1 連絡
- 小テスト❹ を実施します。
- シラバス記載のように、小テストは最終評価の 35% に相当します。
- 遅刻・欠席等により追試験を希望する場合は第01回講義で案内した手続きをしてください。
- 今回の講義内容は、前回講義の内容をひととおり理解していることを前提とします。まだ、前回の内容 (授業時間外学習のセクションを含む) を終えていない人は、まずは、そちらから取り組んでください。
2 準備と前回の復習
2.1 ハンズオン学習の準備
次の手順でSQL演習環境の立ち上げと、教材の更新を取得してください。
- SQL演習環境の動作確認@ 第04回講義
- 教材の更新の取得@ 第04回講義
2.2 前回の復習
前回の講義では SELECT 文における ORDER BY 句、LIMIT
句、OFFSET 句、WHERE 句について学びました。
ORDER BYは、レコードの 整列順 (ソート順) を指定する ための句でした。LIMITは、取得するレコードの 件数を制限する ための句でした。OFFSETは、レコードの 取得開始位置を調整する (スキップする) ための句でした。WHEREは、抽出条件を指定する ための句でした。
これらを組み合わせることで、テーブルから「どのレコードを」「どの順で」「どの位置から」「何件だけ」取り出すかを柔軟に制御できるようになりました。
補足: WHERE の意味
SQL における WHERE
は疑問詞としての「どこ?」ではなく、「〜という場所
(〜であるような行)」という関係副詞的な用法で使われています。つまり、WHERE
句は「〜という条件に該当する行を選ぶ」という指示になります。
- I came from Japan, where I was born and raised.
また、前回講義では、テーブルにレコードを 挿入する
ための基本的な INSERT 文と、その動作/挙動を安全に確認するため の
トランザクション (START TRANSACTION ~
ROLLBACK) についても学びました。
3 トランザクション
RDBMS において、トランザクション (Transaction) とは、データの一貫性や整合性を保つために 論理的にまとめて実行されるべき一連の操作や処理のかたまり を意味します。そして、RDBMS では、トランザクションに対して…
- すべての処理を「成功」として確定させる 👉 コミット
- すべての処理を「失敗」として操作を取り消して元に戻す 👉 ロールバック
…の「いずれかの結果のみ」を保証します。
例えば、トランザクションのなかに SQL-1、SQL-2、SQL-3
という3つの SQL 文が含まれているとき…
SQL-1とSQL-2は成功し、SQL-3は失敗した
…といった 中途半端な結果が生じないように保証
する機能を持ちます。具体的には SQL-3 が失敗した時点で、RDBMS は
SQL-1 と SQL-2 の操作を無効にし、データベースを トランザクション開始前の状態 に戻します。
3.1 トランザクションが必要とされる理由 (銀行送金の例)
一般に、トランザクションは次のような場面で非常に強力に機能します。
預金管理 DB において Alice から Bob に 10,000 円を移す
この送金処理は、実際には次のような 2つの操作から構成 されます。
- Alice の口座残高から 10,000 円を減算する
- Bob の口座残高に 10,000円 を加算する
この 2 つの操作は、どちらか一方だけが成功しても正しい状態とはいえません。Alice の残高だけが減って Bob に振り込まれなければ「お金が消える」ことになってしまい、逆に Bob だけに入金されて Alice の残高が減らなければ「お金が増える」ことになってしまい、いずれも不整合な状態となります。
そこで RDBMS では、これらの2つの操作を「ひとつのトランザクション」としてまとめて扱うことで、途中でどちらかの操作が失敗した場合には、ロールバック により 全ての操作を取り消して元の状態に戻す ことで、データの整合性 (一貫性) を保つ仕組みを提供しています。逆に、すべての操作が正常に完了したときにのみ コミット により処理を確定する仕組みを提供しています。
3.2 トランザクションの使用例
ここでは s_users テーブルを使って「トランザクションの基本的な使い方」を確認していきます。まずは、次のコマンドで s_users テーブルを初期化してください。
npm run sql from-teacher/03/init-s_users.sql現在、このテーブルには、Alice と Bob
の2件のレコードが含まれます。この状態から、トランザクションを使って 3
件のレコードを挿入していきます。sql/05/tmp.sql
などの適当なファイルを作成して、以下の SQL を貼り付けて実行してください。
-- トランザクションの開始
START TRANSACTION;
-- 操作1 Carol の登録 (成功)
INSERT INTO
s_users (id, name, age)
VALUES
(3, 'Carol', 18);
-- 操作2 Dave の登録 (成功)
INSERT INTO
s_users (id, name, age)
VALUES
(4, 'Dave', NULL);
-- 操作3 Ellen の登録 (成功)
INSERT INTO
s_users (id, name, age)
VALUES
(5, 'Ellen', 17);
-- START TRANSACTION 以降の全ての操作が成功していれば「確定」
COMMIT;
-- テーブルの状態を確認
SELECT * FROM s_users;この例では、START TRANSACTION から COMMIT
までに含まれるすべての操作 (操作1から操作3) が正常完了するため、第23行目 の
COMMIT
によって処理が確定され、結果がテーブルに反映されます。コンソールには、第26行目
によって次のような結果が出力されるはずです。
START TRANSACTION
INSERT 0 1
INSERT 0 1
INSERT 0 1
COMMIT
id | name | age
----+-------+-----
1 | Alice | 20
2 | Bob | 25
3 | Carol | 18
4 | Dave |
5 | Ellen | 17
(5 行) ここで、上記の 第2行目 から 第4行目 の
INSERT 0 1 は 各操作で1件のレコードが挿入されたこと
を表す応答です。0 は、 OID (Object Identifier)
を表しています、気になる人は生成AIを使って調べてください。
- 厳密には、挿入先テーブルが OID を持つなら OID、そうでなければ
0の応答を持ちます。
(プロンプト例)
PostgreSQL 17 で、テーブルに1件のレコード挿入したとき、
INSERT 0 1のような応答が返ってきます。ここでの0は、どのような意味ですか。
つづいて、トランザクションの途中で失敗が発生する例 を確認していきます。まずは、再度、次のコマンドで s_users テーブルの内容を初期化してください (レコードを2件に戻しておきます)。
npm run sql from-teacher/03/init-s_users.sql以下の SQL を貼り付けて実行してください。このコードでは 第17行目 からの
INSERT 文に id
の重複があり、「操作3」が失敗する (=エラーが発生する)
ようになっています。
-- トランザクションの開始
START TRANSACTION;
-- 操作1 Carol の登録 (成功)
INSERT INTO
s_users (id, name, age)
VALUES
(3, 'Carol', 18);
-- 操作2 Dave の登録 (成功)
INSERT INTO
s_users (id, name, age)
VALUES
(4, 'Dave', NULL);
-- 操作3 Ellen の登録 (❌失敗 id=4 が重複)
INSERT INTO
s_users (id, name, age)
VALUES
(4, 'Ellen', 17);
-- START TRANSACTION 以降の全ての操作が成功していれば「確定」
COMMIT;
-- テーブルの状態を確認
SELECT * FROM s_users;実行結果は、次のようになります。
psql:<stdin>:20: ERROR: 重複したキー値は一意性制約"s_users_pkey"違反となります
DETAIL: キー (id)=(4) はすでに存在します。ここで注目してほしいのは、「操作1」と「操作2」についての INSERT 0 1
という応答が表示されていないこと、そして、トランザクション終了後に記述された
第26行目 の SELECT
文も実行されていないことです。
