1 概要・連絡
- 講義資料の最後に 課題06 ポートフォリオの作成に関する説明があります。
- 今回の講義でも
%%writefileなどの マジックコマンド を使用するのでGoogleColab.もしくはローカルPCに構築したJupyter環境の利用を推奨します。
1.1 今回講義の達成目標
- 基本的な「論理演算」ができる。
- テキストファイルの基本的な「読み込み」と「書き込み」ができる。
jsonとpickleライブラリを利用した「シリアライズ」と「デシリアライズ」ができる。- CSVファイルの読込みや表形式データの操作や処理には pandasというライブラリ が適していることを知る。
1.1.1 演習の解答例
今回の演習の解答例はこちらを参照してください。
1.2 プログラミング学習のポイント
モチベーションを保って 効果的にプログラミングを習得するコツ は「授業や参考書で与えられる課題や演習」をこなすのではなく、「自分が “真似してつくってみたい” と思えるモノやサービス」や、身近な人が「あったら便利、助かる~😌」って思ってくれそうなアイデア を見つけ、それを設計・実装することです。
そのためには日頃から「この作業をプログラムで自動化できないか?」やこの作業や行動に付加価値をつけることができないか? といったことを頭の片隅で考える癖をつけておくことが大切です。
2 タプルとfor文の組み合わせ
前回講義ではタプルについて学びました。タプルは「アンパック」と組み合わせて、繰り返し構文の「ループ変数」としても利用されます (アンパック自体は第08回講義で簡単に触れています) 。
まず、アンパック (unpacking) とは、次のように 「タプル」を展開して各要素を「個別の変数」に代入する操作 を指します。以下にアンパックを使った例を示します。
tpl = (2,'知能情報','高専太郎') # タプルの作成
print(type(tpl)) #=> <class 'tuple'>
grade, course, name = tpl # アンパック:「右辺のタプル」を「左辺の変数」に展開
print(type(grade)) #=> <class 'int'>
print(type(course)) #=> <class 'str'>
print(type(name)) #=> <class 'str'>
print(f'grade = {grade}')
print(f'course = {course}')
print(f'name = {name}')そして「タプルのタプル」あるいは「タプルのリスト」について、次のように「for文」と「アンパック」を組み合わせて利用することがあります。
%reset -f
nums = ( (1,'壱'), (2,'弐'), (3,'参') )
i=1
for num in nums:
# print(type(num)) #=> <class 'tuple'>
n0, n1 = num # アンパック
print(f'【{i}回目のループ num => {num}】')
print(f' {n0}0,000円 は {n1}萬円 と表記')
i=i+1上記プログラムの第02行目で初期化している
nums (≠num) は
タプルを要素とするタプルです (つまり タプルのタプル です)。
そして、第04行目のfor構文のなかでループ変数
num (≠nums) には、ループ毎に
(1,'壱')、(2,'弐')、(3,'参')
というタプルが代入されていきます。第06行目では、そのタプルからアンパックされた最初の要素が
n0 に、次の要素が n1
に格納されています。なお、アンパックせずに print(f'{num[0]}0,000円 は {num[1]}萬円 と表記')
のようにプログラムを書いても同じ結果が得られます。
この処理は、次のようにシンプルに記述することもできます。この例のように for文の開始ブロックにアンパックを組み込むことはよくあるので覚えておいてください。
%reset -f
nums = ( (1,'壱'), (2,'弐'), (3,'参') )
for n1, n2 in nums: # ここで【アンパック】している
# print(type(n1)) #=> <class 'int'>
# print(type(n2)) #=> <class 'str'>
print(f' {n1}0,000円 は {n2}萬円 と表記')演習「期待する結果」が得られるように次のプログラムを追記せよ。
%reset -f
table=((0,0,0),(0,0,1),(0,1,0),(0,1,1),
(1,0,0),(1,0,1),(1,1,0),(1,1,1))
print('A B C | D')
print('------+--')
# 以下に追記せよ (forを活用)(期待する結果) ここで D は A+B+C を計算した値です。
A B C | D
------+--
0 0 0 | 0
0 0 1 | 1
0 1 0 | 1
0 1 1 | 2
1 0 0 | 1
1 0 1 | 2
1 1 0 | 2
1 1 1 | 33 論理演算
2年後期の科目「論理回路1」で学んでいるように 論理演算 (ブール演算) は「0と1」あるいは「TrueとFalse」「真と偽」という2つの値のみを取り扱う演算のことを指します (これらの値を「ブール値」「真偽値」「真理値」とも称します)。
論理演算 (ブール演算) は、コンピュータが最も得意とする計算処理であり、当然ながら Python でも取り扱うことができます。
3.1 ブール値
Python において「ブール値 (bool値)」は
True と False
というリテラルで表現します。いずれも先頭が 大文字
である点に注意してください。これらのブール値の「型」は
<class 'bool'> となります。
Pythonでブール値の「リテラル表現」と「型」を確認する一例です。
%reset -f
b1 = True # シングルクォートをつけた 'True' や true では不可
b2 = False
print(f'b1 => {b1}, type(b1) => {type(b1)}')
print(f'b2 => {b2}, type(b2) => {type(b2)}')
print(f'int(b1) => {int(b1)}, int(b2) => {int(b2)}')上記の第06行目では int() によって
ブール型 を 整数型
に変換しています。int(True) は 1
になり、int(False) は 0 になります。
演習1 : 第02行目で
b1 = 'True'
としたときの結果を予想せよ。また、実際にコードを実行して結果を確認せよ。
演習2 : 第02行目で
b1 = true
としたときの結果を予想せよ。また、実際にコードを実行して結果を確認せよ。
3.2 論理和・論理積・論理否定
Python において 論理和 (OR) には
or 演算子、論理積 (AND) には
