1 連絡
- 小テスト❸ を実施します。
- シラバス記載のように、小テストは最終評価の 35% に相当します。
- 遅刻・欠席等により追試験を希望する場合は第01回講義で案内した手続きをしてください
- 卒業研究の仮配属のための研究室訪問
- 23日(木)15:00-15:30 専門棟1・1階・データ処理実験室 本日
- 28日(火)16:30-17:00 専門棟1・1階・データ処理実験室
- 上記2日程で都合が合わないときは、27日までにTeamsChatで個別連絡ください。
- 研究室紹介と指導方針(学内のみ) 10/22 14:00 Update
- 第36回高専プロコン(2025年 松江大会) YouTube配信 2025/10/11・12
- 第35回高専プロコン(2024年
奈良大会)YouTube配信 2024/10/19・20
- 全国の高専生はどんなアプリやソフトを開発しているの? …リンク先の「予選資料」から概要が確認できます。
- 今回の講義内容は、前回講義の内容
(SQLの実行、
SELECT文) をひととおり理解していることを前提とします。まだ、それらの内容 (授業時間外学習のセクションを含む) を終えていない人は、まずは、そちらを終えてから取り組んでください。
2 準備
今回の講義 (授業時間外学習を含む) では、SQLの ORDER BY 句、LIMIT
句、OFFSET 句、WHERE 句、INSERT 文
について学んでいきます。
まずは、ハンズオン演習の準備として、以下の手順で、SQL実行環境の動作確認、教材の更新取得を実行してください。
2.1 SQL演習環境の動作確認 (前回復習)
- タスクトレイから Docker Desktop が起動していることを確認してください。
- 前回講義で作成したプロジェクトフォルダ (講義資料のとおりに作成していれば DB-PostgreSQL ) をVSCode で開いてください。
- VSCode のターミナルから
npm run db:upを実行して Dockerコンテナ を起動してください。 sql/04/tmp.sqlを新規作成して、SELECT * FROM s_users;という SQL文 を記述して保存してください。- 🚨「Docker
ボリュームを削除してしまった」などの理由でテーブルが存在しないときは、
npm run sql from-teacher/03/init-s_users.sqlおよびnpm run sql from-teacher/03/init-s_characters.sqlを再実行して、テーブルの作成とレコードの挿入を行なってください。
- 🚨「Docker
ボリュームを削除してしまった」などの理由でテーブルが存在しないときは、
- エディタがアクティブな状態で
[Ctrl]+[Shift]+[B]を押下して SQL を実行してください。もしくは VSCode のターミナルからnpm run sql sql/04/tmp.sqlを打ち込んで SQL を実行してください。 - 次のような結果が得られること確認してください。
id | name | age
----+-------+-----
1 | Alice | 20
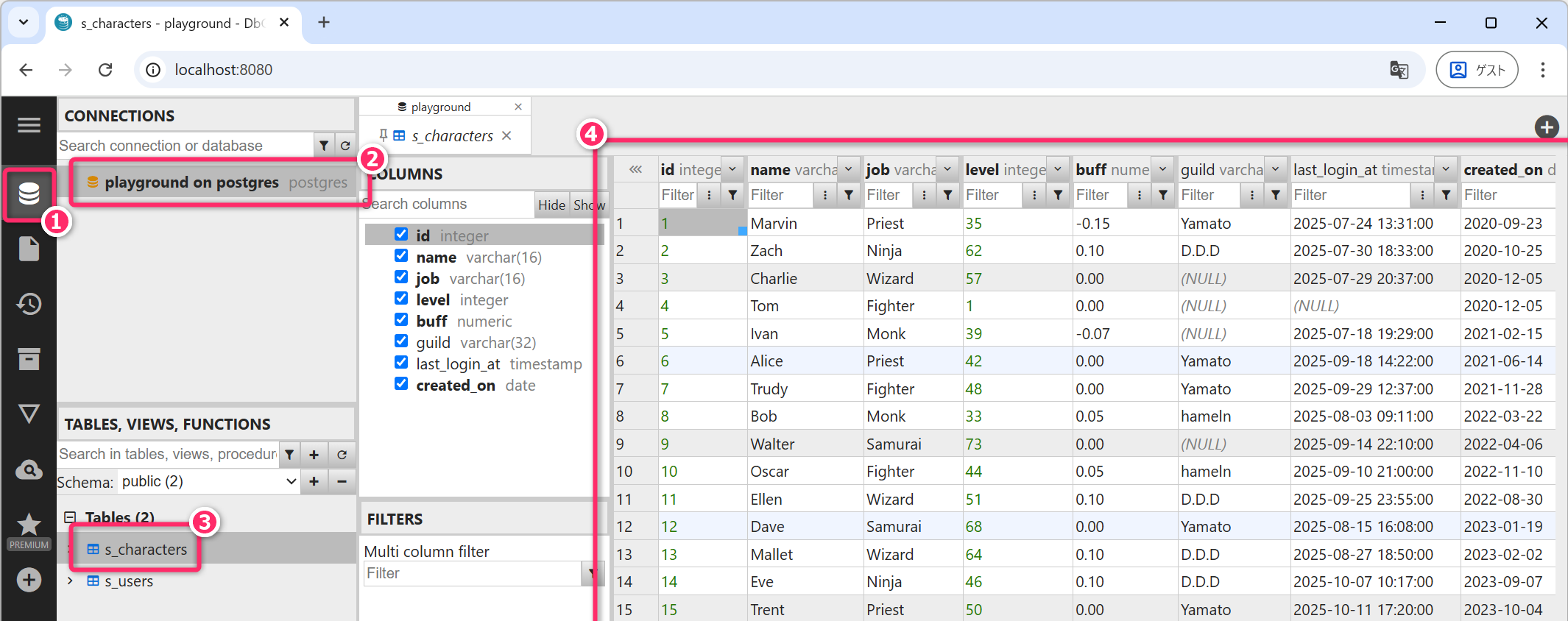
2 | Bob | 25- http://localhost:8080/もしくはhttp://127.0.0.1:8080/から DbGate に接続して、次のように s_users テーブルと characters テーブルの内容が表示できることを確認してください。
2.2 教材の更新の取得
教材リポジトリ(=皆さんが演習に使用するプロジェクトの
upstream)
が更新されています。次の手順で各自のローカルリポジトリに最新の変更を取り込んでください。
注意
更新の取り込み作業を始める前に、現在編集中のファイルはすべて保存し、さらに 未コミットの変更がない状態 にしておいてください。
VSCode のターミナルから以下のコマンドを実行してください (1行ずつ応答を確認しながら実行してください)。
git fetch upstream
git switch main
git merge upstream/main最後の git merge upstream/main
を実行すると、次のようなコミットメッセージの編集画面が開くことがあります。その場合は、内容
(コミットメッセージ) を確認して「続行」ボタンを押下してください。
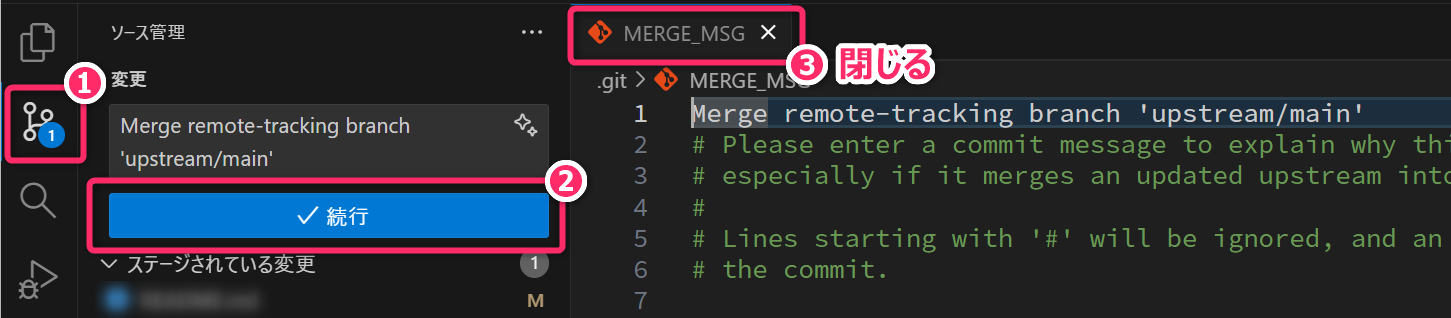
マージコミットが完了したら、MERGE_MSG のタブは閉じて問題ありません。
以上の操作完了後、プロジェクトのなかに from-teacher/04
というフォルダと、その内容 (SQLファイルなど) が追加されていることを確認してください。
3 ORDER BY 句
前回講義では、SQL の SELECT
文を使用して「テーブルからレコードを取得する方法」について学びました。その際、取得結果のレコードの「ならび」は、おそらく
id カラムの昇順になっていたと思います。
実際に、以下の SQL を実行して確かめてみてください。
- 例:
sql/04/tmp.sqlを作成して、以下のSQLをコピペして、npm run sql sql/04/tmp.sqlを実行
SELECT
id,
guild AS "所属ギルド",
name AS "名前",
level AS "レベル",
TO_CHAR(last_login_at, 'YYYY"/"MM"/"DD HH24":"MI') AS "最終ログイン"
FROM
s_characters;ここで押さえておくべき「SQLの重要な特性」があります。
SQLは「集合指向」の言語であり、「idカラムの昇順」あるいは「レコードが挿入(INSERT)された順」でレコードが得られるというのは 「たまたま」の結果 に過ぎません。実際には、取得結果のレコード (これを一般に「結果セット (result set)」とよびます) の「ならび (順序)」は 不定である (論理的に保証されるものではない) ということを覚えておいてください。
そこで、レコードの順序を保証する仕組みとして、SELECT
文には「ORDER BY句」が用意されています。
補足
PostgreSQLはデータを ヒープファイル(Heap File)
で管理しており、新しく追加された行は、通常、テーブル内の空きページや末尾のブロックに順次追加されます。そのため、テーブルスキャン
(順次読み出し)
を行うと、挿入順に近い順序で読み込まれることがよく起こります。ただし、この順序は
VACUUM や UPDATE
にともなう再配置、インデックススキャンの使用、並列処理などによって容易に崩れます。
そのため、SELECT 文の結果が、INSERT
の順番に並ぶという挙動は「たまたま」そう見えているに過ぎず、結果セットのレコード順序を意図的に制御したい場合は必ず
ORDER BY 句を使用する必要があります。
- ここでの ヒープファイル とは、アルゴリズムやデータ構造で学んだ ヒープ構造 (二分ヒープなど) とは全く別物です。データを「積み上げる(Heap)」ことに由来する用語で、特定のデータ構造を指すものではないので注意してください。
(プロンプト例)
PostgreSQL における
VACUUMとは何ですか。
3.1 ORDER BY 句
ORDER BY は、SELECT
文において、結果セットのレコードの「ならび
(順序)」を指示するもので (=整列順・ソート順
を指示するもので)、以下のように FROM 句のあとに記述します。
SELECT
id,
guild AS "所属ギルド",
name AS "名前",
level AS "レベル",
TO_CHAR(last_login_at, 'YYYY"/"MM"/"DD HH24":"MI') AS "最終ログイン"
FROM
s_characters
ORDER BY -- ◀ ここに注目
guild;SELECT文は、「SELECT句 👉FROM句 👉ORDER BY句」という順序で記述しないと構文エラーになるので注意してください。
上記の SQL の実行結果 (ORDER BY guild の結果)
は、次のように「所属ギルド順」なっていると思います。
id | 所属ギルド | 名前 | レベル | 最終ログイン
