファイル にデータ (情報) を書き出し、必要に応じて読み出すというものです。
例えば、Python では標準ライブラリの csv や、外部ライブラリの
Pandas
で「CSVファイルの読み書き」ができるので、それを利用してデータの永続化が可能です。また、標準ライブラリの
json を用いれば JSONファイルの読み書きができ、pickle を用いれば
Pythonオブジェクトを「バイナリ形式」で保存・復元できるので、これらも永続化の手段となります。
- 参考:PG1-第18回講義
- 参考:PG1-第25回講義
このように「OSのファイルシステムを直接利用したデータの永続化」は、比較的実装が容易で、プログラムに組み込みやすく便利な方法です。ただし、この方法には様々な問題や制約があり、実際には、限定的なケースでのみ安全かつ効率的な手法となります。
以下では、CSV や JSON などのデータファイルを使ったデータ管理で起き得る問題や制約、それにともなう「リスク」について探っていきます。
3.2.1 定着確認
- JSON とは何の略語か英語で答えよ。
- 答え: JavaScript Object Notation
- CSV とは何の略語か英語で答えよ。
- 答え: Comma Separated Values
3.3 汎用性や拡張性に関する問題や制約
当該のデータファイル (例えば 学生情報.csv など)
が、単一のアプリだけで利用される場合、その汎用性や拡張性に関する問題はあまり大きなものとはなりません。しかし、将来的な利用も含めて複数のアプリでデータファイルを「共用」する場合には、様々な制約や問題が起きてきます。
一般に、複数のアプリからの利用を前提にしつつ、将来の拡張や汎用性、さらには読み書きのパフォーマンスまで考慮した「データファイル (フォーマットやスキーマ)」および「その入出力処理 (I/O処理)」を 設計・実装することは非常に難しく大変な作業 となります。
例えば、「アプリA」に関する要件としてデータファイルに新しい情報を追加しなければならない場合、そのデータファイルを共用する「アプリB」や「アプリC」、さらには 将来的に開発されるであろう「アプリD」に対する影響まで考慮して対応する必要 があります。これらを想定して、十分な汎用性と拡張性を持ったデータファイルの設計と、そのI/O処理の実装は非常に難しいものとなります。
- 具体例:「成績管理.exe」「出席管理.exe」「授業料支払管理.exe」で「学生情報.csv」を共通利用しているとします。このとき「成績管理.exe」の都合で「期末試験 (追試験) の成績」という列を単純に追加すると、「出席管理.exe」や「授業料支払管理.exe」でのパフォーマンスの悪化や、形式変更による予期せぬエラーが発生する可能性があります。
(プロンプト例)
データファイル設計における「フォーマット」と「スキーマ」の違いについて解説してください。
3.3.1 定着確認
- I/O とは何の略語か英語で答えよ。
- 答え: Input/Output
3.4 同時アクセスと排他制御に関する問題や制約
当該データファイルが、単一のアプリかつ単一ユーザから利用される前提で、さらにアプリの多重起動が想定されないとき、そのアプリが正しくファイルを扱っていれば「更新競合」や「データの不整合(論理的な矛盾)」が生じることはありません。
しかし、複数のアプリや複数のユーザでデータファイルを共用し、同時アクセスして読み書きができる場合では、それらの問題が現実的に発生し、システムの信頼性に深刻な影響を与えることになります。
具体例として、次のようなデータファイル 学生情報.csv を考えてみます。
学籍番号,氏名,住所,...,DB工学の成績,...
X002,構文 誤次郎,整合市破綻町1-1,...,70,...
X003,仕様 曖昧子,無効市矛盾町9-9,...,65,...
X004,保守 絶望太,排他市待機村7-5,...,80,...このとき、この 学生情報.csv
を共用している「授業料支払管理.exe
(教員A👩🦰が使用)」と「成績管理.exe
(教員B👨が使用)」で、次のような操作・処理が実行されたとします。
- 〔11時39分〕 教員A👩🦰が「授業料支払管理.exe」を起動
(アプリは
学生情報.csvの内容をメモリに読み込む)。教員A👩🦰は、アプリ画面上で構文 誤次郎の 住所 を整合市破綻町1-1から正規市ヌル町9-1-1に変更。ここで電話があって、作業を一時中断。- アプリ画面上のテキストボックスで値を変更しただけで、まだ保存の確定処理はしていない。
- 〔11時40分〕 教員B👨が「成績管理.exe」を起動 (アプリは
学生情報.csvの内容をメモリに読み込む)。教員B👨は、仕様 曖昧子の DB工学の成績 を65から55に変更。さらに「確定」ボタンを押下。- 成績管理.exe は、メモリの内容を
学生情報.csvに書き出す。
- 成績管理.exe は、メモリの内容を
- 〔11時45分〕
教員A👩🦰が電話対応を終えて、アプリ画面で「確定」ボタンを押下。
- 授業料支払管理.exe は、メモリの内容を
学生情報.csvに書き出す。
- 授業料支払管理.exe は、メモリの内容を
この結果、最終的にデータファイル 学生情報.csv は次のような内容になります。
学籍番号,氏名,住所,...,DB工学の成績,...
X002,構文 誤次郎,正規市ヌル町9-1-1,...,70,...
X003,仕様 曖昧子,無効市矛盾町9-9,...,65,...