この状態で、別途 SELECT * FROM s_users; を単独で実行すると、次のような結果
(=トランザクション開始前の状態) が得られます。
id | name | age
----+-------+-----
1 | Alice | 20
2 | Bob | 25
(2 行)以上のように、トランザクションのなかでエラーが発生すると、トランザクションのなかの全ての操作が取り消され、トランザクションの開始前の状態に戻ること (=ロールバックされること) が確認できました。
3.3 明示的なロールバック
START TRANSACTION ~ COMMIT において、COMMIT
の代わりに ROLLBACK を記述すると明示的に
ロールバック をかけることができます。
-- トランザクションの開始
START TRANSACTION;
INSERT INTO
s_users (id, name, age)
VALUES
(3, 'Carol', 18);
-- テーブルの状態を確認 👉 Carol のレコードが存在する
SELECT * FROM s_users;
-- 明示的にロールバックを実行
ROLLBACK;
-- テーブルの状態を確認 👉 Carol のレコードが存在しない
SELECT * FROM s_users;注意
以下、演習のなかで UPDATE 文や DELETE
文を扱いますが、特に指示のないかぎりは「START TRANSACTION ~
ROLLBACK」の内部で処理を実行するようにしてください。
3.3.1 定着確認
- PostgreSQL において、トランザクションを開始する際に使用する SQL キーワード (2語)
を答えよ。大文字で答えること。
- 答え :
START TRANSACTION
- 答え :
- PostgreSQL において、トランザクションを取り消す (元に戻す) 際に使用する SQL
キーワードを答えよ。大文字で答えること。
- 答え :
ROLLBACK
- 答え :
- PostgreSQL において、トランザクション内の処理を確定する際に使用する SQL
キーワードを答えよ。大文字で答えること。
- 答え :
COMMIT
- 答え :
4 CSVファイルからのINSERT
前回講義では INSERT
文を使って「テーブルに 1
件ずつレコードを挿入する方法」を紹介しました。しかし、実務では、数十件から数千件といった大量データを扱うことが多く、そのようなときは「CSVファイル」を使ってデータを一括挿入することが一般的となります。
ここでは、CSVファイルを使ってデータを一括挿入する手順について説明します。
4.1 CSV ファイルの作成
テーブルにデータを挿入するための「CSVファイル」を作成します。ここでは、s_users
テーブル用に予め用意した from-teacher/05/insert-s_users.csv
(最新の教材の更新に含まれています) を使用します。
VSCode から insert-s_users.csv を開いて内容を確認してください。
なお、PostgreSQL に挿入するための CSV ファイルを作成する際は、文字コードを BOMなしのUTF-8、改行コードを「LF」に設定しておくことが推奨されます。
プロンプト例
UTF-8の「BOM付き」と「BOMなし」の違いについて教えてください。「BOM付き」が利用される場面としてはどのようなものがありますか。
4.2 CSV ファイルをコンテナに配置
insert-s_users.csv は、ホストOS (Windows) 上に存在するため、Docker
コンテナ内で動作している PostgreSQL からは直接取り込むことができません。
そのため、まずこの CSV ファイルをコンテナの /tmp/ にコピーします。VSCode
のターミナルから次のコマンドを実行してください。コマンドのなかの pg17
はdocker/docker-compose.yamlの
第04行目 で指定している PostgreSQL コンテナの「名前」になります。
docker cp from-teacher/05/insert-s_users.csv pg17:/tmp/ファイルのコピーに成功すると、次のようなメッセージが返ってきます。
Successfully copied 2.05kB to pg17:/tmp/コピーが完了したら、実際にコンテナのなかにCSVファイルが配置されたことを確認していきます。第02回講義 で紹介したように
docker container exec -it pg17 bash
コマンドを使ってコンテナに接続してもよいですが、ここでは Docker
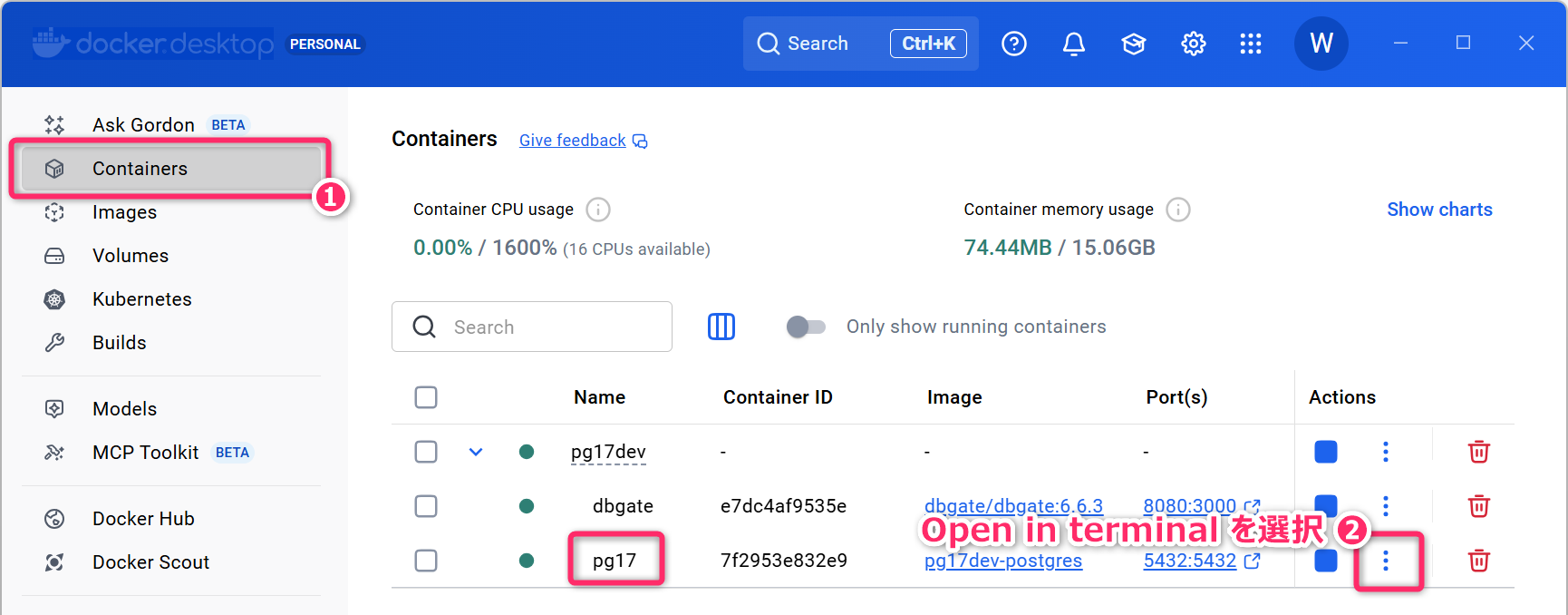
Desktop から確認する方法を紹介しておきます。
Docker Desktop のウィンドウで「Containers」を選択し、さらに「pg17」の三点リーダ から「Open in terminal」を選択してください。
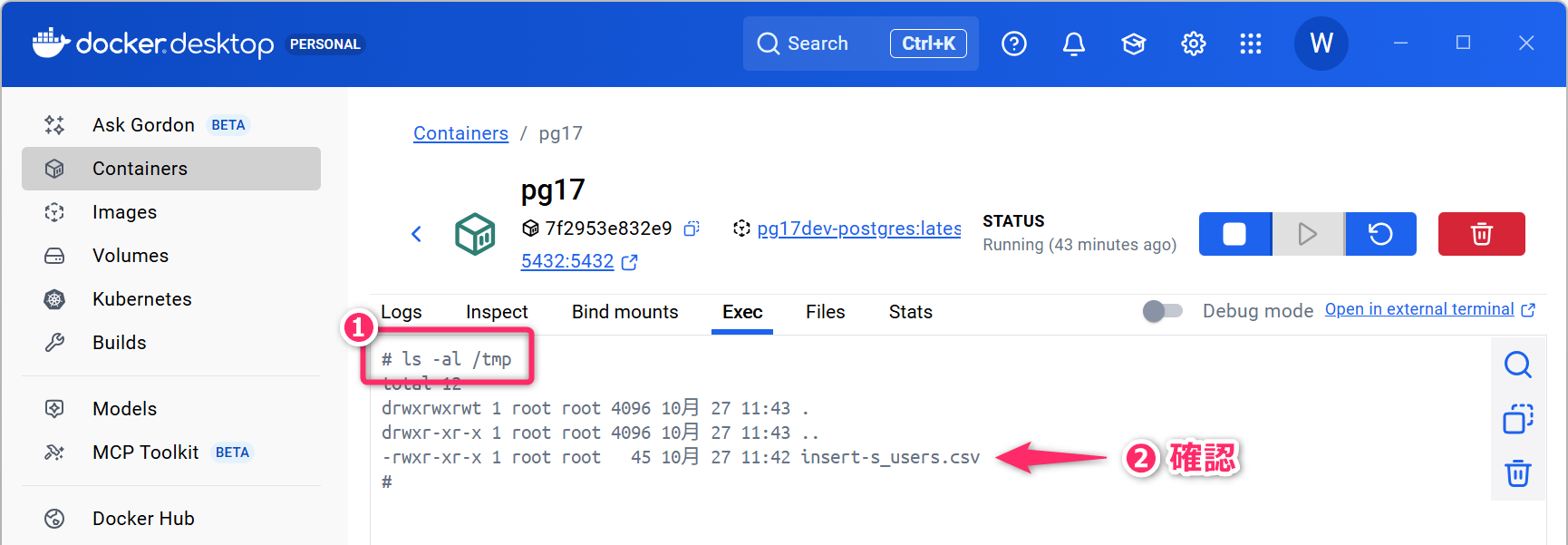
これで、コンテナの bash に接続した状態になります。ls -al /tmp
のコマンドで、コンテナ内の /tmp に CSV ファイルがあることを確認してください。
4.3 CSV ファイルからテーブルに取り込み
PostgreSQL では、以下のような SQL により、CSV ファイルからレコードを一括でテーブルに取り込むことができます。
START TRANSACTION;
-- レコード挿入前のテーブルを確認
SELECT * FROM s_users;
-- CSVファイルからレコードを挿入
COPY public.s_users (id, name, age)
FROM
'/tmp/insert-s_users.csv'
WITH
(FORMAT csv, HEADER TRUE, NULL 'NULL', ENCODING 'UTF8');
-- レコード挿入後のテーブルを確認
SELECT * FROM s_users;
ROLLBACK;COPY は PostgreSQL 独自のコマンド で、CSV
ファイルなどの外部データを 高速
に取り込むことができます。FROM 句で指定するパス (ここでは
/tmp/insert-s_users.csv) は、Docker コンテナ内のファイルパス
ということに注意してください。
また、WITH 句 (第11行目)
では以下のような設定を行っています。
FORMAT csv: ファイルが CSV 形式であることを明示HEADER TRUE: CSV の1行目をカラム名として無視NULL 'NULL': CSV 内で「NULL」という文字列を NULL 値として扱うENCODING 'UTF8': 文字コードを UTF-8 として読み込む
その他、WITH 句のオプションについては、以下の公式ドキュメントを参照してください。
(プロンプト例)
PostgreSQL において、COPY … WITH 構文で CSVファイル からテーブルにデータを取り込みたいです。このとき、CSV ファイルには、改行やカンマを含む文字列データも含めたいです。どのように CSV ファイルを作成し、また、
WITH句にはどのようなオプションを指定すればよいですか。
PostgreSQL では、COPY … WITH 構文で CSVファイルからテーブルにデータを取り込みできます。MySQL でも同じ構文でデータの取り込みができますか。
5 DELETE文 (基礎編)
テーブルからレコードを「削除」したとき DELETE 文を使用します。実際に、次の SQL
を実行してみてください。
START TRANSACTION;
-- レコードを無条件削除
DELETE FROM s_characters;
-- 確認
SELECT * FROM s_characters;
ROLLBACK;すべてのレコードが削除されたことが確認できます。
一方で、「特定の条件を満たすレコードだけ」を削除したいような場合は WHERE句
を使用します。例えば、last_login_at が、2025月7月31日以前 (NULL
を含む) のレコードだけを削除したい場合、次のようにします。
START TRANSACTION;
DELETE FROM s_characters
WHERE
last_login_at IS NULL OR
last_login_at <= '2025-07-31';
-- 確認
SELECT
id,
name,
last_login_at
FROM
s_characters
ORDER BY
last_login_at;
ROLLBACK;実行結果は、次のようになります。以下の 第02行目 の DELETE 5
という応答から 5件のレコードが削除されたこと が確認できます。
START TRANSACTION