----+------------+---------+--------+------------------
17 | D.D.D | Wendy | 56 | 2025/08/08 10:56
13 | D.D.D | Mallet | 64 | 2025/08/27 18:50
2 | D.D.D | Zach | 62 | 2025/07/30 18:33
14 | D.D.D | Eve | 46 | 2025/10/07 10:17
11 | D.D.D | Ellen | 51 | 2025/09/25 23:55
1 | Yamato | Marvin | 35 | 2025/07/24 13:31
12 | Yamato | Dave | 68 | 2025/08/15 16:08
15 | Yamato | Trent | 50 | 2025/10/11 17:20
~~ 以下略 ~~- ここでは 大文字と小文字を区別した昇順 (ABC順) になっていることに注意してください。
ORDER BY は、デフォルトで ASC (昇順)
でソートします。指定されたカラムが文字列型の場合は「ABC順」、数値型の場合は「小さい順」、日時型の場合は「古い順」でソートされます。降順にしたい場合は、ORDER BY guild DESC
のように DESC キーワード を指定します。
- 昇順であることを明示したい場合は
ORDER BY guild ASCのようにします。 - PostgreSQL では、昇順 (
ASC) で整列した場合、NULL値は 最後に配置 されることに注意してください。 - 文字列の整列 (昇順) では、まずは「大文字の
A-Z」、つづいて「小文字a-z」の順にレコードが並べられるので注意してください。大文字と小文字を区別せずに整列したいときは、ORDER BY LOWER(guild)のように小文字変換の関数を使用してください。
3.1.1 演習
ORDER BY guild DESCとしたとき、NULL値は「最初に配置される」か「最後に配置される」かを確認してください。ORDER BY LOWER(guild)としたとき、「D.D.D」👉「hameln」👉「Yamato」👉「(NULL)」のように整列されることを確認してください。- レベルが低いキャラから順番にレコードがならぶように (=レベルの昇順に) SQL を書き換えてください。
- レベルが高いキャラから順番にレコードがならぶように (=レベルの降順に) SQL を書き換えてください。
- 最終ログインが最近のキャラから順番にレコードがならぶように SQL を書き換えてください。
3.1.2 定着確認
いま、s_users というテーブルに id、name
(VARCHAR(16)) 、age
(INTEGER)、birthday (DATE)
というカラムが存在している。
SELECT文において、name を ABC順 (例えば、Alice👉Bob👉Carol👉Charlie👉…のような順) にデータをならべたい。どのようにORDER BY句を記述すればよいか答えよ。- 答え:
ORDER BY name ASCもしくはORDER BY name
- 答え:
SELECT文において、age カラムを参照して年齢が高いユーザから順にデータをならべたい。どのようにORDER BY句を記述すればよいか答えよ。- 答え:
ORDER BY age DESC
- 答え:
SELECT文において、誕生日順 (過去👉現在) にデータをならべたい。どのようにORDER BY句を記述すればよいか答えよ。- 答え:
ORDER BY birthdayもしくはORDER BY birthday ASC
- 答え:
- PostgreSQL で
ORDER BYにより昇順に整列 (ソート) したとき、NULL値は「最初に配置される」か「最後に配置される」かを答えよ。- 答え: 最後に配置される
- 一般に
ASCは「昇順」と「降順」のどちらを意味するか答えよ。- 答え: 昇順
ORDER BY句においてASCやDESCを明示しないとき、デフォルト動作としては「昇順」と「降順」のどちらになるか答えよ。- 答え: 昇順
3.2 複数のソートキーの指定
ORDER BY
句では、カンマで区切って、第1ソートキー、第2ソートキー、第3ソートキー…と複数のソートキーが指定できます。例えば、まず
所属ギルドのABC順 (昇順) で整列 し、さらに
所属ギルドのなかでレベルが高い順 (降順) に整列 したい場合は、次のように SQL
を記述します。
SELECT
id,
guild AS "所属ギルド",
name AS "名前",
level AS "レベル",
TO_CHAR(last_login_at, 'YYYY"/"MM"/"DD HH24":"MI') AS "最終ログイン"
FROM
s_characters
ORDER BY -- ◀ ここに注目
guild,
level DESC;実際に実行して結果を確認してみてください。
3.2.1 SQLドリル💻
ex-01_1.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。整列の基準は、第1キーを job (昇順)、第2キーを level (降順)、第3キーを name (昇順) とすること。
id | job | level | name
----+---------+-------+---------
17 | Fighter | 56 | Wendy
7 | Fighter | 48 | Trudy
10 | Fighter | 44 | Oscar
4 | Fighter | 1 | Tom
5 | Monk | 39 | Ivan
8 | Monk | 33 | Bob
2 | Ninja | 62 | Zach
14 | Ninja | 46 | Eve
~~ 以下略 ~~ex-01_2.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。整列の基準は、第1キーを guild (昇順・大文字と小文字を区別しない)、第2キーを level (降順) とすること。
id | guild | Lv. | name (job)
----+--------+-----+------------------
13 | D.D.D | 64 | Mallet (Wizard)
2 | D.D.D | 62 | Zach (Ninja)
17 | D.D.D | 56 | Wendy (Fighter)
11 | D.D.D | 51 | Ellen (Wizard)
14 | D.D.D | 46 | Eve (Ninja)
16 | hameln | 70 | Steve (Samurai)
19 | hameln | 61 | Jack (Wizard)
~~ 中略 ~~
1 | Yamato | 35 | Marvin (Priest)
9 | | 73 | Walter (Samurai)
3 | | 57 | Charlie (Wizard)
5 | | 39 | Ivan (Monk)
18 | | 28 | Carol (Priest)
4 | | 1 | Tom (Fighter)3.3 NULL 値のソート位置を指定
先のセクションで確認したように、PostgreSQL では ORDER BY に ASC
(昇順) を指定した場合、NULL 値は最後に配置されます。逆に DESC (降順)
を指定した場合は、NULL 値が先頭に配置されます。ただし、これは PostgreSQL
固有の仕様であり、標準 SQL では NULL の整列順は 不定 (implementation-dependent) と定められています。
標準 SQL (および PostgreSQL を含む多くの実装) では、ORDER BY による整列で
NULL の位置を明示的に指定するために NULLS LAST と
NULLS FIRST というキーワードが使用できます。
例えば、次のように記述することで、最終ログイン日時が新しい順 (降順 DESC)
に並べつつ、NULL 値のレコードを「最後」に配置することができます。
- 上記の 第08行目 を
last_login_at DESC;とすると、last_login_atがNULLのレコードが先頭に配置されることを確認してください。
