1 連絡と準備
- 小テスト❺ を実施します。
- シラバス記載のように、小テストは最終評価の 35% に相当します。
- 遅刻・欠席等により追試験を希望する場合は第01回講義で案内した手続きをしてください。
- 今回、課題1の出題があります。
- シラバス記載のように、課題は最終評価の 20% に相当します。
1.1 今回講義の達成目標
- データベースにおいて、概念設計、論理設計、物理設計がそれぞれどんな役割を持つのか、その全体像を説明できる。
- 概念設計の内容をもとに、IE記法で概念ER図が作成できる。
- RDB を前提とした論理設計をもとに、IE記法で論理ER図が作成できる。
- 特に、多対多の関係を中間テーブルを用いて適切に分割できる。
2 データベースの設計
ここまでの講義では、既存のテーブルを対象とした CRUD操作
(=INSERT、SELECT、UPDATE、DELETE)
に関わる SQL について学んできました。これらは、SQL なかでも
DML(=Data Manipulation
Language)に分類されるもので、いわば データ (レコード)
をどう操作するか という視点での学びでした。
ここからは、次の段階として データベース設計、つまり データ (レコード) を格納するテーブルの設計に関する考え方 を学んでいきます。具体的には「システムの対象世界をどのようにモデル化し、どのようなテーブル構造として定義するか?」について学んでいきます。なお、このデータベース設計に関して扱う SQL は、DDL (=Data Definition Language) という範疇のものになります。
- RDBの特徴であるテーブルの結合 (
JOIN) については、データベース設計のあと (後期中間試験以降) に学んでいきます。 - 2年次の「情報2」でも触れたように SQL の命令は、その役割によってDML
(データ操作)、DDL (構造定義)、DCL
(権限制御) の3つに分けられます。
- DML: データの追加・検索・更新・削除
(
INSERT、SELECT、UPDATE、DELETEなど) - DDL: テーブルやデータベースの作成・変更
(
CREATE、ALTER、DROPなど) - DCL: アクセス権限の設定 (
GRANT、REVOKEなど)
- DML: データの追加・検索・更新・削除
(
2.0.1 定着確認
- SQLは大きく3つのカテゴリに分類される。3つのカテゴリを、それぞれ大文字のアルファベット3文字で答えよ。
- 答え: DML、DDL、DCL (順不同)
- 次の SQL 命令を、DML、DDL、DCLのいずれかに分類せよ。
SELECT: DMLGRANT: DCLINSERT: DMLALTER: DDLDROP: DDLDELETE: DML
- SQL に関する文脈において、DDL とは何の略語か。英語で答えよ。
- 答え: Data Definition Language
- SQL に関する文脈において、DML とは何の略語か。英語で答えよ。
- 答え: Data Manipulation Language
- SQL に関する文脈において、DCL とは何の略語か。英語で答えよ。
- 答え: Data Control Language
2.1 データベース設計の三層構造 (概念設計・論理設計・物理設計)
データベース設計は、①概念設計 (Conceptual Design)、②論理設計 (Logical Design)、③物理設計 (Physical Design) と、抽象度の高いモデルから具体的な実装に向けて段階的に詳細化しながら進めることが、教科書的・設計理論的な作法とされています。
- 実業務では、これらのプロセスを厳密に区分して進めることは少なく、いくつかのプロセスをまとめて進めたり、往復・試行錯誤を重ねながら設計を整えていくことが一般的です。
以下、多数の専門用語が登場しますが、まずは細部にこだわらず、全体像を理解することを優先してください。その後、気になる用語について、ウェブや生成AIを利用して概要を掴んでください。
2.1.1 定着確認
- データベース設計の一般的なプロセスは「概念設計」「論理設計」「物理設計」の3段階で構成される。これらは、どの順番で行うことが適切とされているか答えよ。
- 答え: 概念設計👉論理設計👉物理設計
2.2 概念設計
データベースにおける 概念設計 とは、現実世界の情報構造を理解・把握し データベースで管理すべき情報を関係者間で共有すること を目的とするプロセスとなります。このプロセスでは「リレーショナルモデル」や「ドキュメント指向モデル」といった特定のデータモデルに依存せず (=データモデルを意識せずに) 情報構造そのものをモデル化します。こうして得られた成果物は 概念データモデル と総称され、具体的には 概念ER図 (Conceptual Entity Relationship Diagram)、拡張ER図 (Enhanced/Extended ERD)、JSON スキーマ、UMLクラス図 (UML Class Diagram)、ツリー構造図などがこれに含まれます。