DELETE 5
id | name | last_login_at
----+--------+---------------------
8 | Bob | 2025-08-03 09:11:00
17 | Wendy | 2025-08-08 10:56:00
12 | Dave | 2025-08-15 16:08:00
13 | Mallet | 2025-08-27 18:50:00
19 | Jack | 2025-09-02 15:43:00
10 | Oscar | 2025-09-10 21:00:00
9 | Walter | 2025-09-14 22:10:00
6 | Alice | 2025-09-18 14:22:00
11 | Ellen | 2025-09-25 23:55:00
7 | Trudy | 2025-09-29 12:37:00
18 | Carol | 2025-10-03 11:42:00
16 | Steve | 2025-10-06 09:14:00
14 | Eve | 2025-10-07 10:17:00
15 | Trent | 2025-10-11 17:20:00
(14 行)
ROLLBACK5.0.1 SQLドリル💻
ex-01_1.sql👉 s_characters テーブルのレコードについて、2025年10月15日を起算日として60日以上ログインがなかったレコードを削除する SQL を記述せよ。DATE型の「2025年10月15日」は、CAST('2025-10-15' AS DATE)またはDATE '2025-10-15'で得ることができます。
ex-01_2.sql👉 s_characters テーブルのレコードについて、last_login_at がNULLで、created_on が2023年12月31日以前のレコードを削除する SQL を記述せよ。ex-01_3.sql👉 s_characters テーブルのレコードについて、id が「3」「5」「8」「9」「10」「14」の6件のレコードを削除する SQL を記述せよ。
6 UPDATE文 (基礎編)
既存のレコードを更新したいときは UPDATE 文を使用します。DELETE
文と INSERT 文の組み合わせによっても、実質的に同様の処理は可能ですが、通常は
UPDATE 文を使用します。
6.1 すべてのレコードの値を固定値で更新
たとえば、s_characters
テーブルの全てのレコードについて、バフ解除 (buff を
0.0 に上書き) するためには、次のように SQL を記述します。
START TRANSACTION;
-- 更新前のレコードを確認 (省略)
-- 更新処理
UPDATE s_characters
SET
buff = 0.0;
-- 更新後のレコードを確認 (省略)
ROLLBACK;実行すると UPDATE 19 のような応答が表示されます。このとき、もともと
0.0 であったレコードについても、再度 0.0
に上書きされ、処理件数に含まれている点に注意してください。
6.1.1 SQLドリル💻
ex-02_1.sql👉 上記SQLの「更新前のレコードを確認 (省略)」と「更新後のレコードを確認 (省略)」の箇所に、実際に更新処理が確認できるようなSELECT文を記述せよ。
6.2 特定のレコードのみを更新
特定のレコードを指定して値を更新する場合は、WHERE
句を使用します。なお、UPDATE 文の SET 句では、カンマで区切って 複数のカラムを同時に更新すること ができます。
たとえば、id が「1」と「2」のキャラクタについて、guild
カラムを NULL にして、job カラムを Exile
(亡命者・追放者) に変更するには、次のように SQL を記述します。
START TRANSACTION;
-- 更新前のレコードを確認 (省略)
-- 更新処理
UPDATE s_characters
SET
guild = NULL,
job = 'Exile'
WHERE
id IN (1, 2);
-- 更新後のレコードを確認 (省略)
ROLLBACK;実行すると UPDATE 2 という応答が表示されます
(2件のレコードが更新されたことが分かります)。更新後のレコードを確認する SELECT
文を記述すると次のように表示されます。
id | name | job | guild
----+---------+---------+--------
1 | Marvin | Exile |
2 | Zach | Exile |
~~以下略~~6.2.1 SQLドリル💻
ex-02_2.sql👉 s_characters テーブルの job カラムについてWizardをMageに更新する SQL を記述せよ。
6.3 現在の値を利用した更新
UPDATE 文では 現在のカラム値
を参照した更新も可能です。たとえば、level を 現在値+2
にするには、次のように SQL を記述します。
- 実際に実行するときは
START TRANSACTION~ROLLBACKの内部で実行してください。
また、同じレコードのなかの「他のカラム値」を参照して更新することもできます。たとえば、buff
を SQRT(100-level)*0.05 に設定するには、次のように SQL を記述します。
SQRTは平方根を計算する関数です。
6.3.1 SQLドリル💻
ex-02_3.sql👉 ソロプレイ前衛職応援キャンペーン🎉として、guild がNULLで、job が Fighter、Monk、Samurai、Ninja のキャラクタの buff を現在値+0.25(25%Up) に更新するような SQL を記述せよ。また、更新の前後の buff カラムなどを確認する SQL も記述すること。ex-02_4.sql👉 おかえりなさいキャンペーン🎉として、2025年10月15日を基準日とし、最終ログイン日からの経過日数に応じて buff の値を更新 (上書き) するような SQL を記述せよ。- 最終ログイン日から 60日以上 経過していれば buff を
0.40 - 最終ログイン日から 40日以上 経過していれば buff を
0.30 - 最終ログイン日から 20日以上 経過していれば buff を
0.20 - 最終ログイン日から 10日以上 経過していれば buff を
0.10 - それ以外は buff を
0.00に設定
- 最終ログイン日から 60日以上 経過していれば buff を
6.4 CASE式による同時置換処理
s_characters テーブルの job カラムについて、(ハロウィン仮装イベント🎃として) Priest なら Wizard に更新し、Wizard なら Priest に更新するような処理 (つまり、Priest ↔︎ Wizard の入れ替え処理) を考えます。
この処理を次のように2回に分けて実行すると、期待する結果をえることができません。
START TRANSACTION;
-- 更新前のレコードを確認
SELECT
id,
name,
job
FROM
s_characters
WHERE
job IN ('Wizard', 'Priest')
ORDER BY
id;
-- 更新処理 👉 Priest ならば Wizard に変更
UPDATE s_characters
SET
job = 'Wizard'
WHERE
job = 'Priest';
-- 更新処理 👉 Wizard ならば Priest に変更
UPDATE s_characters
SET
job = 'Priest'
WHERE
job = 'Wizard';
-- 更新後のレコードを確認
SELECT
id,
name,
job
FROM
s_characters
WHERE
job IN ('Wizard', 'Priest')
ORDER BY
id;
ROLLBACK;実行結果は、次のようになります。期待したジョブの入れ替えとはならず、全員が Priest になってしまっています。
START TRANSACTION
id | name | job
----+---------+--------
1 | Marvin | Priest
3 | Charlie | Wizard
6 | Alice | Priest
11 | Ellen | Wizard
13 | Mallet | Wizard
15 | Trent | Priest
18 | Carol | Priest
19 | Jack | Wizard
(8 行)
UPDATE 4
UPDATE 8
id | name | job
----+---------+--------
1 | Marvin | Priest
3 | Charlie | Priest
6 | Alice | Priest
11 | Ellen | Priest
13 | Mallet | Priest
