1 連絡
- 試験答案を返却します。
- 後期中間の試験の解答例と解説は第08回講義を参照してください。
- 返却された答案は、採点ミスがないか確認してください。ミスと思われるものがあれば、この授業時間内に申し出てください。
- Unity 1-Week GAME JAM
- https://unityroom.com/unity1weeks
- 次回の開催 12月22日(月) 0時 〜 12月28日(日) 20時 … お題「????」
- 2025年度 プログラミング1 (2年生) の ポートフォリオ の作品共有 (学内のみ)
1.1 課題1の作品共有
課題1として提出してもらったレポートは、Teamsの「ファイルタブ」で共有しています。各自で参考にしてください。
ほとんどの学生が、draw.io を使用してのER図の作成でした。
- draw.io(VSCode拡張機能Draw.io Integrationを含む)
- Mermaid+Inkscape
- Luna Modeler
- ERDPlus
- Figma
- PowerPoint
1.2 ハンズオン学習の準備
次の手順でSQL演習環境の立ち上げと、教材の更新を取得してください。
- SQL演習環境の動作確認@ 第04回講義
- 教材の更新の取得@ 第04回講義
2 前回の復習 (CREATE文の超基礎)
中間試験前の第07回講義では CREATE
文による「テーブル定義
(作成)」の基礎について解説しました。テーブルは基本的には
カラム名、データ型、制約
の3つを指定して定義しました。
具体的には、次の 第08行目 から 第13行目 のような
CREATE
文によって、テーブルを定義・作成することができました。演習環境上で実際に実行してみてください。
-- 既に p_characters が存在する場合は削除
DROP TABLE IF EXISTS p_characters;
-- トランザクションの開始
START TRANSACTION;
-- キャラクタテーブルの作成
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY, -- PK指定
name VARCHAR(16) NOT NULL, -- 非NULL制約
job VARCHAR(16) NOT NULL, -- 非NULL制約
guild VARCHAR(16)
);
-- レコードの追加
INSERT INTO
p_characters (character_id, name, job, guild)
VALUES
(1, 'Alice', 'Priest', 'Yamato'),
(2, 'Bob', 'Monk', 'hameln'),
(3, 'Charlie', 'Wizard', NULL),
(4, 'Dave', 'Samurai', 'Yamato');
-- テーブルの確認
SELECT
*
FROM
p_characters;
-- ロールバックによる処理の取り消し
ROLLBACK;- 第09行目 の
PRIMARY KEYは主キー (PK: Primary key) を指定するキーワードでした。 - 第10行目 の
NOT NULLは 非NULL制約 を指定するキーワードでした。
上記SQLの実行結果 (SELECT * FROM p_characters の出力)
は、次のようになります。
character_id | name | job | guild
--------------+---------+--------+--------
1 | Alice | Priest | Yamato
2 | Bob | Monk | hameln
3 | Charlie | Wizard |
4 | Dave | Samurai | Yamato ここで、第09行目 の PRIMARY KEY
は、主キー指定 (PK: Primary Key)
をするためのキーワードでした。主キーとして指定したカラムには、自動的に 「非NULL制約」と「UNIQUE制約」 が適用されます。
第10行目 と 第11行目 の NOT NULL
は、非NULL制約
を指定するためのキーワードでした。これにより、name および
job カラムには、値の欠損が許容されなくなります (=
NULL を格納することができなくなります)。
2.0.1 演習
- 主キー指定している character_id に
NULLや、既にレコードに存在する値 を挿入しようとすると、失敗することを実際に確認してください。また、英語環境でのエラーメッセージについても確認してください。- 例: 第22行目 を
(NULL, 'Dave', 'Samurai', 'Yamato');に変更 - 例: 第22行目 を
(1, 'Dave', 'Samurai', 'Yamato');に変更
- 例: 第22行目 を
- 非NULL制約を与えている name や job に
NULLを挿入しようとすると、失敗することを実際に確認してください (英語環境のエラーメッセージも確認)。また、空文字''については問題なく挿入できることを確認してください。- 例: 第22行目 を
(4, NULL, 'Samurai', 'Yamato');に変更 - 例: 第22行目 を
(4, '', 'Samurai', 'Yamato');に変更
- 例: 第22行目 を
英語環境でのエラーメッセージを確認するには…
演習環境では、以下のように sql:en
スクリプトを実行することで、エラーメッセージなどの応答を 英語 (標準)
に切り替えられます。英語環境の RDBMS
を扱うことも多いので、この形式のメッセージにも慣れておくと後々役に立ちます。
npm run sql:en sql/09/init-tables_01.sqlなお、[Ctrl]+[Shift]+[B] で SQL
を実行するとき、常に英語環境を使用したい場合は、プロジェクト の
.vscode\tasks.json の "args" の項目を編集してください。
2.1 テーブルレベルの制約指定
init-tables_01.sql では PRIMARY KEY や NOT NULL を
カラムレベルの制約 (Column Constraint)
として記述しましたた。これらは、次のように テーブルレベル (Table Constraint)
として記述することも可能となっています。
CREATE TABLE p_characters (
character_id INTEGER,
name VARCHAR(16),
job VARCHAR(16),
guild VARCHAR(16),
-- テーブルレベルでの制約指定
PRIMARY KEY (character_id),
CHECK (name IS NOT NULL),
CHECK (job IS NOT NULL)
);CHECK(...)については以降のセクションで詳しく解説します。- 複合主キー のように テーブルレベルでのみ指定可能 な制約もあります(前回講義を参照)。
NOT NULLやUNIQUEのような単純な制約は、可読性の観点から一般に「カラムレベル」で指定します。
CREATE 後に制約を追加したいときは…
テーブル作成後に制約を追加したい場合は ALTER TABLE
文を使用します。たとえば、以下のように ADD CONSTRAINT
を使って制約を追加することができます。詳しくは、今後の授業で取り上げます。
3 一意性制約 (UNIQUE制約)
カラムに対して一意性制約 (UNIQUE制約) を設定したい場合は
UNIQUE キーワードを使用します。例えば、p_characters テーブルにおいて
キャラクタ名の重複を許可したくない場合 は、name
カラムに対して、次のように UNIQUE キーワードを指定します。
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY, -- PK指定
name VARCHAR(16) NOT NULL UNIQUE, -- 非NULL制約 + 一意性制約
job VARCHAR(16) NOT NULL, -- 非NULL制約