and 演算子、論理否定 (NOT) は
not
演算子を使用します。これらの演算子は、第06回講義の「if文」の「AND条件」「OR条件」で学んだ演算子と同じです。
次のプログラムを実行して、論理演算が正しくできていることを確認してください。
%reset -f
A = True
B = False
print(f'A={A}, B={B}' )
print(f'論理和 A or B = {A or B}' )
print(f'論理積 A and B = {A and B}' )
print(f'否 定 not A = {not A}')実行結果は次のようになります。
A=True, B=False
論理和 A or B = True
論理積 A and B = False
否 定 not A = Falseなお、論理演算子の「優先順位」は高いほうから 論理否定 (not)、論理積 (and)、論理和 (or) となります。
簡単な応用例として、次のような論理回路 (排他的論理和 XOR) の 真理値表 を作成してみます。排他的論理和は「EX-OR」のように表記することもあります。

%reset -f
# 入力のパターン
inputs =((False,False),(False,True),(True,False),(True,True))
print('A B | X')
print('----+--')
for A,B in inputs:
X = ( A and not B ) or ( not A and B )
print(f'{int(A)} {int(B)} | {int(X)}')実行結果は次のようになります。
A B | X
----+--
0 0 | 0
0 1 | 1
1 0 | 1
1 1 | 0演習 次のような論理回路の 真理値表 を作成せよ。

SymPyライブラリを利用した論理演算
論理演算 は Python の標準機能だけでも行なうことができます。しかし、数式処理・記号計算用のライブラリである SymPy (シムパイ) を利用すれば、より 効率的 かつ 直感的 に論理演算を行うことができます。論理回路の学習 (手計算した結果の検証など) に効果的に役立てください。
ローカルPCにPython環境を構築している場合は、コマンドラインから
pip install sympy で SymPy
をインストールしてください。GoogleColab. 環境ではデフォルトで
SymPy がインストールされています。
SymPyを利用して、次のような 論理式の簡略化 (論理圧縮) をしてみます。
\[ X = \mathrm{A} \cdot \mathrm{B} \cdot \mathrm{C} + \bar{\mathrm{A}}\cdot \mathrm{B} \cdot \mathrm{C} + \mathrm{A}\cdot \bar{\mathrm{B}} \cdot \mathrm{C} + \mathrm{B} \cdot \bar{\mathrm{C}} \]
%reset -f
import sympy
import re
from IPython.display import Math
def display2(out,expr):
t = sympy.latex(expr)
s = re.sub(r'\\neg ([a-zA-Z]+)', r'\\overline{\1}', t)
s = s.replace(r'\vee',r'+')
s = s.replace(r'\wedge',r'\cdot')
display(Math(f'{out}={s}'))
# 論理式の簡略化
A, B, C = sympy.symbols('A,B,C')
print(type(A)) # => <class 'sympy.core.symbol.Symbol'>
X = A&B&C | ~A&B&C | A&~B&C | B&~C
display2('X',sympy.to_dnf(X,simplify=True))このプログラムを実行すると「\(X=B+(A\cdot C)\)」という出力が得られます。
関数 display2
は「TeX形式」で論理式を整形出力するための関数なので本質ではありません。第14行目と第16行目、第17行目
が本質の部分になります。
第14行目で
sympy.core.symbol.Symbol 型 (以降、単に
Symble 型と表記) の変数 A B
C を作成しています。Symble
型は、論理和を |
演算子で計算します。また、論理積を
& 演算子、論理否定を
~
演算子で計算します。第16行目では、これら演算子で
\(X=...\) を定義しています。
そして、第17行目の
sympy.to_dnf(...)
で最小積和形に変換しています。DNF: Disjunction
Normal Form (加法標準形)。
SymPyを利用して、次のような 真理値表から論理式(簡略化済み) を導いてみます。ABCが入力、Yが出力になります。
| A | B | C | Y |
|---|---|---|---|
| 0 | 0 | 0 | 1 |
| 0 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 0 |%reset -f
import sympy
import re
from IPython.display import Math
def display2(out,expr):
t = sympy.latex(expr)
s = re.sub(r'\\neg ([a-zA-Z]+)', r'\\overline{\1}', t)
s = s.replace(r'\vee',r'+')
s = s.replace(r'\wedge',r'\cdot')
display(Math(f'{out}={s}'))
# 真理値表から簡略化した論理式を作成
A, B, C = sympy.symbols('A,B,C')
Y = sympy.SOPform((A,B,C),((0,0,0),
(0,1,1),
(1,0,0),
(1,1,0)))
display2('Y',sympy.to_dnf(Y,simplify=True))このプログラムを実行すると「\(Y=(A\cdot \bar{C})+(\bar{B}\cdot \bar{C})+(B\cdot C\cdot \bar{A})\)」という出力が得られます。
第15行目の sympy.SOPform
の第2引数には「真理値表で出力Yが 1
となる入力」をタプルで与えています。
4 テキストファイルの「読み込み」と「書き込み」
ここでは Python プログラムから「テキストファイルを読み込む方法」と「テキストファイルに書き込む方法」について学習します。
4.1 準備: テキストファイルの作成
まずは準備として、読み込みテストのための「テキストファイル」を用意 (作成) します。
GoogleColab.もしくはJupyterでは