X004,保守 絶望太,排他市待機村7-5,...,80,...ここでは、教員B👨による成績変更 (65👉55)
が消失するという深刻な問題が生じています。これは 更新競合 (Lost
Update)
と呼ばれ、ファイルの共用でデータ管理したときに起き得る典型的なリスクとして知られています。
このような問題の回避のために、通常、OS のファイルシステムには 排他制御 (Shared Lock や Exclusive Lock) という仕組みが用意されています。この仕組みを利用すれば、任意のファイルを一度に操作できるアプリ (プロセス) を1つに限定し、更新競合を防ぐこと ができます。
しかし、OS
のファイルシステムによるロックは基本的には「ファイル単位」で働きます。そのため「教員A👩🦰」が
学生情報.csv にロックをかけると、それが解除されるまでは、他の教員やアプリ
(成績管理.exe や 出席管理.exe など) からは
学生情報.csv
が更新できなくなり、システムの実用性を大きく損なうことになってしまいます。
- 教員A👩🦰が、ロックをかけたまま昼休みに入ってしまったりすると、業務に大きな影響がでてしまいます。
バイト単位のファイルロック
Windows や Linux、MacOS などの OS では、ファイル単位に加えて バイト単位のファイルロック機能 も提供しています。こちらを利用すれば、ファイル内の特定範囲にロックをかけることが可能となります。しかし、その利用には以下のような大きな制約や難しさがあります。
- OS依存性の問題: 各 OS で異なるAPI (Windows:
LockFileEx、Linux/macOS:fcntlのF_SETLKなど) を使用する必要があり、クロスプラットフォーム開発が困難になります。 - 動的変化への対応不可: CSVファイルでデータの挿入・削除が発生すると、すべてのバイト位置が変化してしまいます。例えば、ファイル先頭に1行挿入しただけで、後続のすべてのロック範囲が無効になってしまいます。
- 実装の複雑性: バイト位置の計算、ロック範囲の管理、例外処理など、極めて高度で複雑な処理が要求されます。さらに、文字エンコーディング (UTF-8、Shift_JIS等) によってバイト数が変わるため、正確な位置計算がより困難になります。
- パフォーマンスの劣化: 細かなロック管理により、ファイル操作のオーバーヘッドが大幅に増加し、システム全体のパフォーマンスが低下します。
以上のような理由から、実際のアプリ開発において「バイト単位のファイルロック」が採用されることはほとんどありません。
(プロンプト例)
OSのファイルシステムにおける「排他制御」とは、どのような機能ですか。
OSのファイルシステムの「Shared Lock」と「Exclusive Lock」の違いについて教えてください。
Windows 環境の Python でテキストファイルに対する排他制御 (排他ロック) をしたいです。どのようにすればよいですか。
3.4.1 定着確認
- サーバの設定ファイルに対して「管理者X」が編集を加えて保存した。その後、同じ設定ファイルを古い状態のまま開いていた「管理者Y」が編集して保存した結果、「管理者X」が追加した内容が反映されずに消失してしまった。この現象を何と呼ぶか答えよ。
- 答え: 更新競合 (Lost Update)
3.5 セキュリティとアクセス制御に関する問題や制約
OS のファイルシステムを直接利用したデータ管理において、アクセス権 (パーミッション) の設定は「ファイル」や「フォルダ」という単位でしか設定することができません。
たとえば、ユーザが「成績処理.exe」を通じて 学生情報.csv
を操作可能なとき、そのユーザは同じ権限でテキストエディタやExcelから 学生情報.csv
を編集したり、ファイルごと削除したりすることが可能になります。逆に、テキストエディタで編集できないように
学生情報.csv
にアクセス制限をかけると、そのユーザの権限で起動した「成績処理.exe」からもファイルに書込みができなくなってしまいます。また、Windows、Linux、macOS
など一般的な OS
では、ファイル内部の特定の範囲だけにアクセス権を設定する仕組みは用意されていないので、部分的な読み取りや、書き込み制限をすることもできません。
このように、ファイルシステムを直接利用したデータ管理には、セキュリティやアクセス制御で大きな制約が生じます。
- 具体例:
「論理回路2」の授業担当である「教員C👨🦳」は、本来「論理回路2の成績」の列のみに書き込み権限を持つべきです。しかし、ファイルシステムでは
学生情報.csv全体に対する読み書き権限を与えるしかありません。仮に「成績管理.exe」で「論理回路2の成績だけ編集可能」のような制限を実装しても、その制御はアプリを通した場合にしか有効ではありません。「教員C👨🦳」がテキストエディタで直接学生情報.csvを開いてしまえば、他の科目の成績を改ざんすることも (技術的には) できてしまいます。
(プロンプト例)
Windowsのファイルシステム (NTFS) で設定可能なパーミッションについて教えてください。
Linuxのファイルシステムで設定可能なパーミッションについて教えてください。
3.6 ネットワーク経由のアクセスに関する問題や制約
CSV や JSON などのデータファイルを 共有フォルダ や NAS (Network Attached Storage)、クラウドストレージなどに配置することで、複数のユーザや端末からネットワーク経由でデータファイルを共用することができます。しかし、既に述べたように、更新競合が発生するリスクはそのまま残り、また、ファイルシステムのアクセス権限の設定は依然として「ファイル単位」となるため、ユーザごとに「ファイルのなかの特定の範囲だけを編集可」といった細かい制御はできません。
無論、データファイルへのアクセスを自前のサーバアプリで受け付ける仕組みを構築すれば、より細かいセキュリティ制御や排他制御を実現することはできます。しかし、その場合、認証や通信暗号化、ログ監査なども含めてセキュリティを意識したシステムの設計と実装が必要となり、現実的ではありません。
ファイルを分割しても解決しない問題
ファイルによるデータ管理において、細かな粒度で排他制御やアクセス権の設定を行いたい場合、データを複数のファイルに分割して保存する という戦略があります。例えば、科目ごとにファイルを分けて「2025年度のDB工学の成績.json」「2025年度の論理回路2の成績.json」といった形で管理する、といったやり方です。このようにすれば、影響範囲を最小に留めたロックや、細かなアクセス権の設定が可能になります。
しかし、この戦略をとった場合、検索や集計の際には複数ファイルを横断して読み込み処理が必要があり、パフォーマンスが著しく低下するという欠点があります。一般に「1KBのファイルを1000個読み込む場合」と「1MBのファイルを1個読み込む場合」を比較すると、前者の方が圧倒的に負荷が高く、処理に大きな時間がかかるようになります。
(プロンプト例)
一般なOSのファイルシステムでは「1KBのファイルを1000個読み込む場合」と「1MBのファイルを1個読み込む場合」では、前者の方が圧倒的に負荷が高く時間を要しますが、これは何故ですか。また、例外 (逆転するケース) はありますか?