3.3.1 定着確認
ORDER BY句で整列順を指示する際にNULL値を先頭に配置したい。どのようなキーワードを使用すればよいか答えよ。- 答え:
NULLS FIRST(NULLではなくNULLSである点に注意)
- 答え:
ORDER BY句で整列順を指示する際にNULL値を末尾に配置したい。どのようなキーワードを使用すればよいか答えよ。- 答え:
NULLS LAST
- 答え:
3.3.2 SQLドリル💻
ex-02_1.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。整列の基準は、第1キーを guild (昇順・大文字と小文字を区別しない・NULLは先頭)、第2キーを level (昇順) とすること。
id | name | level | guild
----+---------+-------+--------
4 | Tom | 1 |
18 | Carol | 28 |
5 | Ivan | 39 |
3 | Charlie | 57 |
9 | Walter | 73 |
14 | Eve | 46 | D.D.D
11 | Ellen | 51 | D.D.D
17 | Wendy | 56 | D.D.D
2 | Zach | 62 | D.D.D
13 | Mallet | 64 | D.D.D
8 | Bob | 33 | hameln
10 | Oscar | 44 | hameln
~~以下略~~ex-02_2.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、並び順は last_login_at が新しい順 (降順・NULLは末尾) となるようにし、Days Since Last Login カラムは「2025/10/15」を基準日として、最終ログインが何日前かを出力すること。- ヒント: 前回講義 現在日時と日数・時間の差を計算する
id | name | last_login_at | Days Since Last Login
----+---------+---------------------+-----------------------
15 | Trent | 2025-10-11 17:20:00 | 4 days ago
14 | Eve | 2025-10-07 10:17:00 | 8 days ago
16 | Steve | 2025-10-06 09:14:00 | 9 days ago
18 | Carol | 2025-10-03 11:42:00 | 12 days ago
7 | Trudy | 2025-09-29 12:37:00 | 16 days ago
11 | Ellen | 2025-09-25 23:55:00 | 20 days ago
6 | Alice | 2025-09-18 14:22:00 | 27 days ago
~~ 中略 ~~
3 | Charlie | 2025-07-29 20:37:00 | 78 days ago
1 | Marvin | 2025-07-24 13:31:00 | 83 days ago
5 | Ivan | 2025-07-18 19:29:00 | 89 days ago
4 | Tom | |3.4 CASE式を使用したORDER BY句の指定
前回講義では、SELECT 句のなかでCASE式を利用する方法を紹介しましたが、CASE式は
ORDER BY 句のなかでも使用することができます。
- 式を記述できる場所であれば、どこでも「CASE式」を利用可能です
例えば、jobカラムについて、後衛職👉前衛職の順にならべ、さらに、それぞれのなかでは「ABC順」にジョブ (職業) をならべ、さらにレベル (降順) でならべたい場合は、次のようにSQLを記述します。
- 後衛職:
Priest、Wizard - 前衛職:
Fighter、Monk、Ninja、Samurai
SELECT
id,
name,
job,
level
FROM
s_characters
ORDER BY
CASE
WHEN job = 'Priest' OR job = 'Wizard' THEN 1
ELSE 2
END ASC, -- CASE式による第1キー
job, -- 第2キー
level DESC; -- 第3キーここでは、第09行目 から 第12行目
にかけての「CASE式」で後衛職に数値の「1」、それ以外 (前衛職)
に数値の「2」を割り当て、それを第1キーとして昇順 (ASC)
に並べています。つまり、ジョブ (文字列型)
を数値型にマッピングして、それを整列のキーに使用しています。
- 第10行目 は、
INキーワードを使用してWHEN job IN ('Priest', 'Wizard') THEN 1のように記述することもできます。
実行結果は、次のようになります。
id | name | job | level
----+---------+---------+-------
15 | Trent | Priest | 50
6 | Alice | Priest | 42
1 | Marvin | Priest | 35
18 | Carol | Priest | 28
13 | Mallet | Wizard | 64
19 | Jack | Wizard | 61
3 | Charlie | Wizard | 57
11 | Ellen | Wizard | 51
17 | Wendy | Fighter | 56
7 | Trudy | Fighter | 48
~~ 中略 ~~
16 | Steve | Samurai | 70
12 | Dave | Samurai | 683.4.1 SQLドリル💻
ex-03_1.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、ギルドのならびが「Yamato」、「NULL(無所属)」、それ以降は大文字と小文字を区別しない昇順 (ABC順) となるようにすること。また、各ギルド内ではレベルの降順で並ぶようにすること。- ヒント:
NULLを(無所属)という文字列で出力するためには、前回講義 で紹介したCOALESCEを利用する。
- ヒント:
id | name | level | guild
----+---------+-------+----------
12 | Dave | 68 | Yamato
15 | Trent | 50 | Yamato
7 | Trudy | 48 | Yamato
6 | Alice | 42 | Yamato
1 | Marvin | 35 | Yamato
9 | Walter | 73 | (無所属)
3 | Charlie | 57 | (無所属)
5 | Ivan | 39 | (無所属)
18 | Carol | 28 | (無所属)
4 | Tom | 1 | (無所属)
13 | Mallet | 64 | D.D.D
2 | Zach | 62 | D.D.D
17 | Wendy | 56 | D.D.D
11 | Ellen | 51 | D.D.D
14 | Eve | 46 | D.D.D
16 | Steve | 70 | hameln
19 | Jack | 61 | hameln
10 | Oscar | 44 | hameln
8 | Bob | 33 | hamelnex-03_2.sql👉 s_characters テーブルのすべてのレコードについて、次に示すようなカラムを出力する SQL を記述せよ。なお、第1キーを job (カスタム順: Samurai、Ninja、Fighter、Monk、Priest、Wizard の順)、第2キーを level (降順) とすること。
id | name | level | job
----+---------+-------+---------
9 | Walter | 73 | Samurai
16 | Steve | 70 | Samurai
12 | Dave | 68 | Samurai
2 | Zach | 62 | Ninja
14 | Eve | 46 | Ninja
17 | Wendy | 56 | Fighter
~~ 中略 ~~
18 | Carol | 28 | Priest