- 理論上は、概念設計はデータベースの種類を意識せずに行うことが理想とされています。ただし、実務においては、システムで利用するデータベースを (ある程度は) 見据えて概念設計が行われます。RDB であれば「概念ER図」を、JSONドキュメントデータベースであれば「JSONスキーマ」を作成する形で概念設計を進めることが一般的となります。
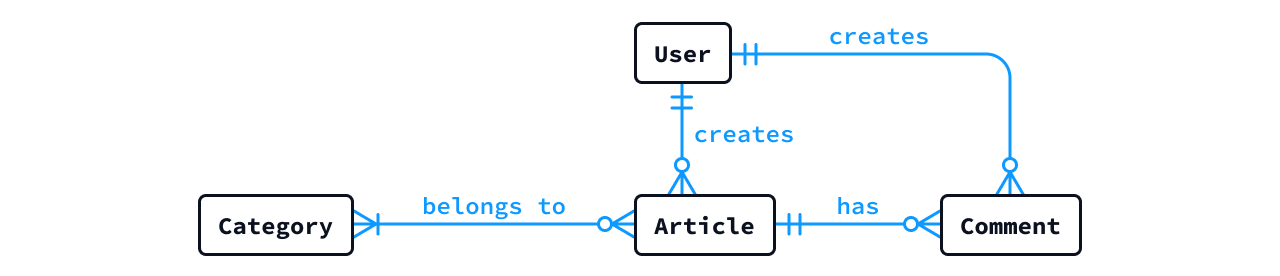
概念データモデルの代表格である 概念ER図 (Conceptual Entity Relationship Diagram) の例を以下に示します。図の意味や表記の読み方については、あとでセクションで解説します。
概念設計を終えたら、そのアウトプットやシステム要件を踏まえて、具体的な データベースモデル を選定していきます。ここでの「データベースモデルの選定」とはPostgreSQLやMySQL、MongoDBといった具体的なソフトウェアの選定ではなく、「リレーショナルモデル」や「ドキュメント指向モデル」「キーバリューストアモデル」といった アーキテクチャの選定 を意味します。
なお、大規模なシステムにおいては「このデータは RDB で管理し、このデータは KVストア で管理し…」のように複数モデルを併用(=ポリグロット永続化)することもあります。
(プロンプト例)
ソフトウェア開発の文脈において「ポリグロット永続化」とは何ですか。
データベースの概念設計に関する文脈で「概念ER図」とはなんですか。
データベースの概念設計に関する文脈で「UMLクラス図」とはなんですか。
2.2.1 定着確認
- データベース設計に関する文脈で、ER図の「ER」とは何の略か答えよ。
- 答え: Entity Relationship
- データベース設計に関する文脈で、概念設計のアウトプット (総称) を答えよ。
- 答え: 概念データモデル
- データベースの概念設計は、前提としてシステムで使用するデータベースモデル
(可能であれば具体的な製品や実装まで)
を決定しておく必要がある。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え: 適切ではない
2.3 論理設計
論理設計では、概念設計で整理したモデルを 実際に利用するデータベースモデルに適合する構造 に落とし込むプロセス となります。
データベースとして、リレーショナルモデルを採用する場合には、テーブルやカラムの定義、主キー・外部キーの設定といった スキーマ設計 を行ない 論理ER図 を作成するプロセスとなります。この際、冗長性を排除しデータの整合性を保つために 正規化 (Normalization) と呼ばれる考え方が重要となってきます。テーブル (=カラム構成) について、第1正規形 (1NF: 1st Normal Form) から 第3正規形 (3NF: 3rd Normal Form)、場合によってはボイス・コッド正規形 (BCNF) まで整理・検討し、重複や不整合を防ぐようなスキーマを構築していきます。
- テーブルの「正規化」については、次回の講義で詳しく解説していきます。
(リレーショナルモデルを前提とした場合の) 論理設計のアウトプットとしては、論理ER図 (Logical Entity Relationship Diagram) や ざっくりとした CREATE 文 (SQL) などがあります。
- ここでの「ざっくりとした CREATE 文」とは、インデックスや制約といった細部は省き、テーブル名・カラム名・データ型といった骨格を実装依存しない標準SQLで記述したものと考えてください。
(プロンプト例)
データベースに関する文脈で「実装依存しない標準SQL」とはどういうことですか。具体的な例を含めて解説してください。ちなみに自分は PostgreSQL で DB の勉強をしています。
概念ER図と論理ER図の違い (目的や情報粒度の違い) について教えてください。
データベースに関する文脈で、単に「ER図」といった場合、概念ER図と論理ER図のどちらを指しますか。
2.4 物理設計
物理設計 では、PostgreSQL や MySQL などの具体的な実装 (ソフトウェア) と、その運用環境 (ハードウェア構成) を意識した設計を行ないます。この段階では、テーブルや制約、ビューなどの定義に関わる DDL (Data Definition Language) に加え、ユーザのアクセス権限やロール管理などを扱う DCL (Data Control Language) も検討します。
具体的には、インデックス定義 (CREATE INDEX)、外部キー制約や検査制約
(FOREIGN KEY、CHECK)、ストレージ構成・冗長化・バックアップ方針・負荷分散設計
など、性能・可用性・保守性を意識したチューニングを含みます。
3 データベースの概念設計
データベースの 概念設計 (Conceptual Design) では、対象世界 (現実世界) の情報構造を抽象化したモデルを作成します。具体的には、ヒアリングや資料分析などを通じて業務要件を把握し、データベースで管理すべき情報の全体像を概念データモデル図として描きます。