15 | Trent | Priest
18 | Carol | Priest
19 | Jack | Priest
(8 行)
ROLLBACKこのような場合、いったん別の値に退避してから入れ替える方法でも対応できますが、次のように CASE式 を使用することで、より簡潔に SQL を記述することができます。
START TRANSACTION;
-- 更新前のレコードを確認 (省略)
-- 更新処理 👉 Priest と Wizard を入れ替え
UPDATE s_characters
SET
job = CASE
WHEN job = 'Priest' THEN 'Wizard'
ELSE 'Priest'
END
WHERE
job IN ('Wizard', 'Priest');
-- 更新後のレコードを確認 (省略)
ROLLBACK;これにより、以下のように意図したジョブの入れ替えができます。
id | name | job
----+---------+--------
1 | Marvin | Wizard
3 | Charlie | Priest
6 | Alice | Wizard
11 | Ellen | Priest
13 | Mallet | Priest
15 | Trent | Wizard
18 | Carol | Wizard
19 | Jack | Priest6.4.1 SQLドリル💻
ex-02_5.sql👉 s_characters テーブルについて、前衛職のジョブを次のように入れ替えるための SQL を記述せよ。- Fighter を Monk に変更
- Monk を Samurai に変更
- Samurai を Ninja に変更
- Ninja を Fighter に変更
6.5 補足: RETURNING句
PostgreSQL では、UPDATE 文や DELETE 文を実行した際、変更後
(または削除した) レコードの内容を即座に取得できる RETURNING
句という構文があります。通常の UPDATE 文は、UPDATE 2
のように件数だけを返しますが、RETURNING を使うと 変更後のレコードを受け取り、任意のカラムを出力すること ができます。
START TRANSACTION;
UPDATE s_characters
SET
buff = 0.3
WHERE
level < 40
RETURNING -- ◀ ここに注目
id,
name,
level,
buff;
ROLLBACK;実行結果は次のようになります。
START TRANSACTION
id | name | level | buff
----+--------+-------+------
1 | Marvin | 35 | 0.30
4 | Tom | 1 | 0.30
5 | Ivan | 39 | 0.30
8 | Bob | 33 | 0.30
18 | Carol | 28 | 0.30
(5 行)
UPDATE 5
ROLLBACK7 集約関数 (Aggregate Function)
SQL
には、COUNT、SUM、MIN、MAX、AVG
などの
集約処理(集計処理)を実行する関数が用意されています。これらは一般に
集約関数 (Aggregate Function、集計関数とも呼ばれる)
と呼ばれ、基本的には SELECT 句および、後で解説する HAVING
句のなかだけで使用することができます。
7.1 COUNT関数
COUNT 関数は、引数として指定したカラムのうち、NULL
ではないレコード数を求める関数となります。ただし、引数にアスタリスク
* を指定した場合は、テーブル全体のレコード件数を取得します
(このとき、すべてのカラムが NULL
のレコードがあっても、それを「1」とカウントします)。
次の SQL の実行結果を予想し、その後、実際に実行して結果を確認してください。
SELECT
COUNT(*) AS "num_record",
COUNT(name) AS "num_name",
COUNT(guild) AS "num_guild",
COUNT(last_login_at) AS "num_last_login_at"
FROM
s_characters;実際の実行結果は次のようになります。
num_record | num_name | num_guild | num_last_login_at
------------+----------+-----------+-------------------
19 | 19 | 14 | 18 s_characters には 19件 のレコードが存在するので、COUNT(*)
は「19」となります。また、name カラムは NULL が許可されないので
(=NULL のフィールドを含まないので)、COUNT(name) は
COUNT(*) と同じく「19」となります。
一方で、guild カラムは NULL
を許可しており、5名がギルド無所属のため COUNT(guild)
は「14」となります。また、last_login_at には、1件の NULL
を含むので COUNT(last_login_at) は「18」となります。
7.1.1 重複を無視する
COUNT 関数では、引数に指定するカラム名の前に DISTINCT
キーワードをつけることができます。DISTINCT は、第03回講義で学んだように 重複を省く ためのキーワードであり、COUNT
関数のなかで使用することで、重複を除いた値の件数 を数えることができます。
次の SQL の実行結果を予想し、その後、実際に実行して結果を確認してください。
SELECT
COUNT(*) AS "num_record",
COUNT(DISTINCT job) AS "num_job_distinct",
COUNT(DISTINCT guild) AS "num_guild_distinct"
FROM
s_characters;実際の実行結果は次のようになります。
num_record | num_job_distinct | num_guild_distinct
------------+------------------+--------------------
19 | 6 | 3いま job
カラムには「Fighter」「Monk」「Samurai」「Ninja」「Wizard」「Priest」の6種類が存在するため
COUNT(DISTINCT job) は「6」となります。
また、guild
カラムには「Yamato」「D.D.D」「hameln」「NULL」の4種類が存在しますが NULL はカウントされない ため
COUNT(DISTINCT guild) は「3」となります。
7.1.2 SQLドリル💻
ex-03_1.sql👉 s_characters テーブルから次のような結果セットを得る SQL を記述せよ。
ジョブ種
----------
6種類ex-03_2.sql👉 s_characters テーブルから次のような結果セットを得る SQL を記述せよ。
ギルド所属 | 無所属
------------+--------
14人 | 5人7.2 SUM関数とAVG関数
SUM
関数は引数として指定したカラムの「合計」を求める関数、AVG
関数は引数として指定したカラムの「平均」を求める関数となります。いずれも、数値型のカラムだけ を引数にとることができます。
- いずれの関数も
COUNT関数のように、アスタリスク*を引数にとることはできません。 - いずれの関数も
NULLは除外されます。例えば、num というカラムがあったとして、その値が3、5、NULLのときAVG(num)は \((3+5)/2\) で4となります。
次の SQL の実行結果を予想し、その後、実際に実行して結果を確認してください。
実際の実行結果は次のようになります。なお、上記の第02行目の
ROUND は第03回講義で紹介したように四捨五入を適用する関数になります。
avg_level | sum_level
-----------+-----------
48.8 | 9287.2.1 NULL値を特定値に置き換えて合計や平均を求めたい場合
NULL を特定の数値に置き換えて SUM 関数や AVG
関数を適用したい場合、COALESCE 関数を組み合わせます。
次の SQL は、age カラムが NULL のとき、それを 16
に置き換えて合計と平均を適用するものです。実行結果を予想し、その後、実際に実行して結果を確認してください。
START TRANSACTION;
INSERT INTO
s_users (id, name, age)
VALUES
(3, 'Carol', 18),
(4, 'Dave', NULL),
(5, 'Ellen', 17);
SELECT * FROM s_users;
SELECT