3.7 データサイズやパフォーマンスに関する問題や制約
ファイルシステムを直接利用したデータ管理では、データサイズが大きくなるにつれて深刻な制約に直面します。一般に、ファイル編集をする場合、アプリでは、ファイル全体をメモリに読み込む必要があり、この際、ファイルが巨大であればあるほど、読み込み処理に時間とリソース (主にメモリ) を消費します。さらに、更新処理を行う際も基本的にファイル全体を書き戻す必要があり、処理時間が長くなるだけでなく、同時利用時の競合リスクも高まります。
無論、ファイルの途中位置に部分的な読み書きを行うことは理論上可能ですが、そのようなバイトオフセットを扱う実装は複雑であり、データファイルの構造に応じてアプリごとに独自の仕組みを設計・実装する必要があります。また、巨大なファイルのなかから特定のデータを高速に検索するには、インデックスやキャッシュといった仕組みが必要ですが、これを自前で実装することは現実的ではありません。
(プロンプト例)
ファイルI/Oにおける「バイトオフセット」とは何ですか。
「大きなデータファイルのから特定のデータを高速に検索するためには、インデックスやキャッシュといった仕組みが必要」と聞きました。「インデックス」と「キャッシュ」の基本的な仕組みを教えてください。
以上のような理由から (その他にも様々な理由から) 複数のユーザや複数のアプリから、同時にデータを読み書きするようなシステム において、CSV や JSON などのデータファイルを共用してデータ管理することは、現実的ではないという結論となります。
もちろん、高度な設計と実装技術を駆使すれば、これらの問題を解決することは可能です。ただし、そのような高度なデータ管理の仕組みを具現化したものこそが「DBMS」であり、通常のシステム開発において、それを自前で開発することはありません。
ここでに示した問題や制約は DBMS を導入し、それを適切に利用することで大部分を解決することができます。
4 DBMS を利用したデータ管理の概要
「OSのファイルシステムを直接利用したデータ管理」と「DBMSを使ったデータ管理」の違いについて整理しておきます。
4.1 OSのファイルシステムを直接利用したデータ管理
- アプリは、OSのファイルシステムAPI や
そのラッパーライブラリ
を使用して、CSV、JSON、バイナリなどのファイルを直接的に読み書きすることで「データの永続化」を実現します。
- ファイルの読み書き処理は、アプリ内部に組込み可能で外部サーバなどを必要としません。
- アプリの設計にあわせて最適化した任意のデータ構造・スキーマ・ファイル形式でデータを永続化できる柔軟性があります。
- 検索処理の最適化、データ整合性の保証、複数ユーザーの同時アクセスに対する排他制御は、すべてアプリの責務として実装する必要があります。
プロンプト例
ラッパーライブラリとは何ですか。
4.2 DBMS を使ったデータ管理
- PostgreSQL や MySQL のような DBMS を使用する場合、アプリとは別に
独立したDBMSサーバを構築して起動しておく必要 があります。
- DBMSサーバは、アプリと同一のホスト上でも、ネットワーク (TCP/IP) 接続された別ホストに配置しても問題ありません。
- SQLite のような組み込み型の DBMS ではサーバを立てる必要はありません。
- アプリは、DBMSクライアントライブラリ
を使用して、データモデルに応じた形式でデータを操作します。
- 特にリレーショナルモデルの DBMS (RDBMS) では、SQL (Structured Query Language) という標準化された言語を使用してデータの検索・挿入・更新・削除を行います。
- 検索処理の最適化、データ整合性の保証、複数ユーザーの同時アクセスに対する排他制御は、DBMS側で提供されます。
- DBMSは、その内部のストレージエンジン (ストレージマネージャ) により、最終的にはOSのファイルシステムを利用してデータを物理的に保存 します。
- ただし、アプリ開発者は、この低レベルのファイル操作を意識する必要はなく、DBMS が提供する抽象化されたインターフェイスを通じてデータを扱うことができます。
プロンプト例
PostgreSQL や MySQL のような DMBS は、TCP/IP で別ホストに配置したクライアントから接続できると聞きました。アプリケーション層では、どのようなプロトコルを使うのですか。
リレーショナルデータベースにおける「データ整合性の保証」とは、どのようなものですか。具体例で解説してください。
4.2.1 定着確認
- データベースに関する文脈で SQL とは何の略語か英語で答えよ。
- 答え: Structured Query Language
- 次の説明は「適切である」か「適切ではない」か答えよ。
- 答え: 適切である
PostgreSQL のような DBMS は、ネットワーク経由 (TCP/IP) で接続可能な別ホストに配置することもできる。
- 次の説明は「適切である」か「適切ではない」か答えよ。
- 答え: 適切である
DBMSサーバへの接続には、DBMSクライアントライブラリまたは専用のクライアントアプリを使用する。
- 次の説明は「適切である」か「適切ではない」か答えよ。
- 答え: 適切ではない
DBMS (サーバのストレージエンジン) は、OSのファイルシステムを利用することなくデータの永続化を実現している。
5 データベースの種類
データベースのアーキテクチャ (内部の仕組み/データの整理方法) は、大きく「RDB (リレーショナルデータベース)」と「NoSQL (ノーエスキューエル)」の2つに分けることができます。本科目では、DBの代表的モデルであり、大規模システムの基盤技術として広く利用される RDB (PostgreSQL) について約8割の時間をかけて学び、その後、約2割の時間を使って NoSQL の1種である ドキュメント指向データベース (MongoDB) について学んでいきます。
- 各種データベースモデルについては「📖 教科書
pp.6-11」を読んでおいてください。
- リレーショナルデータベース (RDB)
- オブジェクト指向データベース
- 「オブジェクトデータベース」とも呼ばれます。
- XMLデータベース
- キーバリュー型ストア (KVS)
- Next.js などのモダンな Web アプリ開発では、状態管理・状態共有に Redis(レディス)などの KVS が使われることがあります。本科目では取り扱いませんが、興味のある学生はぜひ調べてみてください。
- ドキュメント指向データベース
- 「ドキュメント型データベース」とも呼ばれます。