教科書的・設計論的には、概念設計はデータベースモデルに依存しない設計とされていますが、ここでは、リレーショナルデータベースを前提として、システムが対象とする世界の情報構造を 概念ER図 として表現する方法について学んでいきます。
3.1 概念ER図とは
概念ER図 (Conceptual Entity Relationship Diagram) とは、対象世界の情報構造を エンティティ (Entity、実体) と、リレーション (Relationship、関連) という2種の要素でモデル化した図になります。
例えば、ウェブの「ブログサービス」を対象としたとき、次のような概念ER図を作成することができます。
ここで、図内の四角形 (User や Article など) が「エンティティ」を表し、青色の線 (has や creates など) が「リレーション」を表します。特にリレーションの表現法 (表記法ルール) の違いにより、同じER図でも IE記法 (アイイー記法) や IDEF1X記法 (アイデフワンエックス記法)、Chen記法 (チェン記法) など様々な表現が存在しています。
- 実際に
概念ER図で検索すると、様々な記法 (独自のカスタマイズを含む) が存在することが確認できます。- 「概念ER図」を画像検索した結果@ Google検索 (画像)
実業務ではIE記法 (特に Crow’s Foot記法) がよく使用され、基本情報技術者試験やデータベーススペシャリスト試験などのIPAの試験では、IDEF1X記法に準拠した表記が使用されています。
参考 📖 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」の pp.151-156「4-3 ER図の描き方 (IE記法・IDEFX1記法)」
- IDEFX1記法については、教科書に記法の解説があるので、それを参照してください。本講義では、IE記法のみを扱います。
IPA の各種試験が CBT 方式に変更
2026年度から応用情報技術者試験も、ペーパーテスト方式 から CBT方式 に変更されます (詳細 )。なお、既に「ITパスポート」と「基本情報技術者」は CBT方式 で実施されています。
以下、概念ER図を構成する「エンティティ」と「リレーション」という要素について解説していきます。
3.1.1 定着確認
- 次のような概念ER図を作成した。図のなかで「Article」や「Comment」のように四角形で示されている要素を何というか。英語で答えよ。
- 答え: Entity
- 次のような概念ER図を作成した。図のなかで四角形同士を接続している要素を何というか。英語で答えよ。
- 答え: Relationship

3.2 エンティティとは
RDB において「テーブル」に相当するものが エンティティ (Entity) となります。日本語では「実体」と訳されますが、必ずしも物理的な存在を意味するわけではなく、イベント (出来事) や 抽象的な概念 もエンティティとしてモデル化されます。
例えば、ブログであれば、Article (記事)、Comment (コメント)、Category (カテゴリ)、User (ユーザ) といったものが「エンティティ」としてモデル化されます。概念設計の段階では細部までは詰めませんが、エンティティは、一般に複数の アトリビュート (属性) を持ちます。アトリビュートは、RDB で カラム に相当するものです。例えば、Article エンティティは、title (タイトル)、body (本文)、created_at (作成日) といったアトリビュートを持つと考えられます。
- オブジェクト指向の考え方で言えば、オブジェクトが エンティティ、プロパティが アトリビュート にあたります。
エンティティとして扱うか、アトリビュートとして扱うかの判断
ある要素をエンティティとアトリビュート (属性) のどちらで扱うかは 設計目的や運用文脈に左右されるもので、一般的な指針はあるものの、絶対的な正解は存在しません。とはいえ、この選択を誤ると、ビジネスロジックやデータ処理の実装に支障をきたし、大きな技術的負債となります (あとから修正するときのコストは非常に大きいです)。
- データベース設計について、AIの提案を十分に検証せずに採用すると、設計全体に長期的な悪影響を及ぼす技術的負債が生まれる可能性があります。
エンティティにするかアトリビュートにするかの判断は、システム全体の設計意図を踏まえ、要件の本質に基づいて決定することが求められます。
たとえば「住所」は単なる文字列のアトリビュートとして扱えますが、顧客・店舗・倉庫など複数のエンティティから参照されるなら、エンティティとして独立させた方が一貫性維持の観点で有利になってきます。また「所持金」もアトリビュートにできますが、履歴を管理したい場合はエンティティ化することが正解となります。
- ただし、過度にエンティティに分割すると理論的には美しくても実装が複雑となり、
SELECTの記述が肥大化して (JOINによる結合の嵐が生じて) 実行パフォーマンスが低下します。設計時には「どの粒度で分けるか」を意識した判断が求められます。
概念設計でアトリビュート (属性) を表現したい場合は?