guild VARCHAR(16)
);なお、NOT NULL を付けずに UNIQUE
だけを指定した場合、そのカラムには NULL
が許容されます。このとき注意したいのは「複数レコードが同時に
NULL
を持っていても一意性違反にはならない」という点です。これは、SQL において
NULL が 値が不明で比較できないもの
と扱われ、一意性チェックの対象にならないため ために生じる挙動です。
実際に、以下の SQL を実行すると、第08行目 で email
カラムに「一意性制約」をつけているにも関わらず、第14-15行目 で Alice と Bob
の email に同時に NULL が登録できてしまいます。
DROP TABLE IF EXISTS p_characters;
START TRANSACTION;
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL,
email VARCHAR(64) UNIQUE -- 一意性制約を設定
);
INSERT INTO
p_characters (character_id, name, email)
VALUES
(1, 'Alice', NULL), -- email に NULL を登録
(2, 'Bob', NULL); -- email に NULL を登録
SELECT
*
FROM
p_characters;
ROLLBACK;実行結果は次のようになります。email カラムに一意性制約を指定していても
NULL は例外となる点に注意してください。
character_id | name | email
--------------+-------+-------
1 | Alice |
2 | Bob |(プロンプト例)
PostgreSQL に関する質問です。あるカラムに対して、
NULLを含めて一意性を保証するような制約を指定することは可能ですか。つまり、そのカラムについて、NULLを持つレコードがただひとつになるような制約を設定することは可能ですか。
3.0.1 定着確認
- 次の説明のうち、正しいものを すべて 選び記号で答えよ。
- ❶
UNIQUE制約を付けたカラムには、NULLは格納できない。 - ❷
UNIQUE制約を付けたカラムでは、NULLが複数行に存在しても一意性違反にはならない。 - ❸
UNIQUEとNOT NULLを併用すると、そのカラムは「一意で、かつ必ず値を持つ」ことが保証される。 - ❹
PRIMARY KEYは内部的にUNIQUEとNOT NULLの2つの制約と同等である。 - 答え: ❷❸❹
- ❶
3.0.2 演習
- 一意性制約を与えた name カラムに重複する値を挿入しようとすると、失敗することを実際に確認してください。
name VARCHAR(16) NOT NULL UNIQUEをname VARCHAR(16) UNIQUE NOT NULLのように書き換えるとどうなるか確認してください。
4 カラムのデフォルト値の設定
CREATE
文では、カラムの「デフォルト値」を設定することができます。デフォルト値が与えられているカラムは、INSERT
文で 値を明示せずに追加すること (=値の指定を省略すること)
ができます。
たとえば、次の 第12行目~第15行目 のように
CREATE
によるテーブル定義のなかでデフォルト値を与えることができます。ここでは、level、guild、created_on、updated_at
の 4つのカラムに DEFAULT キーワードを使用して、デフォルト値を設定しています。
-- 既に p_characters が存在する場合は削除
DROP TABLE IF EXISTS p_characters;
-- トランザクションの開始
START TRANSACTION;
-- キャラクタテーブルの作成
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL,
job VARCHAR(16) NOT NULL,
level INTEGER NOT NULL DEFAULT 1, -- 1 を デフォルト値に設定
guild VARCHAR(16) DEFAULT NULL, -- NULL を 〃
created_on DATE DEFAULT CURRENT_DATE, -- 現在日付を 〃
updated_at TIMESTAMP DEFAULT LOCALTIMESTAMP(0) -- 現在日時(TZなし)を 〃
);
-- レコードの追加 1
INSERT INTO
p_characters (character_id, name, job)
VALUES
(1, 'Alice', 'Priest');
-- レコードの追加 2
INSERT INTO
p_characters (character_id, name, job, guild)
VALUES
(2, 'Bob', 'Priest', 'hameln');
-- レコードの追加 3
INSERT INTO
p_characters (character_id, name, job, level, created_on)
VALUES
(3, 'Charlie', 'Wizard', 5, '2025-10-30'),
(4, 'Dave', 'Samurai', 20, '2025-08-10');
-- テーブルの確認
SELECT
character_id,
name,
job,
level,
guild,
created_on,
updated_at AS updated_at
FROM
p_characters;
-- ロールバックによる処理の取り消し
ROLLBACK;実行結果は、次のようになります。
INSERT 0 2
character_id | name | job | level | guild | created_on | updated_at
--------------+---------+---------+-------+--------+------------+---------------------
1 | Alice | Priest | 1 | | 2025-12-09 | 2025-12-09 15:13:32
2 | Bob | Priest | 1 | hameln | 2025-12-09 | 2025-12-09 15:13:32
3 | Charlie | Wizard | 5 | | 2025-10-30 | 2025-12-09 15:13:32
4 | Dave | Samurai | 20 | | 2025-08-10 | 2025-12-09 15:13:32デフォルト値が設定されている場合、INSERT
文で値の指定を省略することができます。たとえば、以下のように、デフォルト値が設定されている
level、guild、created_on、updated_at
カラムを省略してレコードを追加することが可能になります。
LOCALTIMESTAMP(0)とすることで、小数秒を含まない現在日時 (=小数秒を 0 に揃えた日時値) を得ることができます。DATE_TRUNC('second', LOCALTIMESTAMP)でも同様の結果になります。
また、次のように、任意のカラムだけにデフォルト値を使用することもできます。guild と updated_at だけ値を省略してレコードを挿入する場合、次のようにします。
INSERT INTO
p_characters (character_id, name, job, level, created_on)
VALUES
(3, 'Charlie', 'Wizard', 5, '2025-10-30'),
(4, 'Dave', 'Samurai', 20, '2025-08-10');非NULL制約がないカラムは「NULL」がデフォルト値
カラムに 非NULL制約 (NOT NULL)
を付けない場合、そのデフォルト値は自動的に NULL となります。
たとえば、第13行目 の guild VARCHAR(16) DEFAULT NULL