- 階層型データベース
なお、本科目では、リレーショナルデータベースとして PostgreSQL を使用しますが、PostgreSQL は、リレーショナルモデルに基づくだけはなく オブジェクト指向データベース的な特徴や機能 も備えています。実際、PostgreSQLの公式ドキュメントのなかでも object-relational database system (ORDBMS) と説明されています。
- PostgreSQL では「可変長配列型」や「JSON型」をスキーマの一部として定義し、直接的に扱うことができます。これらは単に文字列としてシリアライズして保存されているのではなく、効率的な検索や更新を行えるような形式でフィールドに保存されます。
(プロンプト例)
Redis とはなんですか?Next.js などのウェブアプリにおいて、状態管理・状態共有 に使われることがあると聞いたのですが、どのように利用するのかイメージがつきません。
6 リレーショナルデータベース (RDB)
RDB (Relational Database、リレーショナルデータベース、関係データベース) は シンプルな「2次元の表形式」でデータを保持することが特徴の DB です。近年では SNSなどのウェブアプリやオンラインゲーム などを中心に NoSQL の普及も進んでいますが、単に「DB」と言えば RDB を指すほど一般的かつ代表的なモデルであり、特に「基幹システム」や「ECサイト」などで広く採用されています。
表形式 (テーブル形式) によるデータ管理には多数のメリットがあるものの「可変長配列」や「階層構造のデータ」を直接的に扱えない という欠点があります (でも、PostgreSQL では扱えます)。
- RDB の DBMS を、特に「RDBMS (Relational Database Management System)」といいます。
PostgreSQL や MySQL などの主要な RDBMS (サーバ) に対しては、公式のものからサードパーティ製まで様々なクライアントツールから接続することができます。また、各種プログラム (TypeScript、Python、Java、C/C++、C# など) においても専用の ドライバ や ORM (Object Relational Mapper) を使って、RDBMS に接続して利用することができます。
- PostgreSQL の公式のクライアントツール: psql
- MySQL の公式のクライアントツール: mysql
- Oracle Database の公式のクライアントツール: SQL*Plus
- DbGate(Postgres、MySQL、SQLite などに対応したウェブベースのクライアントツール)
(プロンプト例)
ソフトウェア開発の文脈において「基幹システム」とはどのようなソフトウェアを指しますか。学生でもイメージできるように教えてください。
RDBMS のクライアントツールとは何ですか?RDBMSサーバとはどのように役割が違うのですか。「PostgreSQL」と「psql」の違いを教えてください。
6.1 RDBの基礎
(このセクションは「情報2」の第10回講義の増補版です)
リレーショナルデータベース (RDB: Relational Database) とは Excel のような 表形式 でデータを管理するデータベースモデルです。「RDB」と略されほか、「関係データベース」とも呼ばれたりします。特に「ITパスポート試験」や「基本情報技術者試験」では 関係データベース という呼称が使われます。
RDBでは、Excel
のシートに相当するものを「テーブル(Table)」と呼びます。また、「列」を「カラム
(Column)」や「属性 (Attribute)」、行を「レコード
(Record)」や「タプル
(Tuple)」のように呼びます。カラムには「名前」「誕生日」「残業時間」などの項目が設定され、レコードにはそれぞれの項目に対応する具体的な値
(例えば
1,'高負荷 耐子','1985-06-21', 65, 1、2,'不具合 直志','1990-11-02', 48, 1
など) が入ります。
以下は社員情報を管理するためのテーブル群の例です。
■ employees (社員) テーブル
| id | name | birthday | overtime | department_id |
|---|---|---|---|---|
| 1 | 高負荷 耐子 | 1985-06-21 | 65 | 1 |
| 2 | 不具合 直志 | 1990-11-02 | 48 | 1 |
| 3 | 品質 守 | 1978-03-14 | 5 | 2 |
| 4 | 構文 誤次郎 | 1995-07-30 | 85 | 3 |
| 5 | 仕様 曖昧子 | 1988-09-09 | 72 | 3 |
| 6 | 保守 絶望太 | 1982-12-25 | 120 | 3 |
| 7 | 負債 雪崩美 | 1975-04-05 | 58 | 4 |
■ departments (部署) テーブル
| id | name |
|---|---|
| 1 | 再起動対策本部 |
| 2 | 曖昧戦略部 |
| 3 | バグ発生推進部 |
| 4 | 予算消失部 |
| 5 | 机上片付け指導部 |
- データベースのテーブル名は、一般的に スネークケース (snake_case) で記述され、テーブルが複数の行を持つことから 複数形 で命名されることが多いです。
RDBの重要な機能のひとつに「JOIN (結合)」というものがあります。JOIN を使うと、複数のテーブルを関連付けて、あたかも1つのテーブルのように扱うことができます。
例えば、上記の employees テーブルには department_id
という「部署を示す番号だけ」が記録されていますが、JOIN を使うことで
departments
テーブルから「部署名」を引っ張ってきて、「社員情報」と「部署情報」を結合した表にすることができます。具体的には
employees.department_id と departments.id
を紐付けて結合し、以下のテーブルのようにすることができます。
■ employees と departments を 部署ID を使って結合
| id | name | birthday | overtime | department_id | department_name |
|---|---|---|---|---|---|
| 1 | 高負荷 耐子 | 1985-06-21 | 65 | 1 | 再起動対策本部 |