エンティティに持たせる アトリビュート (属性) を詳細に検討・設計するのは
論理設計段階の作業
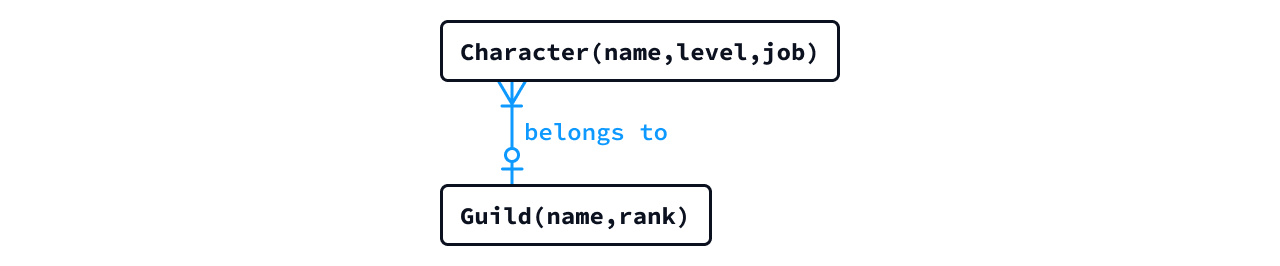
となります。そのため、概念設計のアウトプットである「概念ER図」には、通常、アトリビュートを記載しません。ただし、情報構造の理解を補うために
代表的なアトリビュート を Character (name, level, job)
のように括弧書きで添えることもあります。
または、概念ER図とは別に、以下のような簡易ドキュメントを作成することもあります。
- Character
- name
- level
- job
- Guild
- name
- rankただし、概念設計の目的が、全体的な情報構造の共有であるため、代表的なアトリビュートに限って記載すること が推奨されます。
- アトリビュートを詳細に検討しようとすると、結局のところデータベースモデル (リレーショナルモデルなのか、ドキュメントモデルなのか) を意識せざるを得なくなります。しかし、概念設計はモデル非依存を原則としているため、その段階で詳細なアトリビュートの検討や設計をすることは本質的に矛盾したものとなります。
(プロンプト例)
データベースの概念設計において、ある要素を「エンティティ」にすべきか、「アトリビュート」にすべきか、一般的な指針や考え方について様々な観点から解説してください。
3.2.1 定着確認
- 概念ER図のエンティティとは、RDB における ( ) に相当する要素である。
括弧にあてはまる適切な語を答えよ。
- 答え: テーブル
3.3 リレーションとは (多重度のみの表現)
ER図において リレーション とは「エンティティ同士の関連 (結びつき) を表現するもの」となります。例えば、ブログシステムにおいて…
- 1つの Article (記事) は 複数の Comment (コメント) を持つことができる。
- 1つの Comment (コメント) は ただ1つの Article (記事) に属する。
…のようなエンティティ間の関連があるとき、ER図では次のような線 と Crow’s Foot (カラス足) という先端記号でリレーションを表現します。

Crow’s Foot は、カーディナリティ (多重度) と呼ばれる エンティティ同士の 数量的な範囲や制約 を表現したものになります。
例えば、下図の ❶ のようなカラスの足マーク (多
の記号表現) は「1つの Article は、複数の Comment
を持つことができる」という数量的性質を表しています。

一方、❷ のような縦棒 (数字の 1 の記号表現) は、
「1つの Comment は、1件の Article
に属する」という数量的性質を表しています。
このようなエンティティ同士の関係を、文字では「Article と Comment に 1対多 や
1:多、1:N の関係がある」のように表現します。
別な例で考えてみます。例えば、ER図で Student (学生) と Subject (科目)
というエンティティが、以下の図ように表現されている (=リレーションの 両端 が
多 となっている) とします。

このとき、このER図は次のことを表現しています。
- 1人の Student は、複数の Subject を受講できる (A Student takes multiple Subjects.)。
- 1つの Subject は、複数の Student が受講している (A Subject is taken by multiple Students.)。
ER図の関連名 (Relationship Name) について
IE記法のER図では、下図の has
のように、リレーションを表す線上に関連名 (Relationship Name)
を付けることがあります。これは 動詞句 (Verb Phrase)
とも呼ばれ、関係性を自然言語的に表現するためにつけられます。補助表現であるため、関係が明らかな場合には省略 されることもあります。
なお、関連名/動詞句は「どちらのエンティティを基準にするか」によって表現が変わります。上記の例は、Comment
を基準に関連名/動詞句を記述すれば belongs to という表現になります。

どちらを基準 (主語) に表現するかについて明確なルールはありませんが、一般には「より中心的なエンティティ」または「動作・行為を起こす側」を基準 (主語) にすることが多いです。
ER図でよく使用される関連名 (動詞句) としては、次のようなものがあります。
- has / belongs to
- contains / is contained in
- creates / is created by
- manages / is managed by
3.3.1 定着確認
- 次の ER図におけるエンティティ A と B の関係を適切に表現しているものをすべて答えよ。
- ➊ 1件の A は、複数件の B に関連する
- ❷ 1件の B は、複数件の A に関連する
- ❸ 1件の A は、1件の B に関連する
- ❹ 1件の B は、1件の A に関連する
- ❺ A と B は
1:多の関係にある - ❻ A と B は
多:多の関係にある - ❼ A と B は
多:1の関係にある - 答え: ➊、❹、❺

- エンティティ A、B、C、D、E がある。次の要件を満たすように概念ER図を作成せよ。
- 1件の E は、1件の D に関連する
- 1件の D は、複数件の E に関連する
- 1件の D は、複数件の C に関連する
- 1件の C は、複数件の D に関連する
- 1件の A は、1件の E に関連する
- 1件の E は、1件の A に関連する
- 答え: 概念ER図
- 次の要件を満たすように概念ER図 (IE記法・Crow’s Foot記法で、関係名も記述)
を作成せよ。なお、オプショナリティは考慮せず、カーディナリティのみを考慮するものとする。
- 学校の授業管理システムを考える。
- エンティティは Student (学生)、Teacher (教員)、Subject (授業)、Room (教室) とする。
- 1人の Teacher は、複数の Subject を担当する。
- 1つの Subject は、複数の Student に受講される。
- 1つの Subject は、1人の Teacher が担当する。
- 1人の Student は、複数の Subject を受講する。
- 1つの Subject は、1つの Room を利用する。
- 1つの Room は、複数の Subject で利用される。
- 答え (作成例) : 概念ER図
{kind=link}
{kind=link}
3.4 リレーションとは (多重度と任意性の表現)
前のセクションでは、カーディナリティ (多重度) のみに着目してリレーションを表現しました。しかし実際の ER図では、そのリレーションが 必ず存在するのか、それとも存在しない場合もあるのか を示す オプショナリティ (任意性) についても明示することが推奨されます。
オプショナリティは、以下のように「必須」を 1
を模した記号で表現し、「任意 (存在しないこともある)」を 0
に模した記号を使って表現します。

上記の例では、右側の Comment エンティティに接する記号が、多
を示すカーディナリティ記号と、0 (=任意)
を示すオプショナリティ記号 の組み合わせになっています。これは「1つの Article
は、0 個以上の複数の Comment を持つことができる (=Article は Comment
を持たない場合もある)」ということを表現しています。
一方で、Article エンティティに接する記号は、1
を示すカーディナリティ記号と、1
を示すオプショナリティ記号の組み合わせであり、「1つの Commente は、必ず1つの Article
に属さなければならない (=Article に属さない Comment
は存在し得ない)」ということを表現しています。
少し視点を変えれば、オプショナリティはエンティティ同士の数量的な範囲の
下限 (0 または 1)
を表し、カーディナリティは数量的範囲の 上限 (1 または
多) を表しているとも言えます。データベース設計では 1..* や
0..1 のように範囲表現することがありますが、この下限が
オプショナリティ、上限が カーディナリティ に対応します。
カーディナリティとオプショナリティを組み合わせてリレーションを表現するとき、Crow’s Foot記法では以下の4パターンが存在します。

以降、(試験や小テストを含めて) 特に指示の無い限り、ER図はカーディナリティとオプショナリティの両方を考慮した表現を利用するようにしてください。
リレーションの具体的な上限数は考慮しないのか?