は、guild VARCHAR(16) のように記述した場合と「レコード挿入時の挙動
(デフォルト値)」が同じになります。
4.0.1 定着確認
- 次の説明のうち、正しいものを すべて 選び記号で答えよ。
- ❶ デフォルト値が設定されているカラムは
INSERT文でそのカラムの指定を省略できる。 - ❷
DEFAULT CURRENT_DATEを指定したカラムには、INSERT 時の「現在日付」が自動的に入る。 - ❸
NOT NULLを付けていないカラムのデフォルト値は、自動的にNULLとなる。 - ❹ デフォルト値を設定したカラムは、必ず
INSERT文でその値を上書きしなければならない。 - 答え: ❶❷❸
- ❶ デフォルト値が設定されているカラムは
- 小数秒を含まない現在日時 (タイムゾーン情報付き)
を得るための日時値関数を適切な引数を含めて答えよ。
- 答え:
CURRENT_TIMESTAMP(0)
- 答え:
4.0.2 演習
デフォルト値を設定していないカラムを省いてレコードを挿入しようとすると、失敗することを実際に確認してください。英語環境でのエラーメッセージについても確認してください。
- 例: 第19行目 ~ を
INSERT INTO p_characters (character_id, name) VALUES (1, 'Alice');に変更
- 例: 第19行目 ~ を
init-tables_02.sqlの 第13行目 をguild VARCHAR(16),に書き換えても (=DEFAULT NULLを明示しなくても)、同じ実行結果が得られることを確認してください。init-tables_02.sqlの 第15行目 をLOCALTIMESTAMP(0)をLOCALTIMESTAMPに書き換えたときの実行結果について確認してください。
4.1 サロゲートキーの自動採番設定
サロゲートキーを「主キー」として用いる場合は「自動採番機能」を使うことで 安全でシンプルなデータ管理が可能 となります。
整数値の連番 (=オートインクリメント) によるサロゲートキーは、次の 第07行目 のように指定します。
DROP TABLE IF EXISTS p_characters;
START TRANSACTION;
-- キャラクタテーブルの作成
CREATE TABLE p_characters (
character_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY, -- 自動採番
name VARCHAR(16) NOT NULL
);
-- レコードの追加
INSERT INTO
p_characters (name) -- character_id を省略
VALUES
('Alice'),
('Bob');
-- テーブルの確認 1
SELECT * FROM p_characters;
-- レコードの全件削除
DELETE FROM p_characters;
-- レコードの再挿入
INSERT INTO
p_characters (name)
VALUES
('Alice'),
('Bob'),
('Carol');
-- テーブルの確認 2
SELECT * FROM p_characters;
ROLLBACK;実行結果は、次のようになります。第22行目 の
DELETE FROM p_characters でレコードを全件削除していますが、その後の再挿入でも
重複しない値が使われていること に注意してください。
character_id | name
--------------+-------
1 | Alice
2 | Bob
character_id | name
--------------+-------
3 | Alice
4 | Bob
5 | Carolなお、GENERATED ALWAYS AS IDENTITY としている場合は 手動で任意の値を指定すること
が不可能になります。必要に応じて任意の値を指定したい場合 は
GENERATED BY DEFAULT AS IDENTITY を使用してください。
- 過去の PostgreSQL では、自動採番したいときに 標準SQLではない独自構文
である
SERIALが広く用いられていました。しかし、現在は標準SQLに準拠したGENERATED AS IDENTITYが推奨されています。SERIALは新規設計では非推奨とされているため、本科目でもSERIALは使わないようにしてください。
プロンプト例
PostgreSQL で、PK を設定する際、
SERIALではなくGENERATED AS IDENTITYを使うべきだと言われました。その理由や、両者の違いを解説してしてください。
4.1.1 演習
init-tables_03.sqlにおいてDELETE FROM p_charactersの代わりに、TRUNCATE TABLE p_characters RESTART IDENTITYにすると 連番 (IDシーケンス) がリセットされること を確認してください。init-tables_03.sqlの 第12行目 から 第16行目 を以下のように書き換えると (=手動で character_id を指定すると)、失敗することを実際に確認してください。
- 上記において、第07行目 の
GENERATED ALWAYS AS IDENTITYをGENERATED BY DEFAULT AS IDENTITYに変更すると、手動による character_id の指定も問題なく機能すること を確認してください。
手動採番と自動採番の衝突
手動採番と自動採番を混在させると、予期せぬ「PRIMARY KEY制約違反」が起きる場合があるので注意してください。
たとえば、次の SQL では 第11~15行目 で手動採番、第18~22行目 で自動採番を利用してレコードを追加しようとしています。しかし、自動採番は 既存の手動採番値を参照して新しい番号を調整する機能 を持ちません。
そのため、第21行目 におけるレコードを挿入時に内部的に 1
を採番しようとして、既に存在する 1 と衝突し、PRIMARY KEY 違反
(一意性制約違反) が発生します。
DROP TABLE IF EXISTS p_characters;
START TRANSACTION;
CREATE TABLE p_characters (
character_id INTEGER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
name VARCHAR(16) NOT NULL
);
-- レコードの追加 (手動採番)
INSERT INTO
p_characters (character_id, name)
VALUES
(1, 'Alice'),
(2, 'Bob');
-- レコードの追加 (自動採番)
INSERT INTO
p_characters (name)
VALUES
('Carol'), -- 内部的に `1` を採番してPK制約違反が発生
('Dave');
ROLLBACK;実行結果は、次のようになります。
psql:<stdin>:22: ERROR: 重複したキー値は一意性制約"p_characters_pkey"違反となります
DETAIL: キー (character_id)=(1) はすでに存在します。英語環境では、次のようになります。
psql:<stdin>:22: ERROR: duplicate key value violates unique constraint "p_characters_pkey"
DETAIL: Key (character_id)=(1) already exists.なお、IDENTITY
では、任意の初期値と増分を任意に設定することもできます。
(プロンプト例)
PostgreSQL に関する質問です。
id INTEGER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEYのようにカラムを定義しています。自動採番の初期値と増分値を指定することは可能ですか。また、指定可能な場合、その注意点などがあれば教えてください。