| 2 | 不具合 直志 | 1990-11-02 | 48 | 1 | 再起動対策本部 |
| 3 | 品質 守 | 1978-03-14 | 5 | 2 | 曖昧戦略部 |
| 4 | 構文 誤次郎 | 1995-07-30 | 85 | 3 | バグ発生推進部 |
| 5 | 仕様 曖昧子 | 1988-09-09 | 72 | 3 | バグ発生推進部 |
| 6 | 保守 絶望太 | 1982-12-25 | 120 | 3 | バグ発生推進部 |
| 7 | 負債 雪崩美 | 1975-04-05 | 58 | 4 | 予算消失部 |
このように、データを複数のテーブルに分けて管理し、必要に応じて JOIN で結合することで 効率的なデータ管理 を実現することができます。もし、全ての情報を1つのテーブルにまとめて管理すると、「部署名」のような共通情報が社員の数だけ重複してしまうことになります。例えば、バグ発生推進部に50人が所属していれば「バグ発生推進部」という文字列を50個保持することになります。これは容量の無駄になるだけではなく、部署名を変更したいときに50箇所すべてを修正しなければならず、ミスや修正漏れの原因にもなり得ます。
一方で、上記のようにテーブルを分けて管理すれば、部署名の変更は departments テーブルの1レコードを修正するだけで済み、データの不整合を防ぐことができます。また 現時点において所属する社員がいない「机上片付け指導部」という情報 も自然な形で保持できるメリットもあります。
なお、RDBMS では SQL という言語を使って、データベースのデータに対する「検索」「取得」「挿入」「更新」「削除」などの一連の操作指示 (=これを クエリ (Query) と呼びます) を出せることが特徴となっています。次週以降、しばらくは SQL を使ったクエリについて学んでいきます。
6.1.1 定着確認
- RDBMS に対するクエリを記述するために使用される言語をアルファベット3文字で答えよ。
- 答え: SQL
- RDB において、一般にテーブル(表)の「列」を指す語をカタカナで答えよ。
- 答え: カラム、フィールド、アトリビュート (属性)
- RDB において、一般にテーブル(表)の「行」を指す語をカタカナで答えよ。
- 答え: レコード、タプル
6.2 演習
オンライン SQL 実行環境であるDB Fiddleというサービスを利用して、SQL を使って RDBMS (PostgreSQL) を操作する体験をしてみたいと思います。
- SQL の詳細については、今後の授業の内容なので、現時点で詳細に理解する必要はありません。
サイトにアクセスして、Database として「PostgreSQL 17」を選択してください。PostgreSQL は、毎年9~10月頃に新しいメジャーバージョンがリリースされていて、v17 は 2024年9月26日 (約1年前) にリリースされています。
まずは、社員と部署に関するテーブルのスキーマを定義し、そこにデータを挿入
(INSERT) していきたいと思います。こちら(👈init-table.sql)
から SQL をコピーして、以下のように Schema SQL のペイン (領域)
に貼り付けてください。
Schema SQL ペインで [Ctrl]+[Enter]
を押下すると実際にコードが実行されます。成功すると、Results ペイン に
There are no results to be displayed. のように表示されます。失敗する場合は
Daatabase
が「PostgreSQL」になっていることを確認してください。「MySQL」や「SQLite」になっていると失敗します。
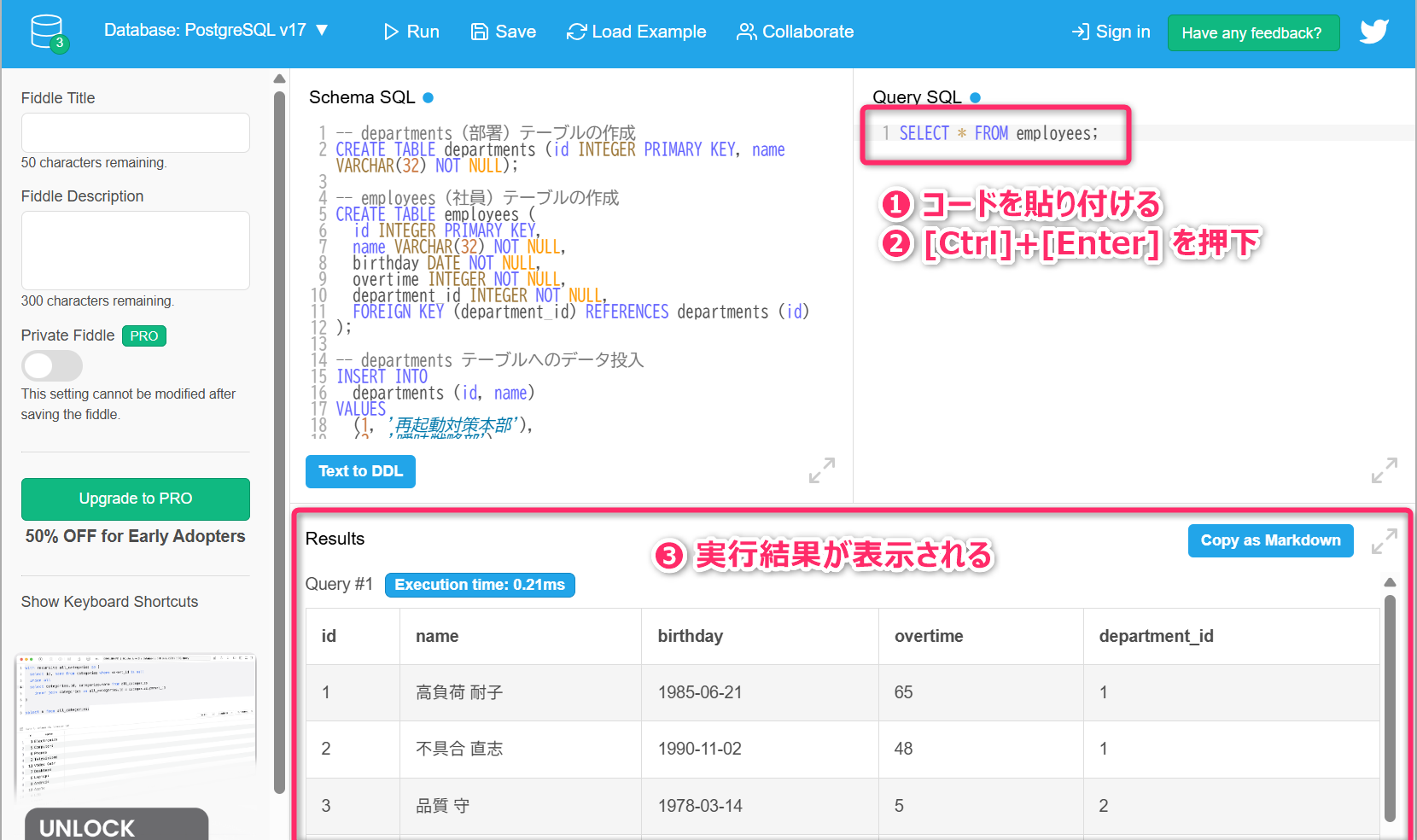
次に、employees テーブルから全てのレコードを取得してみます。以下のように
Query SQL に SELECT * FROM employees;
を貼付けて、[Ctrl]+[Enter] を押下してください。Results
のペインに結果が表示されるはずです。
- SQL文の最後にはセミコロン
;が必要です。記述忘れに注意してください。
以下、いくつかのSQLの例を示します。実際に Query SQL ペインに貼り付け、実行
([Ctrl]+[Enter]) して意図するような結果が得られることを確認してください。
6.2.1 WHERE句 と ORDER BY句の使用例
コードをじっくりと読み解けば、トライ&エラーで以下の演習に取り組めると思います。腕試しで挑戦してみてください。
- 演習:
birthdayという列 (カラム) を出力するようにしてみましょう。 - 演習: 残業時間が「80時間以上」の社員だけを出力するようにしてみましょう。
- 演習: 残業時間の昇順に全社員を出力するようにしてみましょう。ヒント:
ASC
6.2.2 JOIN (内部結合) の使用例
RDBの重要な機能のひとつである「JOIN (結合)」の例です。実際にクエリ (SQL) を発行して、どのような結果が返ってくるかを確認してみてください。
SELECT
e.id,
e.name,
e.birthday,
e.overtime,
e.department_id,
d.name AS "department_name"
FROM
employees AS e
JOIN departments AS d ON e.department_id = d.id;- 演習: 実行結果として表示されるテーブルの
nameという列 (カラム) のヘッダを名前に変えてみましょう。- ヒント: 第07行目を参考に
6.2.3 GROUP BY句 と JOIN (外部結合) と集計関数の使用例
いまの時点で、SQLの構文について理解する必要はありません。大事なのは「SQLでこんな集計できちゃうんだ🤔」とイメージを掴むことです。ただし、ちょっとでも読解しようとする姿勢と行動は実力アップにつながります (また、Python や TypeScript プログラムで同様の処理を実装するなら・・・を考えてみるとおもしろいかもしれません)。
SELECT
d.id AS "部署ID",
d.name AS "部署名",
COUNT(e.id) AS "人数",
COALESCE(SUM(e.overtime), 0) AS "総残業時間",
ROUND(COALESCE(AVG(e.overtime), 0), 1) AS "平均残業時間"
FROM
departments AS d
LEFT JOIN employees AS e ON d.id = e.department_id
GROUP BY
d.id,