概念設計や論理設計では、リレーションの数量関係を
0、1、多 の3区分で扱います (多
については、* や N のように表記することもあります)。
これは、概念設計/論理設計が「データ構造を定義するプロセス」であり、「3つまで」や「5件まで」といった 具体的な数値制約は構造そのものには影響しないため です。RDB のテーブル構造に影響するのは「単数」か「複数」かの区別だけになります。
そのため「キャラクタは最大3つのギルドに所属できる」というルールが存在あったとしても、ER図
においては単に 1:多 のリレーションとして表現します。
具体的な数値をともなう上限制約は、物理設計やアプリケーション側の制御ロジックで扱う領域となります。
3.4.1 定着確認
- ER図の文脈において「オプショナリティ」は日本語で何と表現されるか。漢字3文字で答えよ。
- 答え: 任意性
- ER図の文脈において「カーディナリティ」は日本語で何と表現されるか。漢字3文字で答えよ。
- 答え: 多重度
- 数量の範囲表現
0..*に対応した Crow’s Foot 記法の表現は、次の図のうちどれか答えよ。- 答え: (1)

- Character (キャラクタ) とGuild (ギルド)
というエンティティを考え、次の関係を適切に表現した概念ER図を作成せよ。なお、Character
を主語とした適切な関係名/動詞句も記載すること。
- Character は Guild に所属しなくてもよいが、所属する場合は1つの Guild のみに所属する。
- Guild には少なくとも1人の Character が所属していなければ存在できない。
- 答え : 概念ER図
- Character (キャラクタ) と Item (アイテム)
というエンティティを考え、次の関係を適切に表現した概念ER図を作成せよ。なお、ここでの Item
とは、個々の所有インスタンス (実体) ではなく、アイテムの種類 (種別情報)
を表すものとする。ER図には Character を主語とした適切な関係名/動詞句も記載すること。
- Character は、0 個以上の複数の Item を持つことができる。
- Item は、0 人以上の Character に所有される。
- 答え : 概念ER図
- 次の概念ER図を、正しく説明してる文章には「True」を、そうではない文章には「False」を答えよ。なお、図内の動詞句
belongs toは、いずれもエンティティ B を主語として読むものとする。A と C は組織、B は人として考えるとよい。- 1つの A には、ただ 1人 の B が所属する。答え: False
- A には、1人 の B も所属しないこともある。答え: False
- C には、0人 もしくは 1人 の B が所属する。答え: False
- 1人の B は、ただ1つの C に所属できる (所属しないことも可)。答え: True
- 1人の B は、ただ 1 つの A に所属しなければならない (複数の A に所属は不可)。答え: True
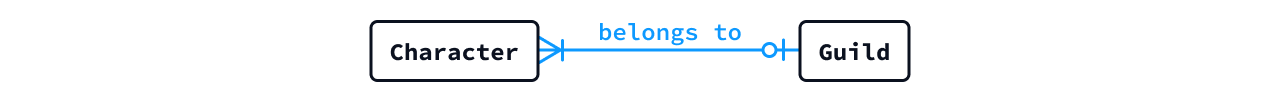{kind=link}
{kind=link}

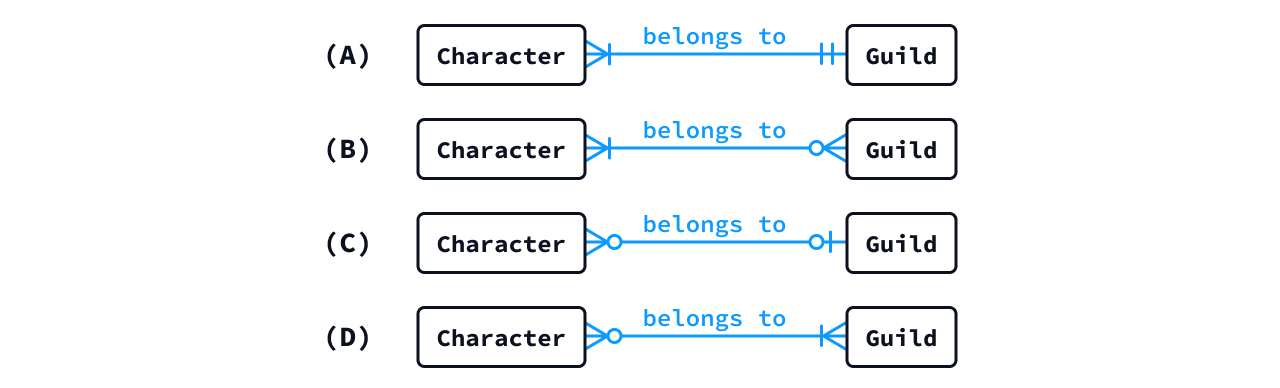
- 次に示す各説明を最も適切に表現した概念ER図を記号で答えよ。
- (1)
各キャラクタは、特定のイベントをクリアした後、3つのうち1つのギルドを選択して所属することができる。各ギルドは運営が作成するものであり、誰もメンバがいない状態もあり得る。
- 答え: (C)
- (2)
各キャラクタは必ず1つのギルドに所属しなければならない。メンバが0名のギルドは存在し得ない。
- 答え: (A)
- (3)
各キャラクタは、必ず1つ以上のギルドに所属している必要がある。各ギルドは0名以上のメンバで構成される。
- 答え: (D)
- (4)
各キャラクタは、最大で3カ所のギルドに所属することができる。また、どのギルドにも所属しない選択もある。各ギルドは1~32名のメンバで構成される。
- 答え: (B)
- (1)
各キャラクタは、特定のイベントをクリアした後、3つのうち1つのギルドを選択して所属することができる。各ギルドは運営が作成するものであり、誰もメンバがいない状態もあり得る。
3.5 概念ER図を作成することの意義
概念ER図 (概念データモデル) を作成・共有することで、自然言語での説明では曖昧になりやすい関係性 を 明示的かつ一貫した形式で表現して共有 することができます。図による共有は、モデルの構造的理解を助け、結果としてチーム開発におけるメンバー間の理解の齟齬や、それによる手戻りを防ぐことにつながります。
また、適切なツールを用いて作成すれば、文章を記述するよりも効率的かつ短時間でER図を作成することができます。たとえば、以下の概念ER図に相当する情報を文章で記述すると…