4.2 UUIDをサロゲートキーとして使用
サロゲートキーには、整数値を使った連番のほか、UUID v4 (Universally Unique Identifier Version 4) もよく使用されます。昨年度のプログラミング3でウェブアプリを開発する際にもUUID v4 を利用しました。
(プロンプト例)
UUID v4 とは何ですか。RDB の PK として、整数の連番を用いる場合と比較してのメリットとデメリットを教えてください。
UUID って v4 が広く使われていますが、それ以外のバージョンもあると聞きました。それぞれの違いと用途について解説してください。
RDB の PK として UUIDv4 以外に、CUID2 や NanoID というものを使用するケースもあると聞きました。それぞれの概要と、使い分けの考え方を教えてください。
PostgreSQL において、UUID をカラムの「デフォルト値」として設定したいときは、次のような SQL を用います。
CREATE EXTENSION IF NOT EXISTS pgcrypto;
DROP TABLE IF EXISTS p_characters;
START TRANSACTION;
CREATE TABLE p_characters (
character_id UUID DEFAULT GEN_RANDOM_UUID() PRIMARY KEY, -- UUID型、自動生成
name VARCHAR(16) NOT NULL,
level INTEGER DEFAULT (FLOOR(RANDOM() * 20) + 1) -- デフォルト値:1~20の整数乱数
);
INSERT INTO
p_characters (name)
VALUES
('Alice'),
('Bob'),
('Carol');
SELECT
*
FROM
p_characters;
ROLLBACK;実行結果は、次のようになります (character_id と level の値は実行毎に変化します)。
character_id | name | level
--------------------------------------+-------+-------
151ab517-d93e-4b46-90ef-70fd1419ef2a | Alice | 4
1c756f44-cad1-4161-902e-db0a1d4290b2 | Bob | 5
50b2e2a8-7774-4623-9cc6-bf36e238a6e7 | Carol | 12第08行目 では、character_id
を「UUID型」として定義しています。UUID は文字列型 (=
TEXT や CHAR(36) などの型)
としても保持可能ですが、UUID型を使うことで、内部表現が16バイトに最適化され、インデックスサイズが小さくなり、比較や検索の処理も一般に向上します。
さらに DEFAULT GEN_RANDOM_UUID() の指定により、INSERT 文で
character_id を明示しなかった場合に、自動的にランダムな UUID
が生成され割り当てられます。この関数を利用するためには、第01行目
で記述するように pgcrypto拡張 を有効化しておく必要があります。
(プロンプト例)
PostgreSQL に関する質問です。カラムに UUIDv4 を格納する場合、データ型 としては
CHAR(36)型よりも、UUID型のほうが良いと聞きました。その理由や効果について詳しく解説してください。
また、参考として 第10行目 に 1から20までの整数乱数値
をデフォルト値に設定する例を示しました。ただし、ゲームのレベルや初期パラメータのような「仕様に関わるランダム値」は、DB
側ではなくアプリ側で決定し、明示的に値を INSERT する設計のほうが一般的です。
5 CHECK制約
PostgreSQL では、レコードを挿入/更新する際に 値が妥当な範囲にあり、かつ、定義した条件に適合しているか を 自動的に検査する仕組み として CHECK制約 が利用できます。これにより、テーブル自身がデータの整合性を担保し、不正なデータが保存されることを防ぐことができます。
- CHECK制約には
CHECK ()を使用し、括弧の内部には真偽値 (=3値論理👉TRUE/FALSE/UNKNOWN) を返す「条件式」を記述します。- たとえば
CREATE文でlevel INTEGER CHECK (level < 100)と定義すると、level カラムには 100 以上の値が格納できなくなります。 - 条件式の評価結果が
FALSEの場合に制約違反となりエラーが発生します (=挿入や更新が失敗します)。TRUEに加えて、評価結果がUNKNOWN(=NULLを含む条件式の結果) の場合も 制約違反とは見なされないこと に注意してください (🚨重要)。
- たとえば
- バリデーション (入力値の検証) は 基本的にアプリ側の責務であり、DB側 の CHECK制約 はあくまでそれを補強する安全装置であることに注意してください。
CHECK制約では、単純な数値範囲のチェック (=level は 1 から 255 の範囲など)
に限らず、レコード内の複数のカラムを参照した条件
も設定可能となっています。たとえば、started_at < finished_at という
CHECK制約を指定して 「開始時刻は終了時刻より前」という関係
を強制することが可能になります。
CHECK制約の設定例を以下に示します。まずは、実際に実行してみてください。
DROP TABLE IF EXISTS p_users;
START TRANSACTION;
CREATE TABLE p_users (
user_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name VARCHAR(16) NOT NULL CHECK (name <> '') CHECK (name ~ '^[A-Za-z]*$'),
zip_code CHAR(8) NOT NULL CHECK (zip_code ~ '^[0-9]{3}-[0-9]{4}$'),
birthday DATE NOT NULL CHECK (birthday BETWEEN '1900-01-01' AND CURRENT_DATE),
locale VARCHAR(5) NOT NULL CHECK (locale IN ('ja', 'en', 'de', 'ru')),
created_at TIMESTAMP NOT NULL CHECK (
created_at >= birthday AND
created_at >= '2024-12-01'
),
deleted_at TIMESTAMP CHECK (deleted_at > created_at)
);
INSERT INTO
p_users (name, zip_code, birthday, locale, created_at)
VALUES
(
'Alice',
'572-8572',
'2001-03-12',
'en',
DATE_TRUNC('second', CURRENT_TIMESTAMP)
);
SELECT * FROM p_users;
ROLLBACK;第07行目 の name カラムでは
CHECK (name <> '') によって「空文字」の入力を禁止しています (第05回講義で解説したように
<> は 等しくない
を表す比較演算子です)。さらに、 CHECK (name ~ '^[A-Za-z]*$')
により、使用できる文字を英大文字・英小文字のアルファベットのみに限定しています
(記号や日本語などの使用を禁止しています)。ここで用いている ~ は、PostgreSQL
における 正規表現マッチ演算子 です (正規表現についてはPG1で学習済みです)。
(プロンプト例)
PostgreSQL における
'^[A-Za-z]*$'という正規表現の意味を詳しく解説してください。