SUM(age) AS "sum",
SUM(COALESCE(age, 16)) AS "sum_with_default",
ROUND(AVG(age), 1) AS "avg",
ROUND(AVG(COALESCE(age, 16)), 1) AS "avg_with_default"
FROM
s_users;
ROLLBACK;実際の実行結果は次のようになります。
START TRANSACTION
INSERT 0 3
id | name | age
----+-------+-----
1 | Alice | 20
2 | Bob | 25
3 | Carol | 18
4 | Dave |
5 | Ellen | 17
(5 行)
sum | sum_with_default | avg | avg_with_default
-----+------------------+------+------------------
80 | 96 | 20.0 | 19.2
(1 行)
ROLLBACK7.2.2 SQLドリル💻
ex-03_3.sql👉 s_characters テーブルから、次のようにギルド無所属 (=guild がNULL) のキャラクタについて、レベルの平均と合計を求める SQL を記述せよ。ただし、レベルの平均は小数第3位を四捨五入して、小数第2位まで表示すること。- ヒント : ギルド無所属のキャラクタだけを対象にするには
WHERE句を利用する
- ヒント : ギルド無所属のキャラクタだけを対象にするには
無所属平均Lv | 無所属合計Lv
--------------+--------------
39.60 | 198ex-03_4.sql👉 s_characters テーブルから、前衛職 (Fighter、Monk、Samurai、Ninja) の人数と平均レベル、後衛職 (Wizard、Priest) の人数と平均レベルを求める SQL を記述せよ (現時点までに学んでいる範囲では、2つのSELECT文を記述する必要がある)。ただし、レベルの平均は小数第2位を四捨五入して、小数第1位まで表示すること。
前衛職人数 | 前衛職平均Lv
------------+--------------
11 | 49.1
後衛職人数 | 後衛職平均Lv
------------+--------------
8 | 48.57.3 MAX関数とMIN関数
MAX 関数と MIN
関数は、引数として指定したカラムの「最大値」と「最小値」を求める関数となります。いずれの関数も、数値型の他、日時型
(DATEやTIMESTAMP)、文字列型などのカラムに適用することができます。
- いずれの関数も
COUNT関数のように、アスタリスク*を引数にとることはできません。 - いずれの関数も
NULLは除外されます。 - 日時型に適用した場合、
MAXは最も未来の値 (降順に整列した先頭) 、MINは最も過去の値 (昇順に整列した先頭) を返します。 - 文字列に適用した場合、
MAXは辞書順の最後 (=昇順に並べたときの末尾) の値を、MINは辞書順の最初 (=昇順に並べたときの先頭) の値を返します。
次の SQL の実行結果を予想し、その後、実際に実行して結果を確認してください。
SELECT
MIN(level) AS "min_lv.",
MAX(level) AS "max_lv.",
MIN(name) AS "min_name",
MAX(name) AS "max_name"
FROM
s_characters;
SELECT
MIN(created_on) AS "min_created_on",
MAX(created_on) AS "max_created_on"
FROM
s_characters;実際の実行結果は次のようになります。
min_lv | max_lv | min_name | max_name
--------+--------+----------+----------
1 | 73 | Alice | Zach
(1 行)
min_created_on | max_created_on
----------------+----------------
2020-09-23 | 2024-07-12
(1 行)7.3.1 文字数のカウント
文字列型に対して、文字数をカウントしたい場合 は LENGTH
関数を使用します。次の SQL
の実行結果を予想し、その後、実際に実行して結果を確認してください。
実際の実行結果は次のようになります。
min_len_name | max_len_name
--------------+--------------
3 | 7EX: 最も短い名前と最も長い名前を取得する
今後の講義で学ぶ「サブクエリ」というものを利用すると、テーブルのなかから「最も短い名前」や「最も長い名前」を抽出することができます。
SELECT
name AS "最も短い名前"
FROM
s_characters
WHERE
LENGTH(name) = (
SELECT
MIN(LENGTH(name))
FROM
s_characters
);
SELECT
name AS "最も長い名前"
FROM
s_characters
WHERE
LENGTH(name) = (
SELECT
MAX(LENGTH(name))
FROM
s_characters
);実行結果は次のようになります。
最も短い名前
--------------
Tom
Bob
Eve
(3 行)
最も長い名前
--------------
Charlie
(1 行)7.3.2 SQLドリル💻
ex-03_5.sql👉 s_characters テーブルから、次に示すように buff カラムの「最小値」「最大値」「最大値と最小値の差」を求める SQL を記述せよ。
min_buff | max_buff | max-min
----------+----------+---------
-0.20 | 0.10 | 0.30ex-03_6.sql👉 s_characters テーブルにおいて、最も長いギルド名が何文字かを求める SQL を記述せよ。ただし、guild カラムのNULL値はFreelancerという文字列に置き換えて評価すること。現時点では、ギルド名が小文字に変換されていても問題ない。
8 GROUP BY
SELECT 文に GROUP BY 句を使うと
指定したカラムでグループ化処理を行い、各グループに対して集約関数を適用することができます。
例えば、job ごとに「人数」「最大レベル」「平均レベル」を求める SQL
は次のようになります。なお、GROUP BY 句に指定するカラムのことを 集約キー と言います。
SELECT
job,
COUNT(*) AS "num",
MAX(level) AS "max_lv",
ROUND(AVG(level),1) AS "avg_lv"
FROM
s_characters
GROUP BY
job -- ◀ job でグループ化処理
ORDER BY
job;実行結果は、次のようになります。
job | num | max_lv | avg_lv
---------+-----+--------+--------
Fighter | 4 | 56 | 37.3
Monk | 2 | 39 | 36.0
Ninja | 2 | 62 | 54.0
Priest | 4 | 50 | 38.8
Samurai | 3 | 73 | 70.3
Wizard | 4 | 64 | 58.3なお、SELECT 文は、SELECT 句 👉 FROM 句 👉
WHERE 句 👉 GROUP BY 句 👉 ORDER BY 句 👉
(LIMIT 句 / OFFSET 句)
という順で記述しないと構文エラーになるので注意してください。
8.0.1 集約キーにNULLが含まれる場合の挙動
集約キー (GROUP BY で指定するカラム) に NULL
が含まれる場合、NULL
も「ひとつのグループ」として扱われます。これも、実際に実行結果をみたほうが分かりやすいと思います。
値に NULL を含む guild カラムを「集約キー」に使用します。
SELECT
guild,
COUNT(*) AS "num",
MAX(level) AS "max_lv",
ROUND(AVG(level),1) AS "avg_lv"
FROM
s_characters
GROUP BY
guild -- ◀ guild を集約キーに指定
ORDER BY
LOWER(guild); -- ◀ 大文字と小文字を区別せずに整列実行結果は、次のようになります。
guild | num | max_lv | avg_lv
--------+-----+--------+--------
D.D.D | 5 | 64 | 55.8
hameln | 4 | 70 | 52.0