d.name
ORDER BY
d.id;💻実行結果
| 部署ID | 部署名 | 人数 | 総残業時間 | 平均残業時間 |
|---|---|---|---|---|
| 1 | 再起動対策本部 | 2 | 113 | 56.5 |
| 2 | 曖昧戦略部 | 1 | 5 | 5.0 |
| 3 | バグ発生推進部 | 3 | 277 | 92.3 |
| 4 | 予算消失部 | 1 | 58 | 58.0 |
| 5 | 机上片付け指導部 | 0 | 0 | 0.0 |
6.2.4 CASEの使用例
以下は、脱・初心者レベルのクエリになります。授業を重ねながら、このレベルのクエリも自分の手で書けるように力をつけていきましょう。
SELECT
d.id AS "部署ID",
CASE
WHEN GROUPING(d.id) = 1 THEN '(全体)'
ELSE MAX(d.name)
END AS "部署名",
SUM(
CASE
WHEN birthday BETWEEN '1970-01-01' AND '1979-12-31' THEN 1
ELSE 0
END
) AS "1970年代",
SUM(
CASE
WHEN birthday BETWEEN '1980-01-01' AND '1989-12-31' THEN 1
ELSE 0
END
) AS "1980年代",
SUM(
CASE
WHEN birthday BETWEEN '1990-01-01' AND '1999-12-31' THEN 1
ELSE 0
END
) AS "1990年代"
FROM
departments AS d
LEFT JOIN employees AS e ON d.id = e.department_id
GROUP BY
ROLLUP (d.id)
ORDER BY
d.id;💻実行結果
| 部署ID | 部署名 | 1970年代 | 1980年代 | 1990年代 |
|---|---|---|---|---|
| 1 | 再起動対策本部 | 0 | 1 | 1 |
| 2 | 曖昧戦略部 | 1 | 0 | 0 |
| 3 | バグ発生推進部 | 0 | 2 | 1 |
| 4 | 予算消失部 | 1 | 0 | 0 |
| 5 | 机上片付け指導部 | 0 | 0 | 0 |
| (全体) | 2 | 3 | 2 |
6.3 主要なRDBMS
代表的な RDBMS として PostgreSQL、MySQL、MariaDB、Oracle Database、Microsoft SQL Server、SQLite、Microsoft Access などが挙げられます。
この授業では PostgreSQL を使用していきます。
6.3.1 PostgreSQL👑
- オープンソースのクライアント・サーバー型RDBMS。高機能で拡張性に優れ、標準 SQL への準拠度も高い。学術や業務システムで広く利用されている。無償。
- JSON/JSONB型のネイティブサポート、フルテキスト検索 (全文検索) 、地理空間データ (PostGIS) など、先進的な機能が豊富。Instagram などの大規模サービスで採用されている。
- トランザクションの堅牢性が高く、複雑なクエリやデータ整合性が重要なシステムに適している。
近年のモダンなウェブアプリ開発やスタートアップでの採用が増加傾向にあり、PostgreSQL のスキルは市場価値が高まっています。標準 SQL に準拠しているため、他の RDBMS への応用も効きやすいこともメリットです。AWS RDS、Google Cloud SQL、Azure Database for PostgreSQL など主要クラウドで完全サポートされている点でも、選択する価値が高いと思います。
(プロンプト例)
「PostgreSQL は JSON/JSONB型をネイティブサポートしている」と聞きました。これはどういうことですか。
「PostgreSQL は 標準SQLへの準拠度が高い」と聞きました。これはどういうことですか。
6.3.2 MySQL
- オープンソースのクライアント・サーバー型RDBMS。ウェブアプリの利用が多い。例えば、WordPress は PHP + MySQL の組み合わせで動作する設計。基本は無償だが、商用サポート付きの有償版もある。
- 読み取り性能が高く、レプリケーション設定が比較的容易。Facebook、Twitter (X)、YouTube
など世界最大級のウェブサービスで使われてきた実績がある。
- YouTube については、現在はMySQLベースではないことが公表されている。
- LAMP スタック (Linux, Apache, MySQL, PHP) の一部として Web
開発の定番となっている。多くのレンタルサーバーで標準提供されている。
- 「M」は MySQL / MariaDB、「P」は PHP / Perl / Python という構成もある。
ウェブ系企業での求人が最も多いです。また、初学者向けの学習リソースが豊富で、最初に学ぶ RDBMS として選ばれやすいです。MySQL 8.0 からは機能が大幅に強化され、JSON サポートやウィンドウ関数なども追加されています。
(プロンプト例)
ウェブアプリ開発の文脈において「LAMPスタック」とは何ですか。
6.3.3 MariaDB
- MySQL から派生したオープンソースのクライアント・サーバー型RDBMS。MySQL との互換性を持ちながら、コミュニティ主体で開発が続けられている。無償。
- MySQL の開発者が Oracle による買収後に立ち上げたプロジェクト。Wikipedia、Google(一部システム)などで採用。
- MySQL からの移行が比較的容易で、最新機能の追加ペースが速い。多くの Linux ディストリビューションで MySQL の代わりに標準パッケージとして採用されている。
6.3.4 Oracle Database
- 商用のクライアント・サーバー型RDBMS。大規模システム向けで豊富な機能を持ち、金融・企業システムで定番。有償。
- エンタープライズレベルの可用性、パフォーマンス、セキュリティ機能を提供。RAC(Real Application Clusters)による高可用性構成が可能。
- PL/SQL による強力なストアドプロシージャ機能を持つ。大規模トランザクション処理や基幹システムで圧倒的なシェアを誇る。
6.3.5 Microsoft SQL Server
- 商用のクライアント・サーバー型RDBMS。Windows サーバー環境でよく利用される。有償だが、無償の簡易版 (Express Edition) も提供されている。