13 | Mallet | 64 | Wizard
19 | Jack | 61 | Wizard
3 | Charlie | 57 | Wizard
11 | Ellen | 51 | Wizard4 LIMIT 句
SQL では、LIMIT を使用して 取得するレコードの上限
を設定することができます。
SELECT文は、「SELECT句 👉FROM句 👉ORDER BY句 👉LIMIT句」という順で記述しないと構文エラーになるので注意してください。
例えば、レベルの高い順に整列して「上位5件」のレコードを取得する場合、次のように SQL を記述します。
LIMIT 30
のように、全レコード数よりも大きな値を指定するとどのようになるか、実際に確認してください。
4.1 LIMITの利用上の注意点
LIMIT 句は単独でも使用できますが、実務では ORDER BY
句と組み合わせて使うことが基本となります。ORDER BY 句なしで LIMIT
句を使用すると、その結果セットの内容は「不定」となります。
ORDER BYなしでも毎回同じ結果セットが得られるように見えることがありますが、それは 偶然にすぎず、保証された動作ではありません。
実運用では、VACUUM や UPDATE
によるデータの再配置、インデックスの利用状況、並列実行の影響などで、取得されるレコードの順序が変化する可能性があり、そこから上位
N 件分を取得する LIMIT の結果も変わります。
一方で、意図的に「N
件のレコードをランダムに取得したい」という場合には、次のように
ORDER BY RANDOM() と LIMIT
を併用します。これにより、ランダムに5件のレコードを取得することができます。
4.2 OFFSET句
LIMIT と OFFSET
を組み合わせて使用することで「ページング処理
(ページネーション)」を行なうことができます。たとえば、ある結果セットについて「101件目から150件目」だけを取得したいとき、LIMIT 50 OFFSET 100
のように利用することができます。ただし、OFFSET
でデータをスキップしても、内部的には スキップする行も含めて先頭から順次読み取り、指定された位置に到達してから結果を返す
ため、オフセット値が大きくなるほど計算コストが増大し、レスポンスタイムが悪化するという問題があります。
- 例えば
LIMIT 50 OFFSET 100とLIMIT 50 OFFSET 10000では、明らかに後者のほうがコストが大きく、パフォーマンスが悪くなります。
このようなことから、レコード数が数千、数万を超えるようなケースでは「カーソルページネーション
(キーセットページネーション)」という手法が使用されます。これは
WHERE id <【最後に表示したID】ORDER BY id LIMIT 50
のようにレコードを取得する手法になります。
この手法では、インデックス (👈詳細は次回以降に説明) を利用して条件に一致する行から直接データを取得できるため、オフセット値に依存しない安定したパフォーマンスを実現できます。つまり「101件目から150件目」を取得する場合も、「10,001件目から10,050件目」を取得する場合も、ほぼ同じコストとなります。ただし、カーソルページネーションは 特定のページ番号に直接ジャンプすることができない というデメリットがあります。
以下に「レベルの降順で整列して、11件目から15件目にあたるレコードを取得する SQL」を示します。
LIMIT 5 OFFSET 10は、順番を入れ替えてOFFSET 10 LIMIT 5としても問題ありません (構文エラーにはなりません)。ただし、一般的にはLIMIT ... OFFSET ...で記述します。PostgreSQL の公式ドキュメントでも、この順序で記載されています。
(プロンプト例)
ウェブアプリに関する文脈で「ページング処理」とはなんですか。
RDBに関する文脈で「カーソルページネーション」とは何ですか。
4.2.1 SQLドリル💻
ex-04_1.sql👉 s_characters テーブルから、id、name、job、level の 4 つカラムを持つレコードをランダムに3件取得する SQL を記述せよ。ex-04_2.sql👉 s_characters テーブルから、last_login_at が古い順に5件のレコードについて、以下のようなカラムを取得する SQL を記述せよ。なお、last_login_at がNULLであるレコード (=アカウント作成後、一度もログインされていないもの) も含めて、先頭に配置すること。
id | name | last_login_at
----+---------+---------------------
4 | Tom |
5 | Ivan | 2025-07-18 19:29:00
1 | Marvin | 2025-07-24 13:31:00
3 | Charlie | 2025-07-29 20:37:00
2 | Zach | 2025-07-30 18:33:00ex-04_3.sql👉 s_characters テーブルから、created_on を古い順 (NULLは末尾) にならべて「11件目から15件目」にあたるレコードを、以下のようなカラムで取得する SQL を記述せよ。
id | name | created_on
----+--------+------------
10 | Oscar | 2022-11-10
12 | Dave | 2023-01-19
13 | Mallet | 2023-02-02
14 | Eve | 2023-09-07
15 | Trent | 2023-10-04- 注意: s_characters テーブルの Oscar (id:
10) と Ellen (id:11) の created_on は、from-teacher/03/init-s_characters.sqlのなかで意図的に逆転させています。
4.2.2 定着確認
- あるテーブルにおいて、updated_at
カラムを降順でソートしたとき、251件目から300件目のレコードだけを取得したい。
LIMIT句 とOFFSET句をどのように与えればよいか答えよ。- 答え:
LIMIT 50 OFFSET 250
- 答え:
- 大量のデータを一度にすべて表示するのではなく、
LIMIT句とOFFSET句を組み合わせて「1ページ目」「2ページ目」のように小分けにして取得・表示する処理を何というか。- 答え: 「ページング処理」または「ページネーション」
LIMIT 50 OFFSET 100とLIMIT 50 OFFSET 10000を比較したとき、そのレスポンスタイムは、一般的に【 】。括弧にあてはまる語を「変わらない」「前者のほうが大きい」「後者のほうが大きい」から選び答えよ。- 答え: 後者のほうが大きい
5 WHERE 句
SELECT 文では、WHERE 句を使うことで 指定した条件に一致するレコードだけ
を取り出すことが可能となります。WHERE 句には、3値論理 (=
TRUE / FALSE / UNKNOWN のいずれか)
を返す「式」や「関数」を設定します。そして、WHERE 句の評価結果が TRUE となったレコードだけが抽出されます。
例えば、レベルが20以上 かつ ギルドに所属している
(=guild カラムが NULL ではない)
という条件に一致するレコードを取得する SQL は、次のように記述することができます。
SELECT
id,
name,
level,
guild
FROM
s_characters
WHERE -- ◀ ここに注目
level >= 20 AND
guild IS NOT NULL
ORDER BY
level DESC;なお、SELECT 文は、SELECT 句 👉 FROM 句 👉
WHERE 句 👉 ORDER BY 句 👉 (LIMIT 句 /
OFFSET 句) という順で記述しないと構文エラーになるので注意してください。
5.1 基本的なWHERE句
id (INTEGER型)
が「3」に一致するレコードを取得する SELECT
文は次のようになります。SQL において等価比較演算子には == ではなく =
を使用するので注意してください。
id == 3のように==を使用した場合、どのようになるか予測し、実際に結果を確認してください。id = '3'のようにシングルクォートで囲んだ場合、どのようになるか予測し、実際に結果を確認してください。