Yamato | 5 | 68 | 48.6
| 5 | 73 | 39.6最終行に guild が NULL のキャラクタ
(ギルド無所属のキャラクタ) に対する集計が出力されています。NULL
は空欄で表示されるので、任意の文字列に置き換えたいときは COALESCE
を使用します。
例えば、SELECT 句の guild を
COALESCE(guild,'Freelancer') AS "guild"
に書き換えると以下のような結果を得ることができます。
guild | num | max_lv | avg_lv
------------+-----+--------+--------
D.D.D | 5 | 64 | 55.8
hameln | 4 | 70 | 52.0
Yamato | 5 | 68 | 48.6
Freelancer | 5 | 73 | 39.68.0.2 SQLドリル💻
ex-04_1.sql👉 s_characters テーブルから、次のような結果セットを得る SQL を記述せよ。- guild が
NULLのグループを先頭に配置して「無所属」というエイリアスを設定すること。 - guild が
Yamatoのグループを結果セットに含めないこと。
- guild が
guild | num | max_lv | mim_lv | max_buff | min_buff
--------+-----+--------+--------+----------+----------
無所属 | 5 | 73 | 1 | 0.00 | -0.20
D.D.D | 5 | 64 | 46 | 0.10 | 0.10
hameln | 4 | 70 | 33 | 0.05 | 0.05ex-04_2.sql👉 s_characters テーブルから、次のような結果セットを得る SQL を記述せよ。- 平均レベルの降順に整列 (ソート) すること。
job | num | avg_lv
---------+-----+--------
Samurai | 3 | 70.3
Wizard | 4 | 58.3
Ninja | 2 | 54.0
Priest | 4 | 38.8
Fighter | 4 | 37.3
Monk | 2 | 36.08.1 GROUP BY句の使用時にSELECT句で指定可能な値 (重要🚨)
GROUP BY 句を使用したとき、SELECT
句に記述可能なカラムは「GROUP BY で指定したカラム (=集約キー)
に限られる」というルールがあります。たとえば、GROUP BY job
としたとき、SELECT 句にそのまま記述できるカラムは job だけでであり、id や
level、name、guild
などを直接指定することはできません。それらを利用したい場合は、MAX(id) や
AVG(level) のように集約関数 (グループごとに計算する関数)
を適用する必要があります。
実際に、次の SQL が「エラーになること」を確認してください。
実行結果は、次のようになります。
psql:<stdin>:7: ERROR: 列"s_characters.level"はGROUP BY句で指定するか、集約関数内で使用しなければなりません英語環境では次のようになります。
psql:<stdin>:7: ERROR: column "s_characters.level" must appear in the GROUP BY clause or be used in an aggregate function第03行目 の level を、集約関数を適用した形 (たとえば
MAX(level) や AVG(level))
にすると問題なく実行できることを確認してください。
(プロンプト例)
SQLにおいて、
GROUP BY句に指定したカラム以外を、SELECT句に指定するとエラーになるのはなぜですか。たとえば、SELECT job, level FROM characters GROUP BY job;がエラーになるのはなぜですか。
8.2 GROUP BY句に複数の集約キーを指定
GROUP BY句には、以下のように 複数のカラム を指定することができます。
SELECT
COALESCE(guild, '(Freelancer)') AS "guild",
job,
COUNT(*)
FROM
s_characters
GROUP BY
guild,
job
ORDER BY
guild,
job;実行結果は次のようになります。実行結果からわかるように、まず guild ごとにグループ化され、その内部でさらに job ごとにグループ化されています。つまり、2つのカラムを組み合わせて「ギルド×ジョブ」単位で件数を集計できていることが確認できます。
guild | job | count
--------------+---------+-------
(Freelancer) | Fighter | 1
(Freelancer) | Monk | 1
(Freelancer) | Priest | 1
(Freelancer) | Samurai | 1
(Freelancer) | Wizard | 1
D.D.D | Fighter | 1
D.D.D | Ninja | 2
D.D.D | Wizard | 2
Yamato | Fighter | 1
Yamato | Priest | 3
Yamato | Samurai | 1
hameln | Fighter | 1
hameln | Monk | 1
hameln | Samurai | 1
hameln | Wizard | 1GROUP BYの集約キーの順序を変えても (すなわちGROUP BY guild, jobをGROUP BY job, guildに変更しても)、結果セットが同じになることを確認してください。- ただし
ORDER BY句を指定しない場合、整列順が変わる可能性があります。
- ただし
(プロンプト例)
SQLにおいて、
GROUP BY guild, jobをGROUP BY job, guildに書き換えても (ORDER BY句が指定されている限りは)、結果セットが変わらないのはなぜですか。集約キーの順番は関係ないのですか。
8.2.1 SQLドリル
ex-04_3.sql👉 s_characters テーブルから、次のような結果セットを得るような SQL を記述せよ。- 後衛職 (Priest、Wizard) のみを対象とすること。
job | guild | count | avg_lv
--------+--------+-------+--------
Priest | Yamato | 3 | 42.3
Priest | | 1 | 28.0
Wizard | D.D.D | 2 | 57.5
Wizard | hameln | 1 | 61.0
Wizard | | 1 | 57.08.3 ROLLUPによる全体集計
GROUP BY
でカテゴリ別に集計したときに、「レコード全体の集計」も同時に出力したいときは、ROLLUP
という GROUP BY
句の拡張構文を使用します。たとえば、以下のようにすると「guild
ごとの集計」に「全体の集計」を加えた結果セットを取得することができます。
SELECT
guild,
ROUND(AVG(level), 1) AS "avg_lv",
COUNT(*) AS "num"
FROM
s_characters
GROUP BY
ROLLUP (guild) -- ◀ ここに注目
ORDER BY
guild;実行結果は、次のようになります。結果セットの第5行目 ( num が
5 の行) が guild が NULL
のキャラクタの集計、第4行目 ( num が 19 の行)
がテーブル全体の集計となります。
guild | avg_lv | num
--------+--------+-----
D.D.D | 55.8 | 5
Yamato | 48.6 | 5
hameln | 52.0 | 4
| 48.8 | 19
| 39.6 | 5空欄を別の文字に置き換えたいときは、次のように GROUPING 関数と
CASE式 を組み合わせて利用します。ここで GROUPING(guild)
は、集計行なら1、通常行なら 0 を返す特殊関数です。
SELECT
CASE
WHEN GROUPING(guild) = 1 THEN '(Total)'
WHEN guild IS NULL THEN '(Freelancer)'
ELSE guild
END AS "guild",
ROUND(AVG(level), 1) AS "avg_lv",
COUNT(*) AS "num"
FROM
s_characters
GROUP BY
ROLLUP (guild)
ORDER BY