以下のようになります。エンティティの数が増え、それにともないリレーションが増えたとき、自然言語による説明ではとんでもない文章量になることが分かると思います。
- 1人の User は、0 件以上の複数の Article を作成して持つことができる (Article を1件も持たないこともあり得る)。
- 1件の Article は、ただ1人の User に属する。
- 1件の Article は、0 件以上の複数の Commnent を持つことができる (Comment を1件も持たないこともあり得る)。
- 1件の Commnent は、ただ1件の Article に属する。
- 1件の Commnent は、ただ1人の User に属する。
- 1人の User は、0 件以上の複数の Commnent を作成して持つことができる (Commnent を1件も持たないこともあり得る)。
- 1件の Article は、必ず 1つ以上の Category に属する (どの Category にも属さないことは認められない)。
- 1つの Category は、0 件以上の複数の Article を持つことができる (Article を1件も持たない Category もあり得る)。
また、個々の説明から分かるように、誤解や認識の齟齬を避けようと丁寧に記述すると、どうしても説明が冗長になりがちで、その作成や校正は非常に煩雑なものとなります。さらに、文章の列挙では リレーションの漏れ が生じやすく (また、それに気づきにくく)、全体像を把握することも困難となります。
以上のようなことから、データベース設計では ER図 などが活用されます。ジュニアレベルの新米エンジニアでも、現場ではER図を正しく読み解くことが求められるので、次のセクションの論理ER図を含めて、しっかりと学ぶようにしてください。
3.6 概念設計からモデル選定へ
概念設計が完了したら、次は データベースモデルの選定 を行ないます。ここでは、作成された概念ER図 (概念データモデル) をもとに、代表的なユースケースを具体的に想定しながら、次のような観点から検討します。
- どのような問い合わせ (検索・集計)
や更新処理を、どの程度の一貫性のもとで、どの程度の速度で実行する必要があるか
- 複雑な検索・結合・集計を行い、トランザクション整合性を重視するなら RDB
- 構造が柔軟で、ドキュメント単位での一貫性を確保できれば十分なら DocDB
- 単純なキーアクセスで超高速レスポンスを重視するなら KVS
- 将来的に、どの程度のデータ構造 (スキーマ) の変更が発生しそうか
- スキーマが安定し、データ整合性を厳密に保ちたいなら RDB。
- スキーマが可変的でユースケースに応じて調整可能な柔軟さが必要なら DocDB
- 構造を意識せず扱いたいなら (データ構造はアプリ側で管理するなら) KVS
- データアクセスは読み取り中心か、頻繁な更新をともなうか
- 更新頻度が高くトランザクション整合性が重要なら RDB
- 読み取り中心で柔軟なレスポンス生成なら DocDB
- ログ出力やセッション管理など、読み書きスループットを重視する用途 なら KVS
- スループットとは、一定時間あたりに処理できる量の意味
このような観点を総合して、要件に対して最も適切なデータベースモデルを選択します。上記で RDB は リレーショナルデータベース、DocDB は JSONドキュメント指向データベース、KVS は キーバリューストア型DB の略です。
なお、このモデルの選定について、本科目では詳しく扱わないので、興味がある学生は、次のようなプロンプトを使って学んでみてください。
(プロンプト例)
データベース設計に関する質問です。データベースの概念設計が完了し、次にデータベースモデルの選定 (リレーショナルモデル、ドキュメント指向モデル、KVS など) を進めていきたいと考えています。一般的には、どのような設計観点や判断基準からモデルを選ぶのか教えてください。
データベース設計に関する質問です。リレーショナルモデル、ドキュメント指向モデル、KVS などがありますが、各モデルについて、どのような要件・設計思想に向いているかを解説してください。
以降は、データベースとして「リレーショナルモデル」が採用されたことを前提に解説を進めます。
3.6.1 定着確認
- システム開発において「ユースケース」とは何か。最も適切なものを選び記号で答えよ。
- ❶ システム内部で使用されるデータ構造を定義したもの
- ❷ システムの画面レイアウトや操作方法をまとめたもの
- ❸ システムが現実世界でどのように使われるかを示す利用シナリオ
- ❹ 実装に用いるプログラム言語や開発環境を示したもの
- 答え: ❸
- セッション情報やログイン状態など、単純なキーアクセスを超高速で処理したいという要求に対して、一般に最も適合するデータベースは「RDB」「DocDB」「KVS」のうちどれか。