%%writefile
というマジックコマンドを使用してテキストファイルを生成することができます。例えば、コードセルに次のような内容を記述して実行すると
第02行目 以降の内容が書かれた
test-01.txt
というテキストファイルが生成されます。
%%writefile test-01.txt
Name,ヨシヒコ
Job,勇者
Lv,21生成されるテキストファイルの「改行コード」は、Windows環境に構築したJupyterでは「CR+LF」、GoogleColab. (=Linux仮想マシンで動作している) では「LF」となります。また、文字コードはいずれも「UTF-8」となります。「改行コード」については「情報2」の講義資料を参照してください。
演習: %%writefile
使って日本語を含んだ「テキストファイル」を生成せよ。また、そのテキストファイルの「文字コード」と「改行コード」を確認せよ。GoogleColab.で生成したテキストファイルは
ダウンロードして VSCode
に読み込ませて「文字コード」と「改行コード」を確認せよ。
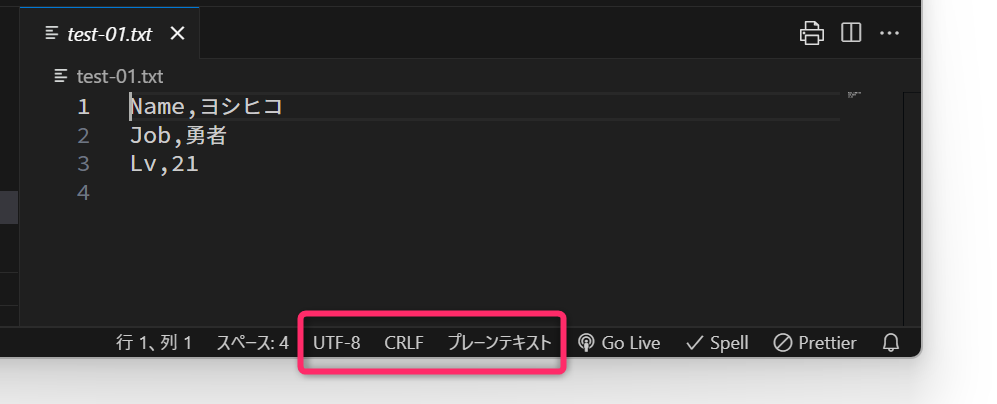
文字コードと改行コードを確認する方法
対象のテキストファイルを VSCode に読み込ませて ウィンドウ右下の表示 から「文字コード」と「改行コード」を確認することができます。
4.2 テキストファイルの読み込み
テキストファイルは、次のように
Pythonプログラムから読み込むことができます。readlines()
メソッドは、テキストファイルの1行1行を要素とする 文字列のリスト が戻値になります。
%reset -f
import os
# ファイル名・ファイルパスを設定
fn = 'test-01.txt'
# 指定のファイルが存在しなければエラーを発生させて強制停止
if not os.path.isfile(fn):
raise FileNotFoundError(f'{fn} は存在しません。強制終了します。')
# ファイルから文字列を読み込み、変数textに格納
with open(fn, encoding='utf_8') as file:
text = file.readlines()
# 変数textの内容を確認
print(f'type(text) => {type(text)}') # textはリスト型
print(f'len(text) => {len(text)}' ) # リストの要素数は「3」
print(f'text => {text}') # リストの内容テキストファイルの読み込みの本質部分は第12行目と第13行目です。上記のプログラムを実行すると、次のような結果が得られます。
type(text) => <class 'list'>
len(text) => 3
text => ['Name,ヨシヒコ\n', 'Job,勇者\n', 'Lv,21\n']この実行結果から、変数 text
は要素数が「3」の「文字列のリスト」であることが確認できます。また、その要素である各文字列の末尾には
改行 \n がついていること
に注意してください。
4.3 テキストファイルの処理
readlines()
により読み込まれた値は「文字列型のリスト」となっています。これを処理して
辞書型の変数 data
に格納し、data['Name'] のような表記で
ヨシヒコ を参照できるようにしていきます。
「辞書型」について記憶の欠落がある学生は第12回講義を再読してください (また前回講義でも辞書型について扱いました) 。
4.3.1 「末尾の改行削除」と「カンマ位置での文字列分割」
準備として 'Name,ヨシヒコ\n'
のような文字列から、末尾の改行を削除し、さらにカンマの位置で文字列を分割する方法について考えていきます。
最初に「文字列の末尾の改行 \n
を削除」する方法ですが、これは
strip() メソッドを使用します。strip()
メソッドは、文字列前後の「改行」や「空白文字」などを削除した文字列を返すメソッドになります
(詳しくは「python
strip」などで検索してください) 。
次のプログラムを実行して、使い方と結果を確認してください。
%reset -f
t = 'Name,ヨシヒコ\n'
# 末尾に改行を含む
print('----')
print(t)
print('----')
t = t.strip() # 末尾の改行を削除して、変数 t を上書き
print()
# 末尾の改行を取り除いたあと
print('----')
print(t)
print('----')演習1: 第02行目を
t = '\n\n Name,ヨシヒコ\n\n\n'
に変更するとどうなるか予想し、実際に結果を確認せよ。
演習2: 第09行目を
t = t.strip() から t.strip()
に変更すると (つまり t= を抜くと)
どうなるか予想し、実際に結果を確認せよ。
4.3.2 文字列の分割
次に、strip メソッドを使って文字列内のカンマ
,
を「区切り文字」にとして分割する処理を扱います。区切り文字は
次のプログラムを実行して、使い方と結果を確認してください。
%reset -f
t = 'Name,ヨシヒコ'
tmp = t.split(',') # カンマで分割して文字列のリストに変換
print(f'type(tmp) => {type(tmp)}')
print(f'len(tmp) => {len(tmp)}',end='\n\n')
print(f'tmp => {tmp}')
assert len(tmp) >= 2
print(f'tmp[0] => {tmp[0]}')
print(f'tmp[1] => {tmp[1]}')第11行目 の assert (アサート) について忘れてしまった学生は、第07回講義 を再読してください。このあとも登場するので、しっかりと理解しておいてください。
演習1: 第02行目を
t = 'Name,ヨシヒコ,山田'
に変更するとどうなるか予想し、実際に結果を確認せよ。
演習2: 第02行目を
t = 'Name,ヨシヒコ,,山田'
に変更するとどうなるか予想し、実際に結果を確認せよ。カンマが連続している点に着目して予想すること。
演習3: 第02行目を
t = 'Name'
に変更するとどうなるか予想し、実際に結果を確認せよ。文字列内にカンマがない点に着目して予想すること。
演習4: 第02行目を
t = 'Name,ヨシヒコ'
に変更するとどうなるか予想し、実際に結果を確認せよ。カンマが全角文字である点に着目して予想すること。
4.3.3 処理を組み合わせて辞書型に格納
テキストファイルを読み込み、辞書型に格納する処理を総合すると次のようなプログラムになります。
%reset -f
import os
fn = 'test-01.txt'
if not os.path.isfile(fn):
raise FileNotFoundError(f'{fn} は存在しません。強制終了します。')