- .NET エコシステムとの親和性が高く、C#/ASP.NET での開発に最適。Azure SQL Database としてクラウドでも利用可能。
- 近年は Linux 対応も進み、Docker コンテナでも動作。Visual Studio との統合による優れた開発体験を提供。
6.3.6 SQLite👑
- 組み込み型RDBMS。データベースが 1 ファイルで完結する軽量 DBMS。スマホアプリやブラウザ (例: Chrome, Firefox) にも組み込まれている。オープンソースで無償。
- サーバープロセス不要で、ライブラリとしてアプリケーションに直接組み込める。iOS/Android アプリ開発での標準的なローカルストレージ。
- テスト環境やプロトタイピング、小規模アプリに最適。世界で最も広く使われているデータベースエンジンと言える (数十億以上のSQLiteデータベースがデプロイされていると推定される)。
モバイルアプリ開発者なら必須スキルになります。Python(標準ライブラリ)、Node.js、React Native などほぼ全ての開発環境で簡単に使えるようにライブラリが整備されています。ローカル開発環境でのテストやプロトタイプ作成に便利なため「とりあえず動くものをつくる」ときに役立ちます。
6.3.7 Microsoft Access
- デスクトップ(パーソナル)向けのスタンドアロン型 RDBMS。GUI による簡便な操作性が特徴。Office 製品の一部として提供されるため有償。
- コーディング不要でフォームやレポートを作成可能。VBA によるカスタマイズにも対応。
- 小規模な業務アプリやデータ管理ツールとして、非エンジニアでも扱いやすい。ただし、同時接続数やデータ量に制限があるため、本格的なウェブアプリには不向き。
6.3.8 定着確認
- LAMPスタックの「L」「A」「M」「P」は、それぞれ、何を意味しているか答えよ
(最も代表的なものを答えること)。
- 答え: Linux、Apache、MySQL、PHP
7 PostgreSQL の 環境構築 (準備)
RDB (主にSQL演習) のハンズオン学習では PostgreSQL (ポストグレエスキューエル、ポストグレス、ポスグレ) を使用していきます。PostgreSQL は Windows に直接インストールすることもできますが、本科目では「Docker」という仕組みを用いて、PostgreSQL を「コンテナ」と呼ばれる仮想的な箱の中で起動し、その箱ごと利用します。Docker を利用すれば、既存の PC 環境を汚さずに PostgreSQL を構築でき、万一破損しても簡単に再構築できます。また、DbGateという「ウェブベースの DBMS クライアント」もコンテナとして利用していきます。
PostgreSQL コンテナのセットアップは次回の講義で行います。今回は、その前段階として Docker(Docker Desktop)のインストールと動作確認までを行います。なお、既に Docker Desktop をインストール済みの場合は再インストールの必要はありません。ただし、最新バージョン (2025年10月1日現在の最新バージョンは 4.47.0 ) にアップデートしておくことを推奨します。
なお、Docker は、Git/GitHub とあわせてソフトウェア開発の現場では標準的に使われる技術になっています。既に3年生の後期の「知能情報実験実習1」のなかで Docker は学んでいると思いますが、日常的な開発でも積極的に利用して慣れておいてください。Git/GitHubと同じで 習うよりも慣れろ という技術になります。
(プロンプト例)
Docker は、ソフトウェア開発の現場で標準的に使われる技術だと聞きました。本当ですか。また、Docker ってどのような技術なのか教えてください。どうやら、授業で「PostgreSQLのコンテナ」を使うそうです。
7.1 Docker Desktop のインストール
「Docker Desktop」は、Windows や Mac などの環境で Docker を利用できるようにする公式アプリです。「Docker」は コンテナを動かすための仕組みそのもの で、もともと Linux 向けに設計・開発されたもので、「Docker Desktop」は、それを Windows や Mac で簡単に使えるようにする仕組みと GUI を提供するアプリという位置づけになります。
「Docker Desktop」をインストールすると、自動的に Docker もインストールされ、Windows で Docker を利用するための準備が整います。Windows 環境で Docker Desktop をインストールする方法はウェブに多数の情報があるので、それを参考にインストールしてください。
- DockerDesktop
インストール Windows@ Google検索
- 比較的に新しい情報を参照するようにしてください。
- Windows で Docker を動かすには「Hyper-V」を利用する方法と、「WSL2」を利用する方法があります。基本的に「WSL2」を利用する方法でインストールと設定をしてください。
Dockerアカウントの作成
Docker 自体はアカウントがなくても利用できますが、Docker Hub からのイメージ取得 (pull) に回数制限がかかるなどの不便が生じます。特に授業のように、多数の学生が同時にイメージを取得する状況では、アカウントを持っていないとイメージのダウンロードが途中で止まったり、時間がかかってしまうことがあります。
そのため、事前に Docker アカウント(Docker ID)を作成し、Docker Desktop にログインしておくことを強く推奨します。アカウントは「無料」で作成できます。授業をスムーズに受講するためにもアカウントを作成して、Docker Desktop アプリからログインしておいてください。
7.2 Docker Desktop の動作確認
Docker Desktop がインストールされ、「Docker が利用できる状態になっているかどうか」はタスクトレイのアイコン🐋から確認することができます。以下のように「Docker Desktop running」となっていればOKです。
クジラ🐋のアイコンをダブルクリックすると Docker Desktop のダッシュボードが起動します。次のように「WSL2」を土台として Docker が起動するような設定になっていることを確認してください。
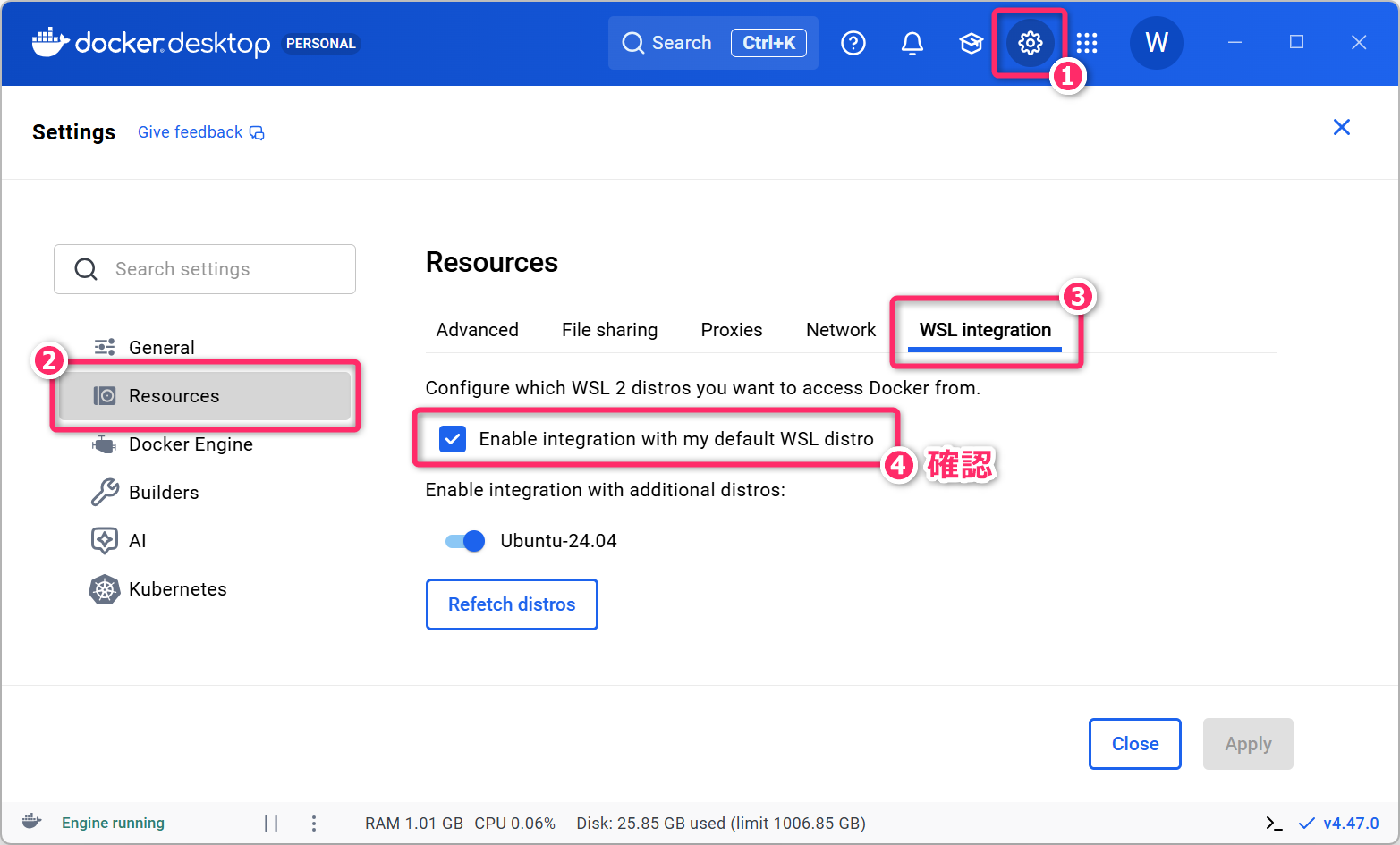