name (VARCHAR型)
が「Alice」に一致するレコードを取得する SELECT
文は次のようになります。文字列は シングルクォート '
で囲むことに注意してください。
name = Aliceのようにシングルクォートで囲まなかった場合、どのようになるか予測し、実際に結果を確認してください。
created_on (DATE型)
が「2022-03-22」に一致するレコードを取得する SELECT
文は次のようになります。日付は シングルクォート '
で囲み、YYYY-MM-DD の形式で記述してください。
created_on = '2022-3-22'のようにゼロ埋めなしの場合、どのようになるか予測し、実際に結果を確認してください。created_on = '2022/03/22'のように/区切りの場合、どのようになるか予測し、実際に結果を確認してください。created_on = '2022-03-22 12:30:00'のように時刻を含めたとき、どのようになるか予測し、実際に結果を確認してください。
last_login_at (TIMESTAMP型) が「2025-10-03
11:42:00」に一致するレコードを取得する WHERE
句は次のようになります。日付は シングルクォート '
で囲み、YYYY-MM-DD HH24:MI:SS の形式で記述してください。
last_login_at = '2025-10-03'のように時刻を含めない場合、どのようになるか予測し、実際に結果を確認してください。last_login_at = '2025-10-03 11:42'のように 00秒 の部分を省略した場合、どのようになるか予測し、実際に結果を確認してください。
(プロンプト例)
PostgreSQLに関する質問です。いま
s_charactersテーブルのidカラムはINTEGER型で定義されています。このとき、idが「3」に一致するレコードを抽出したいです。これはSELECT * FROM s_characters WHERE id = 3というSQLで実行可能なことを確認しました。しかし、これをid = '3'のように「文字列リテラル」で指定しても (予想に反して) 実行可能でした。これは、なぜですか。他の RDBMS でも同様なことが起きますか?id = 3とid = '3'のどちらが適切ですか?
PostgreSQLに関する質問です。いま
s_charactersテーブルのcreated_onカラムはDATE型で定義されています。このとき、created_onが「2022年3月22日」に一致するレコードを抽出したいです。これはSELECT * FROM s_characters WHERE created_on = '2022-03-22'というSQLで実行可能なことを確認しました。しかし、これをcreated_on = '2022/3/22'のような書式で指定しても (予想に反して) 実行可能でした。これは、なぜですか。他の RDBMS でも同様なことが起きますか?2022-03-22と2022/3/22のどちらが適切ですか?
5.1.1 定着確認
- users テーブルから、id カラム(
INTEGER型で定義)が「7」に一致するレコードについて、すべてのカラムを取得するようなSELECT文を記述せよ。なお、比較の際は、カラムのデータ型に適したリテラルを使用すること。- 答え:
SELECT * FROM users WHERE id = 7;。id = '7'は不正解。
- 答え:
- users テーブルから、name カラム(
VARCHAR型で定義)が「Bob」に一致するレコードについて、すべてのカラムを取得するようなSELECT文を記述せよ。なお、比較の際は、カラムのデータ型に適したリテラルを使用すること。- 答え:
SELECT * FROM users WHERE name = 'Bob';
- 答え:
- users テーブルから、created_on カラム(
DATE型で定義)が「令和7年5月1日」に一致するレコードについて、すべてのカラムを取得するようなSELECT文を記述せよ。なお、比較の際は、カラムのデータ型に適したリテラルを使用すること。なお、令和元年は、西暦2019年である。- 答え:
SELECT * FROM users WHERE created_on = '2025-05-01';
- 答え:
5.2 SQLの3値論理
SQL では TRUE と FALSE
に加えて、「不明・未知」を表す UNKNOWN を扱う
3値論理 (Three-Valued Logic、3VL)
が採用されています。UNKNOWN は、NULL
を含む式の評価結果が判定不能となった場合に返される値となります。
たとえば level + NULL や last_login_at = NULL などの式を評価すると、結果は
UNKNOWN となります。
IS NULLやIS NOT NULLは特別に真偽を判定できる例外的な存在です。
この UNKNOWN が混ざると、論理演算
(AND・OR・NOT)の結果も UNKNOWN
を含む形で評価されることに十分に注意してください。
5.2.1 SQLの3値論理の論理否定 (NOT)
3値論理の「論理否定」は次のようになります。
| A | NOT A |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| UNKNOWN | UNKNOWN |
実際に、この関係を確認するためには、次のような SQL を実行します。
- SQL では
UNKNOWNを明示的に記述することはできず、NULLがその値 (UNKNOWN) を表します。 - 結果セットにおいては、
TRUEは「t」、FALSEは「f」、UNKNOWN(=NULL)は「空欄」として表示されます。 - SQLでは真偽値も 大文字と小文字を区別しません。そのため
TRUEもTrueもtrueも同じです。以下の SQL では、見やすさを重視してTrue、False、Nullの表記を使用しています。
- 実際に、実行して結果を確かめてみてください。
5.2.2 SQLの3値論理の論理積 (AND)
3値論理の「論理積 (AND)」は次のようになります。
| A | B | A AND B |
|---|---|---|
| TRUE | TRUE | TRUE |
| TRUE | FALSE | FALSE |
| TRUE | UNKNOWN | UNKNOWN |
| FALSE | TRUE | FALSE |
| FALSE | FALSE | FALSE |
| FALSE | UNKNOWN | FALSE |
| UNKNOWN | TRUE | UNKNOWN |
| UNKNOWN | FALSE | FALSE |
| UNKNOWN | UNKNOWN | UNKNOWN |
UNKNOWN を含まないときは、従来の2値論理 (TRUE/FALSE)
の 論理積 (AND)
と同じ結果となります。一方、UNKNOWN が含まれる場合は、次のように考えます。
TRUE AND UNKNOWNの演算結果は、以下のようにどちらの結果にもなり得るため、UNKNOWNと考えます。- 仮に
UNKNOWNがTRUEであればTRUE AND (TRUE) 👉 TRUE - 仮に
UNKNOWNがFALSEであればTRUE AND (FALSE) 👉 FALSE
- 仮に
FALSE AND UNKNOWNの演算結果は、以下のように常にFALSEになるため、FALSEと考えます。- 仮に
UNKNOWNがTRUEであればFALSE AND (TRUE) 👉 FALSE - 仮に
UNKNOWNがFALSEであればFALSE AND (FALSE) 👉 FALSE
- 仮に
次の SQL を実行して実際に確認してみてください。
SELECT
True AND Null AS "True AND Unknown",
False AND Null AS "False AND Unknown",
Null AND Null AS "Unknown AND Unknown"; 5.2.3 SQLの3値論理の論理和 (OR)
3値論理の「論理和 (OR)」は次のようになります。
| A | B | A OR B |