with open(fn, encoding='utf_8') as file:
text = file.readlines()
data = {} # 空の辞書を作成。data = dict() でも可
for t in text:
t = t.strip()
tmp = t.split(',')
assert len(tmp) == 2
key = tmp[0]
value = tmp[1]
data[key]=value # 辞書に追加
print(f'data => {data}')
print(f"data['Name'] => {data['Name']}") # => ヨシヒコ演習: テキストファイルの内容が次のような場合、どのようになるか予想し、実際に結果を確認せよ。
Job,勇者
Name,ヨシヒコ
Lv,21
HP,512
MP,1284.3.4 (補足) 型変換
テキストファイルから読み込んだ情報は、すべて 文字列型 となります。整数型などの変換する場合は、次のように型を変換する必要があります。
%reset -f
data = {'Name':'ヨシヒコ','Job':'勇者','Lv':'21'}
print(type(data['Lv'])) # => <class 'str'>
data['Lv'] = int(data['Lv']) # str -> int 変換して上書き
print(type(data['Lv'])) # => <class 'int'> 4.3.5 (補足) 不足情報の確認
テキストファイルから読み込んで構成した辞書に、特定のキー
(例えば Job や Name)
が含まれているかは第12回講義で学習したように
in または not in
と条件分岐で確認できます。
%reset -f
data = {'Name':'ヨシヒコ','Job':'勇者','Lv':'21'}
if 'HP' not in data.keys() :
print('セーブファイルに HP の項目が存在しません')4.4 テキストファイルの書き込み
Pythonプログラムからは、次のようにテキストファイルを作成することができます。ここでは
open 関数の引数に mode='w'
を追加することを忘れないでください。mode='w'
は書き込みモード (Write Mode)
でファイルをオープンする指示になります。
%reset -f
fn = 'test-02.txt'
with open(fn, mode='w', encoding='utf_8') as file:
file.write('Name,メレブ\n')
file.write('Job,賢者\n')
file.write('Lv,19\n')なお、file.write メソッドのなかで \n
を使用すると、Windows環境では「CR+LF」、Linux環境では「LF」の改行コードでファイルに文字列が出力されます。
演習: 第03行目を
with open(fn, encoding='utf_8') as file:
に変更するとどうなるか予想し、実際に結果を確認せよ。
4.5 考察
このセクションでは、ファイルの基本的な読み書き方法について紹介しました。しかし、この方法では 複雑なデータ構造を持つ情報 を「テキストファイルに出力すること」や「テキストファイルから入力すること」は難しく、コードも複雑となります。
例えば、既存の情報 (NameやJob) に加えて、以下の
data のように 所持アイテムの種類や個数に関する情報
などを含めたデータを セーブ / ロード
する処理を考えると、そのプログラムは格段に複雑化します。
%reset -f
p1 = {'Name':'ヨシヒコ', 'Job':'勇者', 'Lv':21,
'BatStatus':['毒','呪い'],
'Items':[['銅のつるぎ',1],['薬草',4]]}
p2 = {'Name':'メレブ', 'Job':'賢者', 'Lv':19,
'BatStatus':['混乱'],
'Items':[['聖なるナイフ',1],['いのりの指輪',2],['毒消し草',3]]}
data = [p1,p2]
print(data)このようなことから、Pythonでは
オブジェクト(変数の内容)を「テキストデータ」や「バイトデータ」に簡単に変換する処理
をサポートするライブラリが提供されています。この変換処理を
シリアライズ
(Serialization)
といい、逆に、シリアライズされたデータを元のオブジェクトに戻す処理を
デシリアライズ
(Deserialization) といいます。次に紹介する
json や pickle は、この シリアライズ /
デシリアライズ の機能を提供するライブラリの例です。
これらのライブラリを利用すると、オブジェクトの ファイル保存 や ネットワーク経由の送受信 が容易になります。
5 JSON形式のシリアライズとデシリアライズ
JSON (JavaScript Object Notation)は、もともと JavaScriptのオブジェクト表記法 から派生した 軽量なデータ交換フォーマット です。テキストベースのフォーマットで、適切に整形されていれば人間にとっても読みやすい形になっています。主にWebアプリケーションでサーバーとクライアント間のデータ送受信に使われ、WebAPI (Web Application Programming Interface) のデータ交換フォーマットとしても標準的に採用されています。
Python では json
ライブラリを利用することで「JSON形式」のデータの
シリアライズ (エンコード) と
デシリアライズ (デコード)
を簡単に実行することができます。先にも述べたように「シリアライズ」は
PythonオブジェクトをJSON形式の「文字列」に変換するプロセス
を指し、「デシリアライズ」は、JSON形式の「文字列」をPythonオブジェクトに変換するプロセス
を指します。
5.1 シリアライズ
json ライブラリ (モジュール)
を使用した「シリアライズ」の例を示します。なお json
ライブラリは、Pythonの標準ライブラリの一部であるため特別なインストールは必要ありません。
%reset -f
import json # 要インポート
# データの準備
p1 = {'Name':'ヨシヒコ', 'Job':'勇者', 'Lv':21,
'BatStatus':['毒','呪い'],
'Items':[['銅のつるぎ',1],['薬草',4]]}
p2 = {'Name':'メレブ', 'Job':'賢者', 'Lv':19,
'BatStatus':['混乱'],
'Items':[['聖なるナイフ',1],['いのりの指輪',2],['毒消し草',3]]}
data = [p1,p2]
# JSON形式にシリアライズしてテキストファイルとして保存
fn = 'test-03.json'
with open(fn, mode='w', encoding='utf_8') as file:
json.dump(data, file, ensure_ascii=False) 上記のプログラムを実行すると、カレントフォルダに
test-03.json
というファイルが生成されます。テキストエディタで
test-03.json
を開いて内容を確認してください。また、json.dump で
indent=2 オプションを付けると 人間が読みやすいように改行とインデントが追加された形式
でJSONファイルが出力されます。
演習1: json.dump に
indent=4
オプションを追加して実行し、その結果を確認せよ。
演習2: json.dump から
ensure_ascii=False
オプションを抜いて実行し、その結果を確認せよ。
5.2 デシリアライズ
json ライブラリ (モジュール)
を使用した「デシリアライズ」の例を示します。
%reset -f
import os
import json
# ファイルの存在チェック
fn = 'test-03.json'
if not os.path.isfile(fn):
raise FileNotFoundError(f'{fn} は存在しません。強制終了します。')
# JSON形式のファイルからデシリアライズ
with open(fn, encoding='utf_8') as file:
data = json.load(file)
# print(data)
print(f"{ data[1]['Job'] } { data[1]['Name'] } は ")
for name, count in data[1]['Items'] :
print(f'「{name}」を {count}個')
print('所持しています。')json
ライブラリを使用することで、非常に簡単にデータのセーブとロードができることが分かります。
5.3 注意点
JSONは テキストベース
のデータ交換フォーマットです。このフォーマットは
データの構造を保存することは可能ですが、具体的な型情報(例:リスト型か、ndarray型かの区別)までは保存できません。その結果、json
モジュールで扱えるのは
Pythonの基本的なデータ型(文字列、数値、リスト、辞書、ブール値)に限られます。
例えば、次のように NumPy の ndarray
型のオブジェクトをシリアライズしようとすると TypeError: Object of type ndarray is not JSON
serializable が発生します。
%reset -f
import numpy as np
import json
a1 = np.array([[2,3,4],[5,6,7]])
print(type(a1)) # => numpy.ndarray
# JSONにシリアライズしてセーブ
fn = 'test-04.json'
with open(fn, mode='w', encoding='utf_8') as file:
json.dump(a1, file, ensure_ascii=False) この問題を解決するには、ndarray
型のオブジェクトを「リスト型」に変換してからシリアライズする必要があります。
%reset -f
import numpy as np
import json
a1 = np.array([[2,3,4],[5,6,7]])
print(type(a1)) # => <class 'numpy.ndarray'>
a2 = a1.tolist()
print(type(a2)) # => <class 'list'>
fn = 'test-04.json'
with open(fn, mode='w', encoding='utf_8') as file:
json.dump(a2, file, ensure_ascii=False) また、JSONはテキストファイルであり、その可読性も高いためデバッグなどには有利ですが、同時にセキュリティのリスクが伴います。具体的には、プログラムの使用者がJSONファイルの内容を簡単に閲覧・書き換えることができるため データの機密性や整合性が損なわれる可能性 があります。
例えば、RPGゲームのセーブデータを JSON形式で管理・保存していた場合、プレイヤーがファイルを開いてキャラクターのステータスや所持アイテムを変更する可能性があります。これにより、ゲームのバランスが崩れたり、不正なプレイが発生する可能性があります。
これを防ぐためには、以下のような対策が考えられます。
- ファイルの暗号化: JSONファイル自体を暗号化する ことで不正なアクセスを防ぐ。
- チェックサムの使用: ファイル の改ざんを検出するためにチェックサム を用いる。
- サーバーサイドでの検証: ゲームの重要なデータはサーバーサイドで管理し、クライアントでは表示だけを行うようにする。
6 pickle形式のシリアライズとデシリアライズ
pickle (ピクル) ライブラリを使用すると、NumPy
の ndarray
型のほか、自作したクラスのインスタンスなど、様々なオブジェクトをシリアライズ
/ デシリアライズすることができます。
pickle ライブラリのシリアライズにより生成される「pickleファイル」はバイナリ形式となります。そのため「JSONファイル」のようにライトユーザーがテキストエディタで開いて閲覧、編集することは簡単にはできません。また、「pickleファイル」は、Python 特有のフォーマットであるため、基本的にはPython以外の言語や環境で利用にはできません。
pickle (ピクル) の由来
pickle (ピクル) は、酢漬けや塩漬けの漬物に由来しています。ピクルの複数形が「ピクルス」で、日本ではハンバーガーのアレとして知られています。データを漬物にする (=保存する) という洒落から、このようなライブラリ (モジュール) の名前がついたそうです。
pickle
ライブラリは、Pythonの標準ライブラリの一部であるため特別なインストールは必要ありません。
6.1 シリアライズ
json ライブラリ (モジュール)
を使用した「シリアライズ」の例を示します。ndarray
型がそのままシリアライズできる点に注意してください。
%reset -f
import numpy as np
import pickle
# データの準備
a1 = np.array([[2,3,4],[5,6,7]])
a2 = np.array([[9,8,7],[6,5,4]])
print(type(a1)) # => <class 'numpy.ndarray'>
data = {'A':a1, 'B':a2 }
# シリアライズ
fn = 'test-05.pickle'
with open(fn, mode='wb') as file:
pickle.dump(data, file)第13行目 の open
関数のキーワード引数の mode='rb'