guild;実行結果は次のようになります。
guild | avg_lv | num
--------------+--------+-----
(Freelancer) | 39.6 | 5
(Total) | 48.8 | 19
D.D.D | 55.8 | 5
Yamato | 48.6 | 5
hameln | 52.0 | 4EX: 並び順も厳密に制御したいときは…
次のように ORDER BY 句のなかで、GROUPING 関数と
CASE式 を組み合わせて利用します。
SELECT
CASE
WHEN GROUPING(guild) = 1 THEN '(Total)'
WHEN guild IS NULL THEN '(Freelancer)'
ELSE guild
END AS "guild",
ROUND(AVG(level), 1) AS "avg_lv",
COUNT(*) AS "num"
FROM
s_characters
GROUP BY
ROLLUP (guild)
ORDER BY
CASE -- ◀ ここからを注目
WHEN GROUPING(guild) = 1 THEN 3 -- 整列順第3位
WHEN guild IS NULL THEN 2 -- 整列順第2位
ELSE 1 -- 整列順第1位
END,
LOWER(guild); -- 整列順第1位のなかで大文字と小文字を区別せず昇順実行結果は次のようになります。
guild | avg_lv | num
--------------+--------+-----
D.D.D | 55.8 | 5
hameln | 52.0 | 4
Yamato | 48.6 | 5
(Freelancer) | 39.6 | 5
(Total) | 48.8 | 19なお、ROLLUP
の結果を含めた並び順や表示体裁の細かい制御は、SQLでも実現は可能ですが、複雑になりやすい処理です。可読性や保守性を考えると、最終的な表示順や体裁はアプリケーション側で調整するほうが実用的なケースも多いことを覚えておいてください。
8.3.1 SQLドリル💻
ex-04_4.sql👉 s_characters テーブルから、次のように job ごとに最大レベル、平均レベル、人数を得るような SQL を記述せよ。- 全体についても、同様の集計処理を実施して
-TOTAL-というラベルをつけること。
- 全体についても、同様の集計処理を実施して
job | max_lv | avg_lv | num
---------+--------+--------+-----
-TOTAL- | 73 | 48.8 | 19
Fighter | 56 | 37.3 | 4
Monk | 39 | 36.0 | 2
Ninja | 62 | 54.0 | 2
Priest | 50 | 38.8 | 4
Samurai | 73 | 70.3 | 3
Wizard | 64 | 58.3 | 48.4 GROUP BY句にCASE式を利用
GROUP BY 句に CASE式
を利用することで、より柔軟にグループを定義して集計処理をすることが可能となります。たとえば「ギルド所属者」と「無所属者」でグループを分けて集計処理をしたい場合は、次のように
SQL を記述します。
SELECT
CASE
WHEN guild IS NULL THEN '無所属'
ELSE 'ギルド所属'
END AS "カテゴリ",
ROUND(AVG(level), 1) AS "avg_lv",
COUNT(*) AS "num"
FROM
s_characters
GROUP BY
CASE
WHEN guild IS NULL THEN '無所属'
ELSE 'ギルド所属'
END;ここで、SELECT 句には GROUP BY 句で指定した
CASE式 と同じ結果を返す式を記述する必要 があります。 - GROUP BY
に指定していない式やカラムを (集約関数を適用せずに) SELECT
に含めると、グループ化されていないカラムの参照
とみなされ、エラーとなります。
実行結果は次のようになります。
カテゴリ | avg_lv | num
------------+--------+-----
ギルド所属 | 52.1 | 14
無所属 | 39.6 | 5EX: 整列順も厳密に制御したい場合は…
GROUP BY 句に CASE式
を使用したとき、整列順も厳密に制御したい場合は、次のようにします。
SELECT
CASE
WHEN guild IS NULL THEN 2
ELSE 1
END AS "ID",
CASE
WHEN guild IS NULL THEN '無所属'
ELSE 'ギルド所属'
END AS "カテゴリ",
ROUND(AVG(level), 1) AS "avg_lv",
COUNT(*) AS "num"
FROM
s_characters
GROUP BY
CASE
WHEN guild IS NULL THEN '無所属'
ELSE 'ギルド所属'
END,
CASE
WHEN guild IS NULL THEN 2
ELSE 1
END
ORDER BY
CASE
WHEN guild IS NULL THEN 2
ELSE 1
END;実行結果は次のようになります。
ID | カテゴリ | avg_lv | num
----+------------+--------+-----
1 | ギルド所属 | 52.1 | 14
2 | 無所属 | 39.6 | 58.4.1 SQLドリル💻
ex-04_5.sql👉 s_characters テーブルから、次のように前衛職と後衛職でグループをわけて最大レベル、平均レベル、人数を得るような SQL を記述せよ。
battle_position | max_lv | avg_lv | num
-----------------+--------+--------+-----
backline | 64 | 48.5 | 8
frontline | 73 | 49.1 | 118.5 DATE_TRUNC関数を利用した時間軸に沿った集計処理
GROUP BY 句は、時間軸に沿って集計処理
(日時でグループ化して集計処理) をしたい場面でも用いられます。この際、PostgreSQL では
DATE_TRUNC 関数を利用することで SQL
をシンプルに記述することができます。この関数は 指定した単位で日時を切り捨てる関数 で、次のように動作します。
DATE_TRUNC('hour', TIMESTAMP '2025-10-30 15:30:58')👉2025-10-30 15:00:00(TIMESTAMP型)DATE_TRUNC('month', TIMESTAMP '2025-10-30 15:30:58')👉2025-10-01 00:00:00( 〃 )DATE_TRUNC('year', TIMESTAMP '2025-10-30 15:30:58')👉2025-01-01 00:00:00( 〃 )- 第1引数に指定可能な値 (文字列リテラル) は公式ドキュメント を参照してください。
DATE_TRUNCは 標準SQLではなくPostgreSQL の独自関数 (拡張) です。- 第2引数には
DATE型やINTERVAL型をとることもできます。
たとえば、最終ログイン日時 (last_login_at)
を、月単位でまとめて、その件数を求めたいとき、DATE_TRUNC を利用すれば以下のように
SQL を書くことができます。
SELECT
DATE_TRUNC('month', last_login_at) AS "date", -- ◀ ここに注目
COUNT(*) AS "num"
FROM
s_characters
WHERE
last_login_at IS NOT NULL
GROUP BY
DATE_TRUNC('month', last_login_at); -- ◀ ここに注目実行結果は、次のようになります。
date | num
---------------------+-----
2025-09-01 00:00:00 | 6
2025-07-01 00:00:00 | 4
2025-08-01 00:00:00 | 4
2025-10-01 00:00:00 | 4体裁を整えたバージョンは以下のようになります。以下の SQL の 第02行目 の
TO_CHAR 関数は、第03回講義で紹介したように日時などを整形出力する関数です。
SELECT
TO_CHAR(DATE_TRUNC('month', last_login_at), 'YYYY/MM') AS "date",
COUNT(*) AS "num"
FROM
s_characters
WHERE
last_login_at IS NOT NULL
GROUP BY
DATE_TRUNC('month', last_login_at)
ORDER BY