- 注意🚨
CHECK (name ~ '^[A-Za-z]+$')とすれば、CHECK (name <> '')は省略可能です。正規表現で*は「0文字以上の繰り返し」、+は「1文字以上の繰り返し」を意味します。
第08行目 の zip_code カラム (郵便番号カラム) では
'^[0-9]{3}-[0-9]{4}$' という正規表現を利用して、格納可能な文字列が
NNN-NNNN の形式 (Nは半角数値)
であることを強制しています。これにより、ハイフンなしの郵便番号や 全角数字や漢数字の郵便番号 が入力されることを防いでいます。
(プロンプト例)
PostgreSQL における
'^[0-9]{3}-[0-9]{4}$'という正規表現の意味を詳しく解説してください。
第09行目 の birthday カラムでは
birthday BETWEEN '1900-01-01' AND CURRENT_DATE
という条件により、1900年1月1日以降、現在日付以前のみ
を誕生日として受け付けるようにしています。
第10行目 の locale カラムでは利用者が選択できるロケール
(=言語コード) を ja、en、de、ru
のいずれかに限定 しています。これより、誤字 (たとえば jp など)
や、未対応のロケール値が登録されることを防いでいます。
第11〜14行目 では、created_at と birthday
というカラム間の時間的な前後関係を保証するための制約を設定しています。具体的には
created_at >= birthday で「作成日時は誕生日以降である」ことを保証し、さらに
created_at >= '2024-12-01' で2024年12月1日 (システム運用開始日を想定)
以降となることを保証しています。
- 注意🚨
CHECK ( created_at >= birthday AND created_at >= '2024-12-01' )のような AND条件 はCHECK ( created_at >= birthday ) CHECK ( created_at >= '2024-12-01' )のように 複数に分割して記述しても同じ意味 になります。
第15行目 では created_at と deleted_at
の時間的な前後関係を保証するための制約を設定しています。具体的には
deleted_at > created_at
で「削除日時は作成日時より後にしか設定できない」ように制御しています。
- 注意🚨 deleted_at には
NULLが 問題なく格納可能 であることに注意してください。NULL > created_atの評価結果はUNKNOWNであり CHECK制約の違反にはなりません。制約違反になるのはFALSEのみです。
第26行目 の DATE_TRUNC 関数については第05回講義を参照してください。
PostgreSQL で値を限定する3つの実装パターン
PostgreSQL でカラムに admin/user/guest の
いずれかを格納したいような場合、そのテーブル設計には、いくつかの方法があります。
ひとつは、このセクションで扱ったように
CHECK制約で許可する文字列を列挙し、値を制限する方法があります。そのほかに、CREATE TYPE role AS ENUM ('admin', 'user', 'guest')
のように 専用の列挙型 (ENUM型)
を定義する方法、ロール情報をまとめたマスタテーブルを用意して外部キーで参照する方法
(後述)
などが挙げられます。これらはどれも実現可能な選択肢ですが、保守性や拡張性、アプリ側からの扱いやすさなど、それぞれにメリットとデメリットがあります。
(プロンプト例)
PostgreSQL において区分値を扱いたいとき、「CHECK制約」「ENUM型」「マスタテーブル+外部キー」による設計の違いを考察してください。特に、柔軟性・運用コスト・アプリからの扱いやすさの観点で考察してください。
5.0.1 演習
init-tables_05.sqlに、CHECK制約に違反するレコードを挿入するようなINSERT文を記述し、実行するとどのような応答になるかを確認してください。
5.0.2 SQLドリル💻
ex-01_1.sql👉 次のようなカラムを持ったテーブル p_characters を定義するCREATE文を記述せよ。- character_id: 整数型とし、値を省略したときは、初期値を1000とする自動採番とすること。手動でも設定可能とすること。主キーとすること。
- public_id: UUID型として、非NULL制約と一意性制約を設定すること。デフォルト値としてランダムな UUID v4 を設定すること。
- name: 文字列型で、3文字以上16文字以内の英文字 (大文字・小文字) のみ使用可とすること。非NULL制約と一意性制約を設定すること。
- hair_color:
#FFFFFFや#3333aaのような形式のカラーコードのみが格納できる7文字の固定長文字列型とすること。非NULL制約を設定すること。 - hp_max: 整数型で、値を 0 以上に限定すること。非NULL制約を設定すること。
- hp: 整数型で、値を 0 以上かつ hp_max 以下に限定すること。非NULL制約を設定すること。
- blood_type: 文字列型として、格納可能な値は
A、B、O、ABのいずれかに限定すること。NULLを許可すること。 - height_cm: 固定小数点数型とし、50.0〜250.0 の範囲の値に限定すること。非NULL制約を設定すること。
- created_on: 日付型として、格納できる値を 2025年12月1日以降、現在日以前にすること。非NULL制約を設定すること。
- deleted_on: 日付型として、格納できる値を created_on 以降とすること (未来の日付も格納可能とすること)。NULLを許可すること。
テーブル定義後は、次の INSERT 文が 正常に処理されること
を確認すること。
INSERT INTO
p_characters (character_id, name, hair_color, hp_max, hp, height_cm, created_on)
VALUES
(1, 'TEST', '#000000', 512, 256, 200, '2025-12-01');
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Alice', '#A1B2C3', 120, 100, 'A', 162.5, '2025-12-05'),
('Bob', '#3344FF', 150, 149, 'O', 175.0, '2025-12-07');テーブル定義後は、次の各 INSERT 文が 制約違反で失敗すること
を確認すること。
-- 1. name の一意制約違反(すでに 'Alice' が存在すると仮定)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Alice', '#112233', 100, 80, 'A', 160.0, '2025-12-02');
-- 2. name が短すぎる(3文字未満で CHECK (name ~ '^[A-Za-z]{3,}$') に違反)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Al', '#112233', 100, 80, 'A', 160.0, '2025-12-02');
-- 3. hair_color が「#」なしで正規表現に違反
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Charlie', '112233', 100, 80, 'B', 170.0, '2025-12-02');
-- 4. hp_max が負の値(CHECK (hp_max >= 0) に違反)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('David', '#445566', -10, 0, 'O', 165.0, '2025-12-02');