|---|---|---|
| TRUE | TRUE | TRUE |
| TRUE | FALSE | TRUE |
| TRUE | UNKNOWN | TRUE |
| FALSE | TRUE | TRUE |
| FALSE | FALSE | FALSE |
| FALSE | UNKNOWN | UNKNOWN |
| UNKNOWN | TRUE | TRUE |
| UNKNOWN | FALSE | UNKNOWN |
| UNKNOWN | UNKNOWN | UNKNOWN |
UNKNOWN を含まないときは、従来の2値論理 (TRUE/FALSE)
の 論理和 (OR)
と同じ結果となります。一方、UNKNOWN が含まれる場合は、次のように考えます。
TRUE OR UNKNOWNの演算結果は、以下のように常にTRUEになるため、TRUEと考えます。- 仮に
UNKNOWNがTRUEであればTRUE OR (TRUE) 👉 TRUE - 仮に
UNKNOWNがFALSEであればTRUE OR (FALSE) 👉 TRUE
- 仮に
FALSE OR UNKNOWNの演算結果は、以下のようにどちらの結果にもなり得るため、UNKNOWNと考えます。- 仮に
UNKNOWNがTRUEであればFALSE OR (TRUE) 👉 TRUE - 仮に
UNKNOWNがFALSEであればFALSE OR (FALSE) 👉 FALSE
- 仮に
次の SQL を実行して実際に確認してみてください。
SELECT
True OR Null AS "True OR Unknown",
False OR Null AS "False OR Unknown",
Null OR Null AS "Unknown OR Unknown"; 5.3 WHERE句でよく利用する述語
SQLにおいて 3値論理 を返す「式」を 述語 (Predicate) といいます。代表的なものとして…
- 比較述語 (比較演算子)
- NULL判定述語
- IN述語 (IN演算子)
- LIKE述語 (LIKE条件、パターンマッチ演算子)
- BETWEEN述語 (BETWEEN条件、範囲演算子)
…があります。実務では、括弧内の表記で呼ばれることが多いです。
- 比較演算子:
=(等しい)、<(より小さい)、<=(以下)、>(より大きい)、>=(以上)、<>(等しくない)など。- PostgreSQL のほか、様々な RDBMS で
<>の代わりに!=を不等価演算子として使用することができます。ただし、標準 SQL で定められているのは<>のほうなので、原則として<>を使用してください。
- PostgreSQL のほか、様々な RDBMS で
- NULL判定述語:
IS NULL、IS NOT NULLなど。- NULL判定には
= NULLではなく、必ずIS NULLを使用してください。= NULLの評価結果は、常にUNKNOWNとなります。 - PostgreSQL では、
ISNULLとNOTNULLを使用することもできます。
- NULL判定には
5.3.1 IN述語 (IN演算子)
ジョブが「Priest」または「Wizard」のレコードを抽出する SQL は、IN演算子
を使用して次のように記述することができます。条件としては
job = 'Priest' OR job = 'Wizard' と同じですが より簡潔に記述できるメリット があります。
なお、文字列の比較は、大文字と小文字を区別するので注意してください。job IN ('priest', 'wizard')
のようにすると、抽出されるレコードは「0件」 になります。
また、IN は、論理否定の NOT
と組み合わせることができます。たとえば、Priest と Wizard 以外のジョブ
(つまり、Fighter、Monk、Ninja、Samurai) を抽出する SQL は次のように記述できます。
ここでは NOT job IN ('Priest', 'Wizard')
のように記述しても同じ結果が得られますが、一般には推奨されません。本科目でも、NOT IN
の記法を使用してください。
なお、WHRER 句で NOT IN を使用するとき、リストに NULL を含むと、評価結果は常に
UNKNOWNとなり、1件のレコードも抽出されなくなるので注意してください。例えば、ギルドが、Yamato、無所属
(NULL) 以外 のレコードを抽出したいとき、次の SQL
では意図した結果が得られません。実際に確認してみてください。
(プロンプト例)
SQL の WHERE では、
NOT job IN ('Priest', 'Wizard')よりもjob NOT IN ('Priest', 'Wizard')のように記述することが推奨されると言われました。なぜですか。
SQLに関する質問です。あるテーブルにギルドというカラムがあります。いま、ギルドのカラム値が
YamatoまたはNULL以外のレコードを抽出したいです。そのためにguild NOT IN ('Yamato', NULL)のように、WHERE句を書いたのですが、意図した結果がえられません。なぜ、このようなことが起きますか。
5.3.2 LIKE述語 (LIKE条件、パターンマッチ演算子)
キャラクタの名前が「C」から始まるようなレコードを抽出したいときは、LIKE
条件を使用し、次のように SQL を記述します。
ここで % (=ワイルドカード) は 0文字以上の任意文字 を表し、C%
は、大文字の「C」から始まる任意の文字列 (「C」だけの1文字の文字列を含む)
を表現しています。そのため、WHERE name LIKE 'C%' では、name
カラムが「Charlie」「Carol」「Chaplin」のようなレコードだけが抽出されます。
なお、大文字と小文字を区別するので、name
が「chris」のレコードは抽出されません。小文字を含めて抽出したいときは UPPER(name) LIKE 'C%' のようにします。
- 特定の文字で終わるレコードを抽出したいとき (後方一致検索)
は、ワイルドカード
%を前に置きます。例えば「セルゲエビッチ」「ミハイロビッチ」「ペトロビッチ」のように「ビッチ (vich) 」で終わる名前のレコードを抽出したいときはname LIKE '%vich'のようにします。 - 特定の文字を含むレコードを抽出したいとき (中間一致検索)
は、ワイルドカード
%を検索文字列の前後に配置します。たとえば、dra を含む名前を抽出したいときはLOWER(name) LIKE '%dra%'のようにします。- Dracula (ドラキュラ)、Cendral (センドラル)、Hydra (ハイドラ) などがマッチします。
5.3.3 BETWEEN述語 (BETWEEN条件、範囲演算子)
「XX 以上 YY
以下」のような範囲条件でレコードを抽出したいときは、BETWEEN
を使うことで簡潔に WHERE 句を記述することができます。
例えば、level が 20以上39以下 のレコードを抽出したい場合、次のように SQL を記述することができます。
この条件は WHERE level >= 20 AND level <= 39
と同じ意味になりますが、BETWEEN
を使うほうが可読性に優れています。なお、BETWEEN は 両端の値を含むこと に注意してください。上記の例では、レベルが
39 のレコードも 含まれます。
- Python の
range(20,39)のように上限を除外する仕様とは異なるため、混同しないように注意してください。
BETWEEN は、特に DATE 型や TIMESTAMP
型のカラムでよく使用されます。例えば、最終ログイン日時 (TIMESTAMP型)
が「2025-07-01」から「2025-07-31」までの範囲にあるレコードを抽出したいときは次のように記述します。
SELECT
id,
name,
last_login_at
FROM
s_characters
WHERE
last_login_at BETWEEN '2025-07-01 00:00:00' AND '2025-07-31 23:59:59.999999'
ORDER BY
last_login_at;- 注意:
WHERE last_login_at BETWEEN '2025-07-01' AND '2025-07-31'とすると、last_login_at が 2025年7月31日 10時15分 のようなレコードが選択されないので注意してください。- なお、last_login_at が、created_on
のように時刻を含まない
DATE型であれば、この問題は生じません。
- なお、last_login_at が、created_on
のように時刻を含まない
(プロンプト例)
PostgreSQL に関する質問です。last_login_at という
TIMESTAMP型のカラムがあります。このとき、WHERE last_login_at BETWEEN '2025-07-01' AND '2025-07-31'では、2025-07-31 10:15:00のようなレコードが選択されないのはなぜですか。
さらに、前回講義で紹介した
DATE_PART
関数と組み合わせることで、最終ログインが「9時から17時」のレコードを抽出するようなことにもできます。
SELECT
id,
name,
last_login_at
FROM
s_characters
WHERE
DATE_PART('hour', last_login_at) BETWEEN 9 AND 17
ORDER BY
CAST(last_login_at AS TIME); -- 時刻で整列DATE_PART('hour', last_login_at)は 0〜23 の整数を返すため、BETWEEN 9 AND 17は「9時台〜17時台の間」を意味します (17:59 までを含むことに注意してください)。
5.4 CASE式を使用したWHERE句の指定
CASE式は、WHERE 句でも利用することができます
(先にも述べましたが、式を記述できる場所であれば、どこでもCASE式を利用することができます)。
たとえば、ギルドに所属している場合はレベル60以上、未所属の場合はレベル30以上 のレコードを抽出したいとき、次のように SQL を記述することができます。
SELECT
id,
name,
guild,
level
FROM
s_characters
WHERE -- ◀ ここに注目
level >= CASE
WHEN guild IS NOT NULL THEN 60
ELSE 30
END
ORDER BY
level DESC;これは、次のように記述することもできます。
SELECT
id,
name,
guild,
level
FROM
s_characters
WHERE
CASE
WHEN guild IS NOT NULL AND level >= 60 THEN TRUE
WHEN guild IS NULL AND level >= 30 THEN TRUE
ELSE FALSE
END
ORDER BY
level DESC;また、CASE式を使用せずに、次のように記述することもできます。
SELECT
id,
name,
guild,
level
FROM
s_characters
WHERE
(guild IS NOT NULL AND level >= 60 ) OR
(guild IS NULL AND level >= 30 )
ORDER BY
level DESC;5.4.1 SQLドリル💻
ex-05_1.sql👉 s_characters テーブルから、buff が0.00以外のレコードを抽出して、第1キーを buff (降順)、第2キーを level (降順) でソートするような SQL を記述せよ。なお、id、name、level、buff のカラムを出力すること。
id | name | level | buff
----+--------+-------+-------
13 | Mallet | 64 | 0.10
2 | Zach | 62 | 0.10
17 | Wendy | 56 | 0.10
11 | Ellen | 51 | 0.10
14 | Eve | 46 | 0.10
16 | Steve | 70 | 0.05
19 | Jack | 61 | 0.05
10 | Oscar | 44 | 0.05
8 | Bob | 33 | 0.05
5 | Ivan | 39 | -0.07
1 | Marvin | 35 | -0.15
18 | Carol | 28 | -0.20ex-05_2.sql👉 s_characters テーブルから、name が「T」からはじまるレコードについて、以下のようなカラムを name の昇順で取得する SQL を記述せよ。
id | name | level | created_on
----+-------+-------+------------
4 | Tom | 1 | 2020-12-05
15 | Trent | 50 | 2023-10-04
7 | Trudy | 48 | 2021-11-28ex-05_3.sql👉 s_characters テーブルから、created_on が「2021年」と「2022年」のレコードについて、以下のようなカラムを created_on の昇順で取得する SQL を記述せよ。ここでは、BETWEEN述語を使用することを期待している。
id | name | level | created_on
----+--------+-------+------------
5 | Ivan | 39 | 2021-02-15
6 | Alice | 42 | 2021-06-14
7 | Trudy | 48 | 2021-11-28
8 | Bob | 33 | 2022-03-22
9 | Walter | 73 | 2022-04-06
11 | Ellen | 51 | 2022-08-30
10 | Oscar | 44 | 2022-11-10ex-05_4.sql👉 s_characters テーブルから、created_on が「2021年」と「2022年」以外のレコードについて、以下のようなカラムを created_on の昇順で取得する SQL を記述せよ。ここでは、BETWEEN述語を使用することを期待している。- ヒント:
NOTを利用する
- ヒント:
id | name | level | created_on
----+---------+-------+------------
1 | Marvin | 35 | 2020-09-23
2 | Zach | 62 | 2020-10-25
3 | Charlie | 57 | 2020-12-05
4 | Tom | 1 | 2020-12-05
12 | Dave | 68 | 2023-01-19
13 | Mallet | 64 | 2023-02-02
14 | Eve | 46 | 2023-09-07
15 | Trent | 50 | 2023-10-04
16 | Steve | 70 | 2024-01-27
17 | Wendy | 56 | 2024-03-18
18 | Carol | 28 | 2024-05-11
19 | Jack | 61 | 2024-07-125.4.2 定着確認
- 次の真理値表の空欄を埋めよ。ただし、SQL の 3
値論理に従い、
TRUE、FALSE、UNKNOWNのいずれかを答えること。- 答え:【1-1】UNKNOWN
- 答え:【1-2】TRUE
- 答え:【2-1】FALSE
- 答え:【2-2】UNKNOWN
| A | B | A AND B | A OR B |
|---|---|---|---|
| UNKNOWN | TRUE | 【1-1】 | 【1-2】 |
| UNKNOWN | FALSE | 【2-1】 | 【2-2】 |
SELECT文において、guildカラムがNULLではないレコードのみを取得したい。どのようにWHERE句を記述すればよいか。WHEREキーワードを含めて答えよ。- 答え:
WHERE guild IS NOT NULL
- 答え:
SELECT文において、guildカラムがYamatoではないレコードを取得したい (guildカラムがNULLであるレコードも含めて取得したい)。どのようにWHERE句を記述すればよいか。WHEREキーワードを含めて答えよ。- 答え:
guild <> 'Yamato' OR guild IS NULL
- 答え:
6 INSERT文 (超基礎編)
テーブルにレコードを追加するときには INSERT