- 答え: KVS
- トランザクションをともなうチケット予約管理システムを構築し、同時アクセスでも整合性を保ちたいという要求に対して、一般に最も適合するデータベースは「RDB」「DocDB」「KVS」のうちどれか。
- 答え: RDB
- 商品データの属性が案件ごとに異なり、頻繁にスキーマ変更が発生する可能性があるというシステム要件に対して、一般に最も適合するデータベースは「RDB」「DocDB」「KVS」のうちどれか。
- 答え: DocDB
4 論理設計
論理設計では、概念ER図をリレーショナルデータベースの構造に合わせた形に整理し、次のような 論理ER図 (Logical Entity Relationship Diagram) を作成していきます。
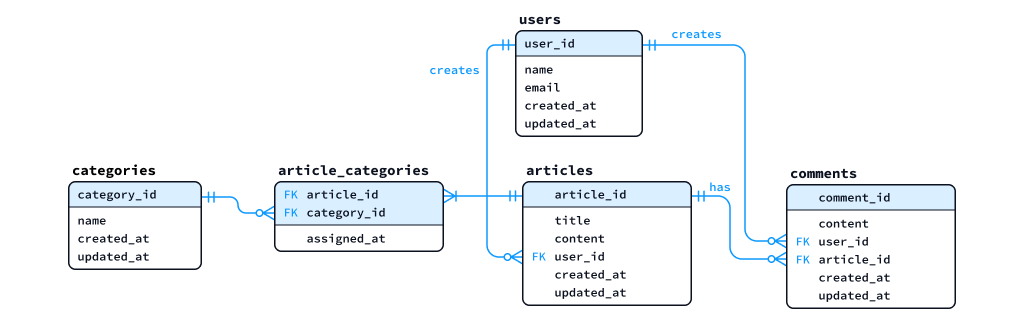
具体的には、概念ER図を次のような要件 (=RDBで効果的・効率的に管理するための条件) を満たすように整え、テーブルやカラム、キーといった RDB での実装を意識した構造に近づけていきます。
- 各エンティティのアトリビュート (属性) を洗い出し、エンティティを「テーブル」、アトリビュートを「カラム」として定義する。
- 階層構造や 列方向の繰り返し構造 を持たない2次元の表 (テーブル) にする。
- 各テーブルの各セルには、スカラー値 のみを格納し、集合・配列・複合型を直接格納しない構造にする。
- 各テーブルにおいて、レコード (行) が一意に識別可能な 主キー (Primary Key) を設定する。
多対多の関係は、中間テーブル (関連エンティティ) を導入して1対多で表現可能な関係に置き換える。- 必要に応じてテーブルを 正規化 (1NF→2NF→3NF) する。
なお、この論理設計では、RDB での管理は意識するものの、PostgreSQL や SQLite のような 個別製品の仕様や制約 については考慮しません。それらは、論理設計につづく物理設計での検討となります。
4.0.1 定着確認
- データベースの論理設計において、エンティティは RDB における ( ① )
に相当する。また、アトリビュート (属性) は、RDB における ( ② )
に相当する。各括弧にあてはまるもっとも適切な語をカタカナで答えよ。
- 答え : ①テーブル。②カラム
4.1 テーブルとカラムの設計
論理設計では、概念ER図の「エンティティ」を RDB の テーブル に対応づけ、また「アトリビュート (属性)」を RDB の カラム に対応づけて情報を整理し、それに基づいて「論理ER図」を作成していきます。
4.1.1 「概念ER図」と「論理ER図」の対応
以下に「概念ER図」と「論理ER図」の一例を示します。2つを見比べて、それぞれの対応関係や、論理ER図で新たに追加されている要素を読み解いてください。
概念ER図の例
論理ER図の例
論理設計は、実際の RDB 設計にかなり近づくため、実務では「エンティティ」や「アトリビュート」よりも、「テーブル」や「カラム」 という表現が使われることが多くなります。設計論的には論理ER図では前者の呼称のほうが適切ですが、本講義では実務での一般的な表現にそろえて「テーブル」と「カラム」という呼び方を用いていきます。
4.1.2 テーブルとカラムの洗い出し
論理設計では、はじめに概念ER図に表したエンティティを「テーブル」として捉え、そのテーブルのカラム構成を検討していきます。この際、一般的な RDB の慣習にあわせて、テーブル名は 可算名詞の複数形・集合名詞のスネークケース、カラム名は 単数形のスネークケース で表記していきます。
また、各カラムの「型」については、文字列型、数値型、日時型といったおおまかな粒度で検討しておきます
(VAECHAR(16)、INTEGER、TIMESTAMP
などの実装依存を含めた具体的な型の決定は物理設計で行ないます)。
以下、概念ER図から、テーブルとカラムを洗い出して整理した一例です (特定の書式があるわけではありません)。
- `users` テーブル (User エンティティ)
- `name` 文字列型
- `email` 文字列型
- `created_at` 日時型
- `updated_at` 日時型
- `articles` テーブル (Article エンティティ)
- `title` 文字列型
- `content` 文字列型
- `created_at` 日時型
- `updated_at` 日時型
(以下、略)この際、テーブルのフィールド (セル) には「スカラー値」つまり 構造を持たない1つの値 が格納されるようにカラムを設計してください。
たとえば、position というカラムに [10,20]
のような「配列」を直接格納したり、class というカラムに