-- 5. hp が負の値(CHECK (hp >= 0) に違反)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Eve', '#778899', 100, -5, 'AB', 155.0, '2025-12-02');
-- 6. hp が hp_max を超えている(CHECK (hp_max >= hp) に違反)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Frank', '#ABCDEF', 50, 60, 'A', 180.0, '2025-12-02');
-- 7. blood_type が候補外(IN ('A','B','O','AB') に違反)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Grace', '#123456', 100, 50, 'C', 160.0, '2025-12-02');
-- 8. height_cm が範囲外(50〜250 から外れている)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Heidi', '#654321', 100, 80, 'B', 49.9, '2025-12-02');
-- 9. created_on が 2025-12-01 より前(CHECK (created_on >= '2025-12-01') に違反)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on)
VALUES
('Ivan', '#00FF00', 100, 80, 'O', 170.0, '2025-11-30');
-- 10. deleted_on が created_on より前(CHECK (deleted_on >= created_on) に違反)
INSERT INTO
p_characters (name, hair_color, hp_max, hp, blood_type, height_cm, created_on, deleted_on)
VALUES
('Judy', '#FF00FF', 100, 80, 'AB', 165.0, '2025-12-02', '2025-12-01');5.0.3 定着確認
- age カラムが
age INTEGER CHECK (age >= 0)のように定義されるとき、このカラムにNULLを挿入することは「できる」か「できない」か答えよ。- 答え: できる。
null >= 0の評価結果はUNKNOWNであり、制約違反にはならない。
- 答え: できる。
- level カラムが
level INTEGER NOT NULL CHECK (level BETWEEN 0 AND 100)のように定義されるとき、このカラムに格納可能な値は 1 以上 99 以下の整数値に制限される。この説明は「適切である」か「適切ではない」か答えよ。- 答え: 適切ではない。
BETWEENは開始値と終了値を含む。
- 答え: 適切ではない。
CHECK (gender = 'male' OR gender = 'female')は、CHECK (gender = 'male') CHECK (gender = 'female')と等価である。この説明は「適切である」か「適切ではない」か答えよ。- 答え: 適切ではない (分解可能なのは
ANDの場合)。
- 答え: 適切ではない (分解可能なのは
- p_users テーブルに携帯電話 (日本国内を想定) を保持する
mobile_phone
というカラムを作成したい。適切なデータ型とCHECK制約を答えよ。非NULL制約も設定すること。
- 答え:
mobile_phone CHAR(13) NOT NULL CHECK (mobile_phone ~ '^0(90|80|70)-[0-9]{4}-[0-9]{4}$')正規表現に関する別解は多数あり。
- 答え:
- p_users テーブルに「性別」を保持する gender
というカラムを作成したい。このカラムには、NULL許容の文字列として
male、female、otherのいずれかを格納したい。適切なデータ型とCHECK制約を答えよ。- 答え:
gender VARCHAR(6) CHECK (gender IN ('male', 'female', 'other'))別解は多数あり。
- 答え:
(プロンプト例)
PostgreSQL に関する質問です。テーブルの定義において
CHECK (gender IN ('male', 'female', 'other'))という制約を設定するとき、データ型としてVARCHAR(6)とTEXTのどちらを使用するのが適切でしょうか。VARCHAR型にすると、挿入時に文字長チェックがはいりますが、CHECK (...)が設定されているので冗長であるようにも思います。また、今後、non_binaryやprefer_not_to_sayなどの拡張があった場合に変更が必要そうです。一方で、TEXTにすると「性別に関する短い識別子を格納する」という設計意図がぼける気がします。
5.1 テーブルレベルのCHECK制約
同じ CHECK 条件は、カラム定義に併記する代わりに以下のようにまとめて書くこともできます。
CREATE TABLE p_users (
user_id INTEGER GENERATED ALWAYS AS IDENTITY,
name VARCHAR(16) NOT NULL,
zip_code CHAR(8) NOT NULL,
birthday DATE NOT NULL,
locale VARCHAR(5) NOT NULL,
created_at TIMESTAMP NOT NULL,
deleted_at TIMESTAMP,
-- ▼ テーブルレベルの制約
PRIMARY KEY (user_id),
CHECK (name <> ''),
CHECK (name ~ '^[A-Za-z]*$'),
CHECK (zip_code ~ '^[0-9]{3}-[0-9]{4}$'),
CHECK (birthday BETWEEN '1900-01-01' AND CURRENT_DATE),
CHECK (locale IN ('ja', 'en', 'de', 'ru')),
CHECK (created_at >= birthday),
CHECK (created_at >= '2024-12-01'),
CHECK (
deleted_at > created_at OR
deleted_at IS NULL
)
);5.2 CHECK制約が検証されるタイミングと範囲
ここでまでは、レコードの挿入 (INSERT) のタイミングで CHECK制約
が機能することを確認してきましたが、以下のように、更新 (UPDATE) のタイミングでも
CHECK制約 は機能します。
また、第09行目 で hp カラムの定義で設定している
CHECK (hp_max >= hp) は、hp の変更時だけでなく hp_max を更新した際にも再評価
されます。つまり、どちらか一方の値を変更したときでも、常に「hp_max は
hp
以上である」という条件が満たされているかどうかが検査される点に注意してください。
DROP TABLE IF EXISTS p_characters;
START TRANSACTION;
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL,
hp_max INTEGER NOT NULL CHECK (hp_max >= 0),
hp INTEGER NOT NULL CHECK (hp >= 0) CHECK (hp_max >= hp)
);
INSERT INTO
p_characters (character_id, name, hp_max, hp)
VALUES
(1, 'Alice', 200, 180);