文を使用します。例えば、s_users テーブルが次のようなスキーマ (構造・データ型)
のとき…
CREATE TABLE s_users (
id INT PRIMARY KEY, -- 主キー (Primary Key) 設定
name TEXT NOT NULL, -- NULL を不許可
age INT -- NULL も許可
);このテーブルに Carol (18歳) を追加する場合は、次のような
INSERT 文を記述します。
ここで、第04行目 の 3 は id
を表し、既に「Alice」と「Bob」の2名が登録されているため、次の連番として 3
を設定しています。
- id は
CREATE TABLE文においてid INT PRIMARY KEYのように 主キー設定 (Primary Key、プライマリキー) しているカラムなので、既に他のレコードで使用している1や2を設定することはできません。
ここで、実際にレコードの挿入を試してみたいのですが、上記の SQL (INSERT 文)
をそのまま実行すると、ここまでに書いてきた SELECT
文を再実行したときの結果が変わってしまうおそれ があります。そこで、ここでは
トランザクション と ロールバック という RDBMS
の仕組みを利用して、データを保護しながら INSERT 文の動きを確かめていきます。
(プロンプト例)
リレーショナルデータベースにおける主キー (Primary Key) とは何ですか。主キーには同じ値を設定できないと聞いたいのですが、なぜですか。
6.1 トランザクションとロールバックの利用
INSERT
文の動作を実際に試しながらも、データを改変しないようにするため、ここでは明示的にトランザクションを開始し、レコードの挿入と、その確認を行った後に、ロールバックによって変更を取り消す という手順をとります。
トランザクションの詳しい仕組みは今後の授業で扱うので、いまは「START TRANSACTION
から ROLLBACK
のあいだに実行された処理は、すべて取り消される
(=実際のデータベースには反映されない)」という点だけを押さえておいてください。
具体的には、次の SQL によってレコードの挿入を試しつつ、最後にロールバックによって元のデータベース状態に戻すことができます。
-- トランザクションを開始
START TRANSACTION;
-- レコードの挿入
INSERT INTO
s_users (id, name, age)
VALUES
(3, 'Carol', 18);
-- 結果の確認
SELECT * FROM s_users;
-- トランザクション開始からここまでの全処理を取り消し (ロールバック)
ROLLBACK;上記の SQL を実行してみてください。次のような結果が得られるはずです。
id | name | age
----+-------+-----
1 | Alice | 20
2 | Bob | 25
3 | Carol | 18つづいて実際のデータベースには変更 (=レコードの挿入) が反映されていないことを確認してみます。
(START TRANSACTION ~ ROLLBACK で囲まずに)
SELECT * FROM s_users;
を実行してみてください。ロールバックにより、「Carol」のレコードの挿入は取り消され、テーブルのレコードは元の2件に戻っているはず
です。
id | name | age
----+-------+-----
1 | Alice | 20
2 | Bob | 25今後しばらくは、レコードを挿入する INSERT 文、レコードを削除する
DELETE 文、レコードを更新する UPDATE 文などは
START TRANSACTION ~ ROLLBACK の範囲内で試すようにしてください。
なお、第14行目の ROLLBACK を COMMIT
に置き換えると、変更内容が確定して実際のデータベースに変更が反映されます(今回はあくまで練習なので、最後は
ROLLBACK にしてください)。
START TRANSACTION ~ ROLLBACK
で囲まずに実行してしまったときは…
次のコマンドで s_users テーブルと s_characters テーブルを初期化してください。
npm run sql from-teacher/03/init-s_users.sql
npm run sql from-teacher/03/init-s_characters.sql(プロンプト例)
リレーショナルデータベースにおいて、トランザクションおよびロールバックとは何ですか。先生から「繰り返し演習するために、INSERT文やDELETE文は
START TRANSACTION~ROLLBACKで囲んで実行するように」と指示されました。これはどういう意味でしょうか。
6.2 複数レコードの挿入
2件以上のレコードを同時に挿入したいときは、次のように VALUES 句内で
カンマ区切り でデータを記述します。実際に実行して確認してください。
START TRANSACTION;
INSERT INTO
s_users (id, name, age)
VALUES
(3, 'Carol', 18),
(4, 'Dave', NULL),
(5, 'Ellen', 17);
SELECT * FROM s_users; -- 確認
ROLLBACK;- age カラムには、
NOT NULL制約がないので 第07行目 のようにNULLを設定することができます。 - 第07行目 で、
'Dave'をNULLにすると、どのようになるか確認してください。 - 第08行目 を
(1, 'Ellen', 17)のように id が重複するようにすると、どのようになるか確認してください。
6.3 カラム指定の順序と省略
次のように INSERT INTO
句では、カラムの指定順序を任意に変更すること ができます。
また、「NULLを許容するカラム」や「デフォルト値が設定されているカラム」については、指定を省略することも可能です。
START TRANSACTION;
INSERT INTO
s_users (name, id) -- カラムの順序に注目
VALUES
('Carol', 3), -- 指定したカラム順に対応して値を記述
('Dave', 4),
('Ellen', 5);
SELECT * FROM s_users; -- 確認
ROLLBACK;実際に実行して、省略された age がどのような値になっているかを確認してください。
6.3.1 SQLドリル💻
ex-06_1.sql👉 s_characters テーブルに、以下に示すような2件のレコードを挿入する SQL を記述せよ。- from-teacher/03/init-s_characters.sql
の
INSERT文を参考にすること。 START TRANSACTION~ROLLBACKで囲んで実行すること。
- from-teacher/03/init-s_characters.sql
の
name | job | level | buff | guild | last_login_at | created_on
---------+---------+-------+-------+--------+---------------------+------------
Zoe | Paladin | 11 | 0.00 | W.Wind | 2025-10-20 15:48:00 | 2025-10-12
Justin | Archer | 2 | 0.50 | | 2025-10-23 11:28:00 | 2025-10-237 授業時間外学習の指示 (宿題)
🚨本科目は「学修単位科目」であり、1回の講義あたり「4時間相当」の授業時間外学習が求められる科目です🏃
- 次回の講義で「小テスト❹」を実施します。
- 定着確認 および SQLドリル から主に出題します。
- 講義が進行するにつれて、当然ながら小テストの内容も複雑で高度なものになっていきます。前半で、しっかりと得点をとるようにしてください。
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。
- 講義資料内の「演習」や「SQLドリル」に再度取り組んでください。特に、SQLドリル💻 は、授業時間中に1回取り組むだけでは定着しないので注意してください。