は、ファイルをバイナリ形式 (binary format) で書き込み (write)
モードでオープンすることを指定するものです。
このプログラムを実行すると、カレントフォルダに
test-05.pickle というファイルが生成されます
(テキストエディタでは内容を適切に確認することができません)。
6.2 デシリアライズ
「デシリアライズ」の例を示します。ndarray
という型情報が維持されていることを確認してください。
%reset -f
import numpy as np
import pickle
# デシリアライズ
fn = 'test-05.pickle'
with open(fn,'rb') as file:
data = pickle.load(file)
print(type(data['A'])) # => <class 'numpy.ndarray'>
print(data['A'])open 関数のキーワード引数の mode='rb'
は、ファイルをバイナリ形式 (binary format) で読み込む (read)
でオープンすることを指定するものです。
演習1: 第02行目の
import numpy as np
を削除するとどうなるか確認せよ。
6.3 注意点
pickleファイルはバイナリ形式であるため、直接の閲覧・編集は難しいですが、一定の知識とスキルがあれば 改ざんすること も可能です。特に パスワード や APIキー などの機密性が高い情報は、pickleファイルに直接保存せず、適切な方法で安全に保管するよう心掛けてください。
セキュリティの観点からも、pickleファイルの取り扱いには注意が必要です。信頼性の確認できない ソース からpickleファイルを読み込む場合、悪意のあるコードが埋め込まれている可能性があり、それが実行されるとシステムが危険にさらされます。信頼できるソースからのみpickleファイルを読み込むようにし、さらに適切なセキュリティ対策を行うよう努めてください。
7 Pandas を使った CSV / Excel ファイルの読み込み
「計測実験の結果」や「データ分析や機械学習のデータ」は CSVファイル として提供されることが多いです。「情報1」で学んだように、CSV はComma Separated Values の頭文字あり、表データの列を「カンマ (コンマ)」で区切り、行を「改行」で区切って表現したテキストデータです。Excelがインストールされた環境では、CSVファイルをダブルクリックすると Excel が起動しますが、実体は単なるテキストファイルである点に注意してください。
CSVデータは、テキストデータとしてPythonで読み込むことができますが、Pandas (パンダス) モジュールを使うことで「柔軟」かつ「簡単」に CSVの読込み ができます。さらに、Pandasは 読み込んだ表形式データに対する様々な操作や処理の機能 を提供し、Pythonで「データ分析」や「機械学習(AIを含む)」に取り組む際には NumPy、Matplotlib とあわせて必須ライブラリとなっています。
Pandas を使ったデータ処理については次回の講義で扱います。ここでは CSVファイル の「読込み」についてのみ簡単に紹介します。
7.1 Pandas のインストール
GoogleColab. 環境ではデフォルトで Pandas
がインストールされているので、インポートすればそのまま利用することができます。一方、ローカルPCに環境を構築している場合
(仮想環境を構築している場合) は、コマンドラインから
pip install pandas で Pandas
をインストールしてください。
7.2 CSVファイルの読込み
次のような CSV ファイル Current(mA)_00.csv
があるとします (このデータに見覚えはありませんか?)。まず
%%writefile
を利用し、このCSVファイルを生成してください。
created,current (mA)
2023/9/23 10:30:00.138,1.8359375
2023/9/23 10:30:30.75,1.953125
2023/9/23 10:31:03.656,1.796875
2023/9/23 10:31:50.695,3.6328125
2023/9/23 10:32:20.137,3.7109375
2023/9/23 10:32:50.59,3.671875
2023/9/23 10:33:21.470,3.7109375
2023/9/23 10:33:51.744,3.4765625
2023/9/23 10:34:21.533,3.671875
2023/9/23 10:34:58.539,5.4296875
2023/9/23 10:35:27.895,5.2734375
2023/9/23 10:35:58.61,5.4296875
2023/9/23 10:36:28.479,5.46875
2023/9/23 10:36:57.977,5.5078125
2023/9/23 10:37:28.19,5.078125
2023/9/23 10:38:12.777,4.0625
2023/9/23 10:38:42.173,4.140625
2023/9/23 10:39:12.312,4.1015625
2023/9/23 10:39:42.341,3.984375生成したCSVファイル Current(mA)_00.csv は、Pandas
を使って次のように読み込むことができます。
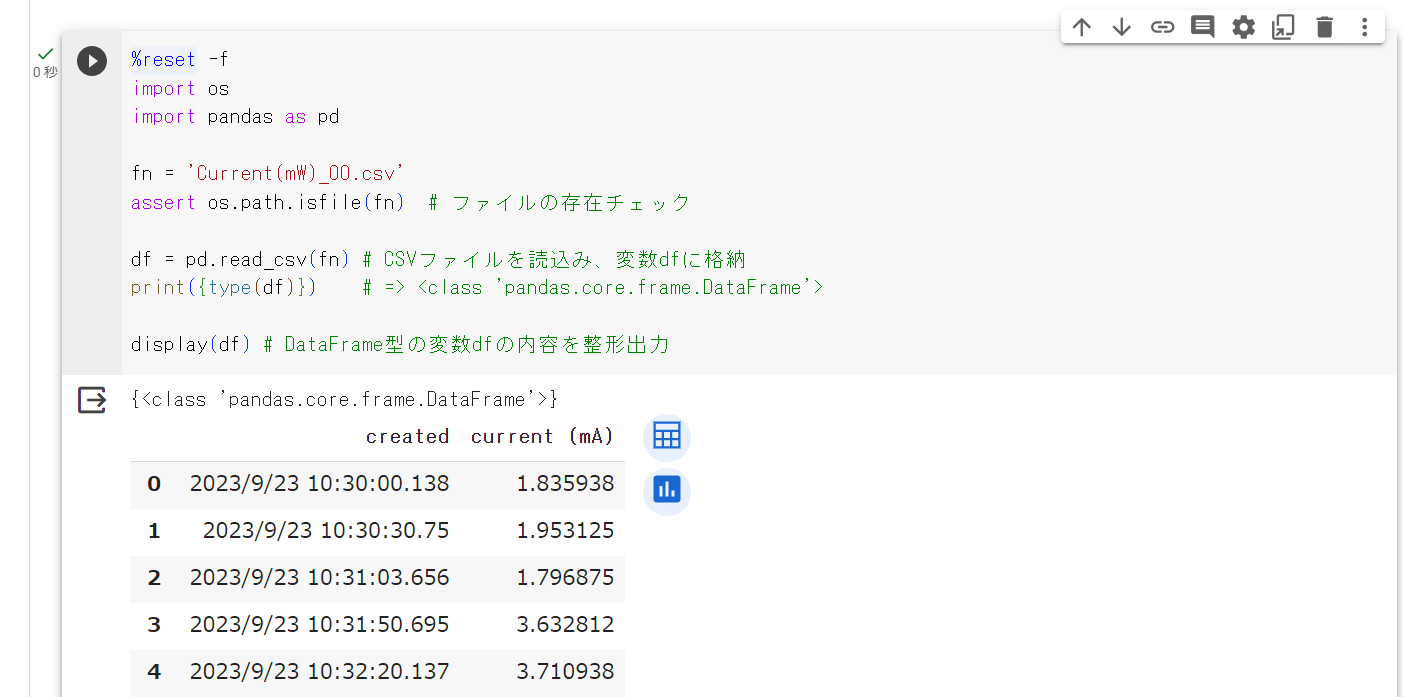
%reset -f
import os
import pandas as pd
fn = 'Current(mA)_00.csv'
assert os.path.isfile(fn) # ファイルの存在チェック
df = pd.read_csv(fn) # CSVファイルを読込み、変数dfに格納
print({type(df)}) # => <class 'pandas.core.frame.DataFrame'>
display(df) # DataFrame型の変数dfの内容を整形出力コードについて解説します。
第02行目: Pandas ライブラリ (モジュール) をインポートしています。慣例的に Pandas は
pdという省略名で使用します。インポートの際はpandasのように小文字で表記することに注意してください。第06行目: assert (アサート文) を使って ファイルが存在していること を確認しています。通常、
assertに続けて「条件式」を記述しますが、それに限らずTrueまたはFalseを返すものであれば何でも記述ができます。関数os.path.isfile(...)は、引数で与えたファイルが存在するならTrue、存在しないならFalseを返す関数なので、アサートに続けてそのまま記述しています。もし、丁寧 (冗長) に記載するならassert os.path.isfile(fn) == Trueとなります。第08行目: Pandas の