SELECT * FROM p_characters;
-- CHECK制約違反により失敗
UPDATE p_characters
SET
hp_max = 100
WHERE
character_id = 1;
SELECT * FROM p_characters;
ROLLBACK;5.2.1 定着確認
- 次のように定義されるテーブルにおいて、hp カラムで設定している
CHECK (hp_max >= hp)は、hp カラムの更新時には検査されるが、hp_max カラムの更新時には検査されないので注意する必要がある。この説明は「適切である」か「適切ではない」かを答えよ。- 答え: 適切ではない
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL,
hp_max INTEGER NOT NULL,
hp INTEGER NOT NULL CHECK (hp_max >= hp)
);- 上記のテーブル定義は、次のように書き換えても同様に機能する。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え: 適切である。hp カラムの定義前にも CHECK で参照可能。
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL,
hp_max INTEGER NOT NULL CHECK (hp_max >= hp),
hp INTEGER NOT NULL
);6 外部キー制約 (FK制約)
外部キー制約 (FK制約) は、あるカラムに格納できる値を「参照先テーブルに実在する主キー (あるいは一意キー) に限定する」ための仕組みになります。外部キー制約を設定することで、関連づけられたテーブル同士の整合性が自動的に保証されるようになります。
- 本科目では 外部キーの参照先は主キーに限定して解説 します。
たとえば、次のような jobs テーブルがあるとします。
jobsテーブル
| job_id | name | attack_gain | defense_gain | magic_gain |
|---|---|---|---|---|
| 1 | Fighter | +3 | +5 | -2 |
| 2 | Monk | +4 | 0 | -1 |
| 3 | Ninja | +5 | -1 | 0 |
| 4 | Samurai | +3 | +3 | +2 |
| 5 | Priest | 0 | -1 | +4 |
| 6 | Wizard | -1 | -3 | +5 |
このとき、characters テーブルの job_id (以下、characters.job_id) に格納できる値を、上記 jobs テーブルの主キー (job_id) に限定したい場合に外部キー制約を設定します。
charactersテーブル
| characters_id | name | level | job_id |
|---|---|---|---|
| 1 | Alice | 42 | 5 |
| 2 | Bob | 33 | 2 |
| 3 | Charlie | 57 | 6 |
外部キー制約が設定されると、characters.job_id
には、jobs.job_id に存在する値だけ (具体的には 1 から
6 のみ) が挿入/更新可能となります。逆に言えば 0 や 7
などの不正な job_id が保存されることを防ぐことができます。
たとえば、次のような論理ER図で示されるテーブル同士の関係 (=外部キー制約による参照関係) は…

…以下のような、FK制約を含むテーブル定義 (CREATE 文)
で実装することができます。p_characters
テーブルを構成するカラムが、p_jobs.job_id と p_users.user_id
を参照する関係上、p_jobs テーブルと p_users
テーブルを先に定義しておく必要 があります。
DROP TABLE IF EXISTS p_characters;
DROP TABLE IF EXISTS p_users;
DROP TABLE IF EXISTS p_jobs;
-- テーブル定義・作成
CREATE TABLE p_jobs (
job_id INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL,
attack_gain INTEGER NOT NULL,
defense_gain INTEGER NOT NULL,
magic_gain INTEGER NOT NULL
);
CREATE TABLE p_users (
user_id INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL,
email VARCHAR(32) NOT NULL
);
CREATE TABLE p_characters (
character_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name VARCHAR(16) NOT NULL,
level INTEGER NOT NULL,
job_id INTEGER NOT NULL REFERENCES p_jobs (job_id), -- FK制約
user_id INTEGER NOT NULL REFERENCES p_users (user_id) -- FK制約
);
-- レコード挿入
INSERT INTO
p_jobs (job_id, name, attack_gain, defense_gain, magic_gain)
VALUES
(1, 'Fighter', 3, 5, -2),
(2, 'Monk', 4, 0, -1),
(3, 'Ninja', 5, -1, 0),
(4, 'Samurai', 3, 3, 2),
(5, 'Priest', 0, -1, 4),
(6, 'Wizard', -1, -3, 5);
INSERT INTO
p_users (user_id, email, name)
VALUES
(1, 'sarah.s@example.com', 'Sarah Smith'),
(2, 'james.m@example.com', 'James Miller');
INSERT INTO
p_characters (name, level, job_id, user_id)
VALUES
('Alice', 42, 5, 1),
('Bob', 33, 2, 2),
('Charlie', 57, 6, 1);
-- レコードの確認
SELECT * FROM p_jobs;
SELECT * FROM p_users;
SELECT * FROM p_characters;第24行目 と 第25行目 で「外部キー制約」を設定しています。これらの制約により、次のような動作が保証されます。
- p_jobs.job_id に存在しない値を、p_characters.job_id に挿入・更新することができなくなります。
- p_users.user_id に存在しない値を、p_characters.user_id に挿入・更新することができなくなります。
- p_characters.job_id で参照しているレコードを p_jobs から削除できなくなります。
- p_characters.user_id で参照しているレコードを p_users から削除できなくなります。
6.0.1 演習
init-tables_07.sqlの 第48行目 を('Alice', 42, 10, 1),のように書き換えると、レコードの挿入に失敗することを確認してください (どのようなエラーメッセージが表示されるかを確認してください)。確認後、変更は元に戻しておいてください。- 同様に
('Alice', 42, 5, 10),に書き換えたときについても確認してください。
- 同様に