また、ウィンドウの左下に緑色で「Engine running」の文字が表示されていることを確認してください。
DockerDesktopの自動起動の設定
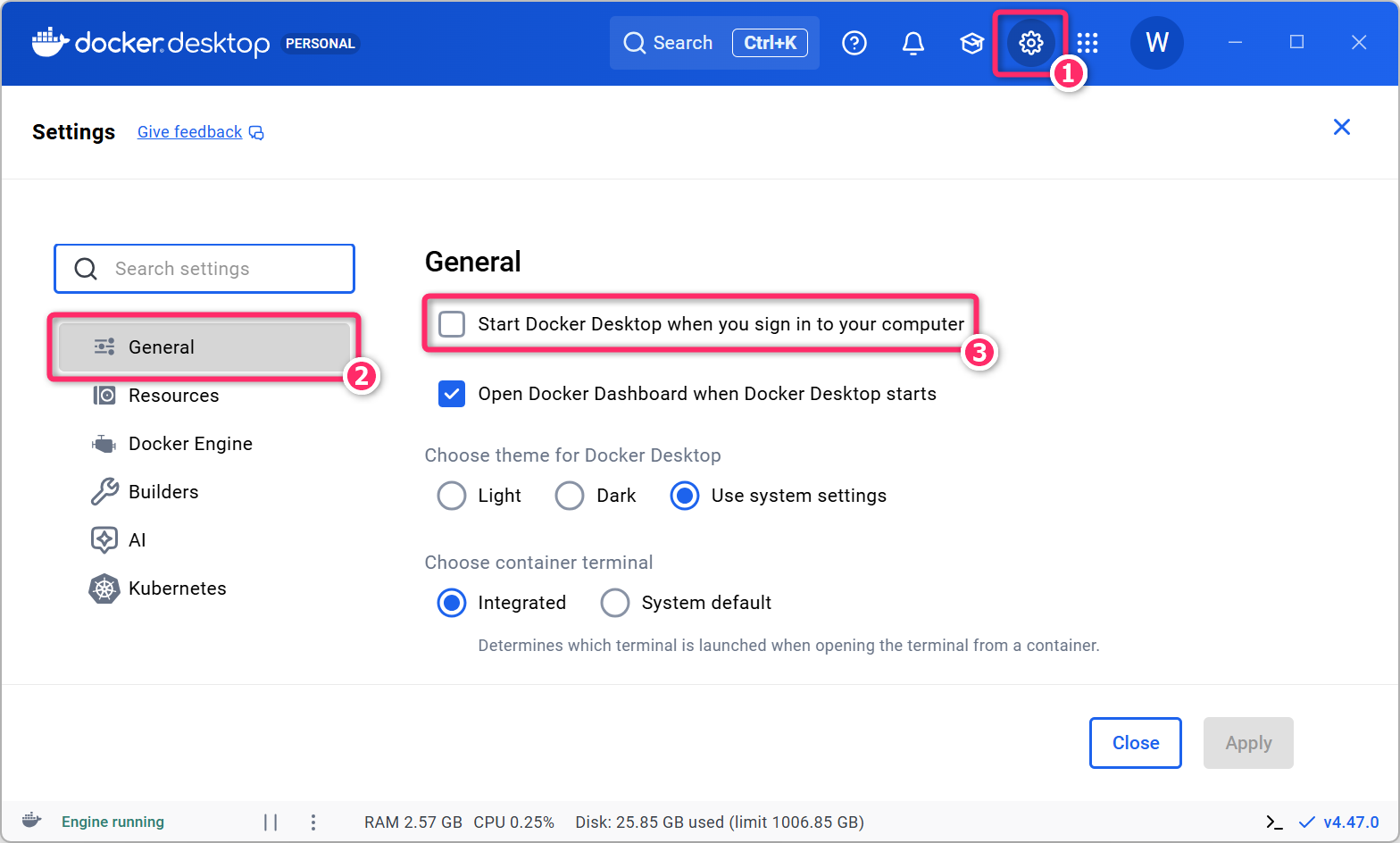
本科目以外で Docker を使用することがなければ、以下のように自動起動をオフにしておくことをお勧めします。なお、自動起動をオフにした場合は、授業の開始前にスタートメニューから「Docker Desktop」を手動で起動しておいてください。
7.3 Hello World コンテナの起動確認
Docker Desktop
の起動が確認できたら、コンテナを問題なく起動できるかを確認しています。ターミナル (PowerShell)
を開いて docker run --rm hello-world というコマンドを実行してください。
PS C:\Users\xxxx> docker run --rm hello-worldこのコマンドの意味については、生成AIやウェブ検索を利用して把握しておいてください。
(プロンプト例)
Docker の「hello-world」イメージは、何のために使用しますか。
docker run --rm hello-worldというコマンドの意味を Docker 初心者向けに解説してください。
処理が正常に実行されると (=hello-world というイメージを DockerHub
から取得して、それを元にコンテナを作成して、そのコンテナを起動・実行し、実行完了後にコンテナが削除できると)、以下のような応答となります。
PS C:\Users\xxxx> docker run --rm hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
17eec7bbc9d7: Pull complete
Digest: sha256:54e66cc1dd1fcb1c3c58bd8017914dbed8701e2d8c74d9262e26bd9cc1642d31
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/上記のメッセージを意訳すると、次のようになります。
Dockerからこんにちは!
このメッセージは、インストールが正常に動作していることを示しています。このメッセージを生成するために、Dockerは次の手順を実行しました。
1. Docker クライアント が Dockerデーモン に接続しました。
2. Docker デーモン は、Docker Hub から “hello-world” イメージをプルしました。
3. Docker デーモン は、そのイメージから新しいコンテナを作成し、現在読んでいる出力を生成する実行可能ファイルを実行しました。
4. Dockerデーモンはその出力を Docker クライアントにストリーミングし、Docker クライアントはそれをターミナルに送信しました。より野心的なものを試すには、次のように Ubuntuコンテナ を実行します。
$docker run-it ubuntu bash無料の Docker ID を使用して、イメージの共有、ワークフローの自動化などを行います。
https://hub.docker.com/その他の例やアイデアについては、次のサイトを参照してください。
https://docs.docker.com/get-started/
7.4 宿題: PostgreSQL と DbGate のイメージのプル (ダウンロード)
注意
このセクションの作業には、非常に大きなファイルのダウンロードをともないます。学校で授業中には実行せず、自宅などで取り組んでください。
次回の授業では、PostgreSQL と DbGate のコンテナを作成します。その準備として、各コンテナの元になるイメージを予めプル (ローカルにダウンロード) しておいてください。手順は以下の通りです。
まず、タスクトレイのアイコンから「Docker Desktop」が起動していることを確認してください。Docker Desktop の自動起動を「オフ」にしている場合は、以下の作業前に手動で起動しておいてください。
ターミナル (PowerShell) を起動して、以下のコマンドを1行ずつ実行してください。このコマンドは Docker Hub から指定の「イメージ」をプルしてくるものです。
docker image pullコマンドの実行には、回線状況によっては数分から10分程度かかる場合があります。
docker image pull postgres:17.6
docker image pull dbgate/dbgate:6.6.3docker pull postgres:17.6のようにimageを省略することもできます。どちらも同じ動作ですが、docker image pullのように明示的に書くと、「イメージ」を対象とした操作であることがより分かりやすくなります (Docker には、主に「イメージ」を対象とした操作と、「コンテナ」を対象とした操作があります)。
イメージが取得できたことを確認します。以下のコマンドを実行してください。
docker images以下のようにリストのなかに postgres:17.6 と dbgate/dbgate:6.6.3
が含まれていれば OK です。
REPOSITORY TAG IMAGE ID CREATED SIZE
postgres 17.6 3fe059c96160 5 days ago 453MB
dbgate/dbgate 6.6.3 c17f3615b225 4 weeks ago 1.32GB
hello-world latest 1b44b5a3e06a 7 weeks ago 10.1kB8 授業時間外学習の指示 (宿題)
- 次回の講義で「小テスト」を実施します。
- 📖 教科書 pp.1-15 を読んでおいてください。20分ほどで読めると思います。
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。
- 講義資料内の「演習」に再度取り組んでください。演習内容は、授業時間中に1回取り組むだけでは定着しないので注意してください。
- 次回までに、Docker Desktop をインストールして、hello-world
コンテナが正常に動作することを確認しておいてください。また、
docker image pullコマンドでpostgres:17.6とdbgate/dbgate:6.6.3のイメージをプルしておいてください。- 問題があれば 遅くとも講義の前日までにアポをとって解決に向けた相談 をしてください。