read_csv関数を使ってファイルを読込み、そこからDataFrameという「型」のオブジェクトを生成し、変数dfに格納しています (慣例的にDataFrame型の変数にはdfという名前を使います)。- Pandas には
read_excelやread_jsonなどの関数も用意されています。つまり、ほぼ同様に Excel ファイル (.xlsxや.xls) からも表データを読み込むこと ができます。
- Pandas には
第09行目: 変数
dfの「型」を確認しています。DataFrame型であることが確認できます。第11行目:
dfを整形出力しています。このdisplayはJupyter環境、GoogleColab.環境でのみ有効です。
上記プログラムを実行すると次のような出力が得られるとおもいます
演習: 第11行目の
display(df) を print(df)
に書き換えるとどのようになるか確認せよ。
7.3 任意列をndarray型に変換
df (DataFrame 型)
の任意の「列」は、NumPy の ndarray
型に変換ができます。ところで、前回講義では ndarray
型のデータを使ってグラフを作成しました。よって、この
df からもグラフを作成できます。
次のプログラムを実行して「CSVファイルを読込んでグラフを作成できること」を確認してください。
%reset -f
import os
import pandas as pd
import matplotlib.pyplot as plt
fn = 'Current(mA)_00.csv'
assert os.path.isfile(fn) # ファイルの存在チェック
df = pd.read_csv(fn) # CSVファイルを読込み、変数dfに格納
x = df['created'].to_numpy() # ndarray型に変換
y = df['current (mA)'].to_list() # 〃
print(type(x)) # => <class 'numpy.ndarray'>
print(type(y)) # => <class 'numpy.ndarray'>
fig,ax = plt.subplots(dpi=120)
ax.plot(x,y,marker='o')
plt.show()実行すると、次のように (工学系レポートとしては苦笑い品質の) グラフが生成できました。

演習: 第11行目を
x = df['created'].to_list()、第12行目を
y = df['current (mA)'].to_list()
に書き換えるとどのようになるか確認せよ。
7.4 DataFrame型を引数とするグラフ描画と整形
上記では DataFrame 型の変数 df
から任意列を取り出して、ndarray 型に変換してから
Matplotlib に与えていました。しかし、これは
ax.plot(df['created'],df['current (mA)'],marker='o')
のように DataFrame 型のままでMatplotlib
にデータを与えることができます。
また、レポートに使用できるようにグラフを整形するプログラムを示します。なお、第12行目や整形に関する詳細は現時点で理解する必要はありませんが、パラメータと出力結果の関係については把握しておいてください
(例えば グラフの右端を 10:39
にするためには、どのパラメータを変更すればよいか や X軸の時刻表示を「HH時MM分」の形式にするためには、どのパラメータを変更すればよいか
など)。
%reset -f
import os
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import pylab
from datetime import datetime as dt
fn = 'Current(mA)_00.csv'
assert os.path.isfile(fn)
df = pd.read_csv(fn)
df['created'] = df['created'].apply(lambda x: dt.strptime(x, '%Y/%m/%d %H:%M:%S.%f'))
fig,ax = plt.subplots(dpi=120)
ax.plot(df['created'],df['current (mA)'],marker='o')
ax.set_xlabel('Time [ 2023/09/23 10:30-10:40 ]',labelpad=10)
ax.set_ylabel('Current (mA)')
ax.set_xlim(dt(2023,9,23,10,30),dt(2023,9,23,10,40))
ax.set_ylim(0,6)
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda p,q: pylab.num2date(p).strftime('%H:%M')))
ax.yaxis.set_major_formatter(ticker.FuncFormatter(lambda p,q: f'{p:.1f}'))
ax.tick_params(axis='x',labelrotation=-90)
ax.tick_params(direction='inout')
ax.grid()
plt.tight_layout()
plt.show()実行すると次のようなグラフが生成されます。これならレポートにも使用できそうです。

以下の 演習EX の実施は任意です。
演習EX-1: グラフの右端が 10:39
となるようにせよ。
演習EX-2: Y軸の目盛りの上限を「8」に設定し、さらに「+4.00」のようにプラス記号を付けて、小数第2位までを表示するようにせよ。
演習EX-3:
X軸の時刻表示を「HH時MM分」の形式にせよ。なお、日本語を使用するためには
japanize_matplotlib が必要である。
7.5 補足: マインド
上記のプログラムをゼロから作成してグラフを出力するためには、Excelを使って手作業でグラフを作成するよりも 10倍以上の時間がかかる と思います。しかし、同じようなグラフを10枚以上作成するようなケース (例えば このグラフが太陽光発電の状況をモニターするものだとして、毎日、100台分の装置についてグラフを作成しなければならない ようなケース) では、プログラムを使用するほうが 圧倒的な労力軽減・時間短縮 になります。
それに、既にこうやって叩き台となるサンプルプログラムがある状況では、なおさらプログラを使ってグラフを出力するほうが時間短縮になり、皆さんにとってスキルを伸ばす機会 (生きた学び) にもなります。
プログラミングの授業だけでなく 日常の様々な場面でプログラムによる自動化・高付加価値化 の可能性を考え、それを設計・実装することを大切にしてください。
世の中には「めんどくさいことをしないためなら、いかなる努力も惜しまない」という歪んだ価値観の連中が存在する。