init-tables_07.sqlの 第01行目 と 第02行目 を入れ替えると処理に失敗することを確認してください (どのようなエラーメッセージが表示されるかを確認してください)。確認後、変更は元に戻しておいてください。init-tables_07.sqlの最後にDELETE FROM p_users WHERE user_id=1;を追加すると処理に失敗することを確認してください。init-tables_07.sqlの最後にDELETE FROM p_jobs WHERE job_id=5;を追加すると処理に失敗することを確認してください。
6.0.2 定着確認
- 次に示すリレーショナルモデルを SQL の
CREATEで実装したい。外部キー制約が適切に設定可能となるように、p_users、p_characters、p_jobs のテーブルを定義する適切な順番を答えよ。なお、ALTER TABLEによる後付けの制約追加は考えないものとする。- 答え: p_users👉p_jobs👉p_characters。あるいは p_jobs👉p_users👉p_characters
6.1 ON DELETE CASCADE 指定
外部キー制約では、以下の 第24-25行目 のように
ON DELETE CASCADE を付与することで、参照先 (親テーブル)
のレコードが削除されたとき、そのレコードを参照している
子テーブル側のレコードが自動的に削除されるように設定 することができます。
CREATE TABLE p_characters (
character_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name VARCHAR(16) NOT NULL,
level INTEGER NOT NULL,
job_id INTEGER NOT NULL REFERENCES p_jobs (job_id) ON DELETE CASCADE, -- ◀ 注目
user_id INTEGER NOT NULL REFERENCES p_users (user_id) ON DELETE CASCADE -- ◀ 注目
);たとえば、p_jobs テーブルから job_id = 5
のレコードが削除されると、それを参照している p_characters テーブルのレコード (Alice)
も自動的に削除され、結果的に参照整合性が保証されます。
ON DELETE CASCADEが逆に作用することはありません。つまり、p_characters テーブルのレコードを削除したとき、p_jobs や p_users のレコードが影響を受けること (削除されること) は一切ありません。
6.1.1 演習
init-tables_07.sqlの p_characters の FK制約にON DELETE CASCADEを指定してください。そのうえで…DELETE FROM p_jobs WHERE job_id=5により、p_characters の Alice のレコードが自動削除されることを確認してください。DELETE FROM p_users WHERE user_id=2により Bob のレコードが自動削除されることを実際に確認してください。- 実装例 init-fk_01.sql
6.2 ON DELETE SET NULL 指定
外部キー制約では、以下の 第24-25行目 のように
ON DELETE SET NULL を付与することで、参照先 (親テーブル)
のレコードが削除されたとき、その値を参照している子テーブル側の外部キーを NULL に書き換える ように設定することもできます。
親テーブルの削除とともにレコードごと消してしまうのではなく、「参照が切れた状態を明示的に残す」ときに用いられます。なお、ON DELETE SET NULL
は 非NULL制約 が設定されているカラムには使用できません。
CREATE TABLE p_characters (
character_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name VARCHAR(16) NOT NULL,
level INTEGER NOT NULL,
job_id INTEGER REFERENCES p_jobs (job_id) ON DELETE SET NULL, -- ◀ 注目
user_id INTEGER REFERENCES p_users (user_id) ON DELETE SET NULL -- ◀ 注目
);たとえば、p_jobs テーブルから job_id = 5
のレコードが削除された場合、これを参照している p_characters テーブルの job_id
は NULL
に更新されます。キャラクタ自体は残しつつ、「職業情報だけが失われた状態」を表現できるため、履歴保持や一時的な未所属状態のモデル化に適しています。
ON DELETE SET NULLが逆に作用することはありません。つまり、p_characters テーブルのレコードを削除したり、NULLにしたとき、p_jobs や p_users が影響を受けることは一切ありません。
6.2.1 演習
init-tables_07.sqlの p_characters の FK制約にON DELETE SET NULLを指定 (同時にNOT NULL制約解除) してください。そのうえで…DELETE FROM p_jobs WHERE job_id=5により、p_characters の Alice のレコードの job_id カラムがNULLになることを確認してください。DELETE FROM p_users WHERE user_id=2により Bob のレコードの user_id カラムがNULLになることを確認してください。- 実装例 init-fk_02.sql
6.2.2 SQLドリル💻
ex-02_1.sql👉 次に示す「論理ER図」と「仕様」に基づくテーブル群を定義するSQLを記述せよ。- 特に指示がない限り、非キーのカラムには「非NULL制約」を設定すること。FKカラムについては「仕様」に基づき「非NULL制約」の有無を適切に設定すること。
- 論理ER図のなかで水色背景のカラムは主キーであることを意味する。
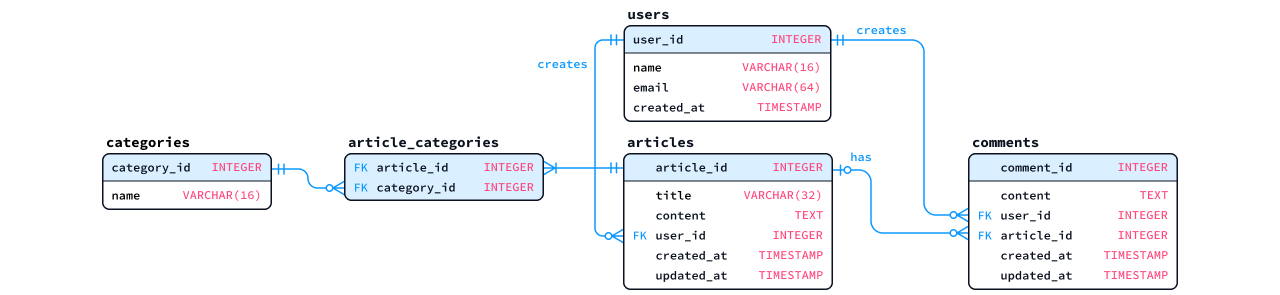
- 仕様
- users.user_id, articles.article_id, comments.comment_id, categories.category_id: デフォルト値を自動採番 (開始値は 1001) とすること。また、手動でも値を設定できるようにすること。
- users.name : 3文字以上を強制すること。
- users.email : 一意性制約を付加すること。
- *.created_at : デフォルト値として現在日時を設定すること。ただし、小数秒を 0 に揃えた値とすること。
- *.updated_at : 〃
- articles.created_at ≦ articles.updated_at とすること。
- comments.created_at ≦ comments.updated_at とすること。
- categories.name : 3文字以上を強制すること。一意性制約を付加すること。
- 記事が削除されても、その記事に関連づいたコメントは消えないようにすること。
- カテゴリが削除されても、そのカテゴリに属する記事は消えないようにすること。
- ユーザが削除されると、そのユーザが作成した記事とコメントが自動的に削除されるようにすること。
7 授業時間外学習の指示 (宿題)
🚨本科目は「学修単位科目」であり、1回の講義あたり「4時間相当」の授業時間外学習が求められる科目です🏃
- 次回の講義で「小テスト❼」を実施します。
- 主に SQLドリル、定着確認、演習 から出題します。
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。
- 講義資料内の「演習」や「SQLドリル」に再度取り組んでください。特に、SQLドリル💻 は、授業時間中に1回取り組むだけでは定着しないので注意してください。