"date";実行結果は、次のようになります。
date | num
---------+-----
2025/07 | 4
2025/08 | 4
2025/09 | 6
2025/10 | 48.5.1 参考: DATE_TRUNC関数を使用せずに同様の集計をする
DATE_TRUNC
関数を使用せずに、標準SQLで同様の処理をしたい場合には、CASE式
で月ごとの区分を表現することができます。
SELECT
CASE
WHEN last_login_at >= DATE '2025-07-01' AND
last_login_at < DATE '2025-08-01' THEN '2025/07'
WHEN last_login_at >= DATE '2025-08-01' AND
last_login_at < DATE '2025-09-01' THEN '2025/08'
WHEN last_login_at >= DATE '2025-09-01' AND
last_login_at < DATE '2025-10-01' THEN '2025/09'
WHEN last_login_at >= DATE '2025-10-01' AND
last_login_at < DATE '2025-11-01' THEN '2025/10'
ELSE '(その他)'
END AS "date",
COUNT(*) AS "num"
FROM
s_characters
WHERE
last_login_at IS NOT NULL
GROUP BY
CASE
WHEN last_login_at >= DATE '2025-07-01' AND
last_login_at < DATE '2025-08-01' THEN '2025/07'
WHEN last_login_at >= DATE '2025-08-01' AND
last_login_at < DATE '2025-09-01' THEN '2025/08'
WHEN last_login_at >= DATE '2025-09-01' AND
last_login_at < DATE '2025-10-01' THEN '2025/09'
WHEN last_login_at >= DATE '2025-10-01' AND
last_login_at < DATE '2025-11-01' THEN '2025/10'
ELSE '(その他)'
END
ORDER BY
"date";日時の取り扱いに関する注意
last_login_at
がTIMESTAMP型のとき、last_login_at BETWEEN DATE '2025-07-01' AND DATE '2025-07-31'
のような条件を記述すると、2025年07月31日の 00時00分00秒ちょうど
までしか含まれなくなるので注意してください。これは DATE '2025-07-31' が 2025-07-31 00:00:00
に変換されるためです。
そのため、last_login_at が 2025-07-31 01:00:00 のときは、その条件は
真にはならない ので注意してください。
8.5.2 SQLドリル💻
ex-04_6.sql👉 s_characters テーブルについて、次のように created_on で年別に「人数」と「平均レベル」を集計した結果セットを得るような SQL を記述せよ。
year | num | avg_lv
------+-----+--------
2020 | 4 | 38.8
2021 | 3 | 43.0
2022 | 4 | 50.3
2023 | 4 | 57.0
2024 | 4 | 53.89 HAVING 句
GROUP BY で 集約した結果を条件で絞り込みたい
ときは、HAVING 句を使用します。
- 集約前のレコード単体 に対して条件を指定したい場合は
WHERE句を使用します。
例えば、GROUP BY guild
によって、所属ギルドごとにグループ化し、各グループの平均レベルが「50以上」のものだけを抽出したい場合は、HAVING
句を使って次のように SQL を記述します。
HAVING句では、集約関数を使わずに集約キー以外のカラムを直接参照することはできません。例えばbuff > 0.0のような条件式はHAVINGではなくWHERE句で指定します。
SELECT
COALESCE(guild,'Freelancer') AS "guild",
COUNT(*) AS "num",
ROUND(AVG(level), 1) AS "avg_lv"
FROM
s_characters
GROUP BY
guild
HAVING
AVG(level) >= 50
ORDER BY
AVG(level) DESC;実行結果は、次のようになります。
guild | num | avg_lv
--------+-----+--------
D.D.D | 5 | 55.8
hameln | 4 | 52.0なお、SELECT 文は、SELECT 句 👉 FROM 句 👉
WHERE 句 👉 GROUP BY 句 👉 HAVING 句 👉
ORDER BY 句 👉 (LIMIT 句 / OFFSET 句)
という順で記述しないと構文エラーになるので注意してください。
9.0.1 SQLドリル💻
ex-05_1.sql 👉 s_characters
テーブルについて、次のようにジョブごとの「平均レベル」と「人数」を集計した結果セットを得る SQL
を記述せよ。
- 人数が2名以下のジョブは結果セットに含めないこと
- 平均レベルの降順で表示すること
job | avg_lv | num
---------+--------+-----
Samurai | 70.3 | 3
Wizard | 58.3 | 4
Priest | 38.8 | 4
Fighter | 37.3 | 49.1 WHERE句とHAVING句の使い分けについて
HAVING 句は、GROUP BY による 集約結果に対して条件を使った絞り込みをするため に使用します。
また、HAVING 句では、集約キー以外のカラムは COUNT や
MAX
などの集約関数を適用したうえで参照する必要があります。例えば、GROUP BY guild
のとき、HAVING level >= 30
は指定できませんが、HAVING MIN(level) >= 30 を指定することは可能です。
- 逆に言えば
WHERE句において、COUNTやMAXのような「集約関数」を使用することはできません。
9.1.1 定着確認
- SQL において、次に示す各句を記述する適切な順序を記号で答えよ。
- ➊ WHERE、❷ HAVING、❸ GROUP BY、❹ ORDER BY、❺ SELECT、❻ FROM
- 答え : ❺❻➊❸❷❹
10 授業時間外学習の指示 (宿題)
🚨本科目は「学修単位科目」であり、1回の講義あたり「4時間相当」の授業時間外学習が求められる科目です🏃
- 次回の講義で「小テスト❺」を実施します。
- 定着確認 および SQLドリル から主に出題します。
- 講義が進行するにつれて、当然ながら小テストの内容も複雑で高度なものになっていきます。
- ここまでの第03回講義~第05回講義では、実践的な SQL について学んできました。次回講義では、データベースの概念設計 (概念データモデルの設計) および論理設計 (データモデルの設計) などの理論に寄せた内容を学んできます。
- 予習として📖 教科書「達人に学ぶDB設計 徹底指南書
(第2版)」の以下ページを読んできてください。内容が理解できなくても構いません。この予習の目的は
「ここがよく分からなかった」というポイントを自覚的に整理して、次回の授業に望んでもらうこと
にあります。
- 皆さんは既に PG3 で、複数テーブルから構成される DB を扱っているので、以下の順で読むほうが納得感があると思います。
- pp.145-164 第4章「ER図」
- 4-1 テーブルが多すぎる
- 4-2 テーブル同士の関連を見抜く
- 4-3 ER図の書き方
- 4-4 「多対多」と関連実体
- pp.89-123 第3章「論理設計と正規化」
- 3-1 テーブルとは何か
- 3-2 テーブルの構成要素
- 3-3 正規化とは何か
- 3-4 第1正規形
- 3-5 第2正規形~部分関数従属
- 3-6 第3正規形~推移的関数従属
- pp.25-49 第2章「論理設計と物理設計」
- 2-1 概念スキーマと論理設計
- 2-2 内部スキーマと物理設計
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。
- 講義資料内の「演習」や「SQLドリル」に再度取り組んでください。特に、SQLドリル💻 は、授業時間中に1回取り組むだけでは定着しないので注意してください。