面倒な作業はラクして簡単に瞬殺で済ませようとする「前向きな怠惰」の思想を忘れずに。
8 課題06
「HTML」と「CSS」を使用して、今後の「インターンシップ」「就職」「進学」などのキャリア活動に利用してくための ポートフォリオ を作成してください。今回作成してもらうものは「第1版」であり、今後の学生生活のなかでコンテンツを追加・更新し、構造やデザインを ブラッシュアップ していくものと捉えてください。
無論、JavsScript を使用してもOKです。
作成に際しては先輩ら (2024年度3Iの学生) のポートフォリオを参考にしてください。
ポートフォリオとは
ICT系のエンジニアを目指す学生にとっての「ポートフォリオ」とは 自分のスキルや経験・活動、制作物をまとめて示すもの です。履歴書や職務経歴書が「経歴」を示すことに対し、ポートフォリオは「自分が何ができるのか」を具体的にアピール・証明する資料となります。
特に ゲーム業界やエンターテインメント業界のソフトウェアエンジニア を目指す場合、そのインターンシップや就職における (意欲や技術面の) 評価に「ポートフォリオ」がとても重要になってきます。
具体的な内容としては「自己紹介 (所属や年齢)」「スキルセット (使用経験のあるプログラミング言語や開発環境、フレームワーク、クラウドサービス、ツールなど)」「得意分野」「成果物・制作物」「保有資格 (情報技術系/その他)」「コンテスト・ハッカソン・イベント・セミナー・プロジェクト・会社見学・インターンシップなどの取り組みの記録 (現在進行形の活動を含む)」「 GutHub / AtCoder / Techful / SNS / ブログ / YouTube などのリンク や 連絡先 (メールアドレスなど) 」などを記載します。ただし、すべてを網羅するのではなく、目的に応じてアピールしたい情報を選んで記載します。
以下、ポートフォリオの作成例です。そのほか「高専 ポートフォリオ site:github.io」で検索すると参考になる様々なポートフォリオを見つけることができます。
- https://yamasy.info/ (明石高専OG)
- https://teruyamato0731.github.io/portfolio/ (公大高専生)
- https://surahotoke.github.io/portfolio/ (公大高専生)
- https://herorobo.github.io/portfolio/ (公大高専OB)
- https://kisaragi2342.com/portfolio/ (高専生)
- https://nnsnodnb.github.io/ (高専生)
- https://datsuka-qwerty.github.io/my-page/ (高専生)
- https://yamagn.github.io/ (高専生)
- https://oriishitakahiro.github.io/portfolio/ (高専OB)
- https://chinnanagosge.github.io/portfolio/ (高専OB)
- https://chige12.github.io/ (高専OB)
- https://onsd.github.io/ (高専・専攻科生)
- https://sample-portfolio-psi.vercel.app/
また、構成や書き方についての詳細は「ポートフォリオ IT業界 学生」などで検索してみてください。また、テンプレートなども公開されているので、第1版では、それを利用することもお勧めします。また 第15回講義 のカレーレシピの HTML/CSS も有効に利用してください (最低限のページは作成できるはずです)。
作成したポートフォリオは GitHub Pages で公開し、その URL (= https://xxxxx.github.io/yyy/zzz.html) を Google Classroom で指示する方法で提出してください。
- 「7.5点」を標準として「10点満点」で評価します (学年末の成績評価の際には「重み」が付けられます)。
- 提出期限: 2024年11月13日 (水) 23時
- 取組みの目安となる時間: 360分 (6時間) 以上。
- 本科目には「中間試験」や「期末試験」がありません。それらの試験勉強時間の代替として取り組んでください。
- 想定する閲覧者: 企業でインターンシップの受け入れを審査する担当者。または、大学の研究室 (情報工学系) の夏季実習 (5日間) の受け入れを審査する大学教授。
- 提出された課題 (URL) は 知能情報コースの学生と教員、保護者に共有 します。
ポートフォリオの「構成」や「レイアウト」「デザイン」などは自由ですが、次の内容は必ず含めるようにしてください (含まれていない場合は、標準点の7.5点未満になります)。
- 所属と学年 / 年齢。最もぼかした表現としては「高専2年生」「高専生(17歳)」。これよりも詳しく記載してもOKです。
- 課題04 (自由課題)
として作成したPythonプログラムの概要説明とリンク
(GoogleColab. から GitHub にプッシュして、その
リポジトリを示すリンク あるいは Colab.
そのものへのリンク(共有設定に注意!) )。
- GoogleColab ノートブックを GitHub にプッシュする方法は 第17回講義 を参照してください。
- 今年度の高専祭展示に向けたプロジェクト活動の成果物と概要 (役割や担当)。スクリーンショットや動画、リポジトリへのリンクなど。
- プログラミング言語やソフトウェア (ウェブサービス)
に関する経験・スキルを示すもの。
- プログラミング言語としては少なくとも「Python言語」「Arduino言語」「Scratch」については学校授業レベルの使用経験があるはずです。また、ソフトウェア (ウェブサービス) としては「Git/GitHub」「VSCode (venvによるPython開発)」「ArduinoIDE」「Deeds-DCS」「MakeCode for micro:bit」「Tinkercad」「WSL (Windows Subsystem for Linux)」は全員が利用しているはずです。その他、実験班によっては「Ambient」「Real VNC」「Tera Term」「Wireshark」「Cisco Packet Tracer」なども利用しているはずです。
- 閲覧者が皆さんのスキルや経験を適切に評価できるように、明確かつ適切に記述する必要があります。誤解を招かないように (=過大評価あるいは過小評価されないように)、自身の経験やスキルを 客観的 かつ 具体的 に記載するように意識してください。
ポートフォリオの書き方や構成に「正解」は存在しません。悩むところがあれば、クラスメイトと一緒に考えたり、ChatGPT に相談したり、ウェブで公開されている多数のポートフォリオを参考にしたりしてください。