{"grade":4, "course":"I"} のような「辞書
(オブジェクト)」を格納するような設計はアンチパターン (=第1正規化 (1NF) を満たしていないテーブル) となります。
positionは、pos_xとpos_yに分離し、それぞれを独立したカラムとしてスカラー値 (数値) を格納します。classは、gradeとcourseに分離し、それぞれを独立したカラムとしてスカラー値 (数値、文字列) を格納します。
🚨「アンチパターン」とは、やってはいけない設計の典型例 (特に過去に多くの人が失敗している例) のことです。
(プロンプト例)
RDB の設計に関する質問です。キャラクターの位置情報を管理するために、あるテーブルの
positionカラムに[10, 20]のような配列を直接格納しようと思いました。しかし、「それはアンチパターンで、pos_xとpos_yのように別のカラムに分けてスカラー値 (単一の数値) を入れるべき」と言われました。どうして配列をそのまま格納すると良くないのでしょうか。また、実際に配列で格納すると、どんな SQL を書くときに困るのか、初学者向けに例を挙げて説明してください。
参考 📖 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」の pp.228-232「7-2 非スカラ値 (第1正規形未満)」
4.1.3 定着確認
- チームやプロジェクトで命名ルールが決まっていない場合、RDB
のテーブル名には「パスカルケース」「キャメルケース」「スネークケース」「ケバブケース」のうち、どの命名規則に従うことが最も一般的か答えよ。
- 答え: スネークケース
- RDB のテーブル名は、一般に ( ) を用いることが推奨される。 ( )
にあてはまる適切な語を答えよ。
- 答え: 可算名詞の複数形 または 集合名詞
- RDB のカラム名は、一般に ( ) を用いることが推奨される。 ( )
にあてはまる適切な語を答えよ。
- 答え: 単数形の名詞
4.2 繰り返しカラムは別テーブルで管理
テーブルのなかに「同種の情報が繰り返し出現するようなカラム構成」が存在する場合は、その部分を別テーブルとして分離し、それを参照する形
(=リレーションで関連づける形) にします。例えば、characters
テーブルに、以下のように
skill_1、skill_2、skill_3、skill_4
というカラムを設けるような設計は、RDBにおける典型的なアンチパターン (=第1正規化 (1NF) を満たしていないテーブル) となります。
| name | job | skill_1 | skill_2 | skill_3 | skill_4 |
|---|---|---|---|---|---|
| Alice | Priest | Heal | Resurrection | NULL | NULL |
| Bob | Monk | DragonKick | NULL | NULL | NULL |
上記テーブルのように、同種の情報の繰り返し構造を持つ場合は、それを以下のような別テーブル
(ここでは skills テーブルを新たに作成)
に切り出し、縦方向に保持する形式 (=「縦持ち」「行持ち」「long
format」の形式) にすることが求められます。
| character_name | skill | slot_no |
|---|---|---|
| Alice | Heal | 1 |
| Alice | Resurrection | 2 |
| Bob | DragonKick | 1 |
このように情報を分離したとき、概念ER図は次のようになります。

また、論理ER図では次のようになります。

4.3 主キー (Primary Key)
テーブルを構成するカラムが整理できたら、各テーブルの 主キー (PK: Primary Key) を決めていきます。主キーは、そのテーブル内のレコード (行) を 一意に識別できる値を持つカラムに対して設定するもので、他のテーブルから参照される際の 外部キー (FK: Foreign Key) としても使われます。
- 一意に識別可能とは 複数のレコード (行) なかから、迷わずその1行だけを選びだすことができる という意味です。
- RDB
の各テーブルでは、いずれかのカラムを主キーとして設定する必要があります
(原則として設定することが望ましいです)。
- ログ用途やイベント収集用途などでは、明確な主キーを設けない場合もあります。
- PostgreSQL では主キーを設定しないテーブルも作成可能ですが、論理設計では主キーを定義することが原則となります。
たとえば、次のようなテーブルがあるとします。name、nickname、age のうち、主キーにすることができるカラムはどれなのかを検討していきます。
| name | nickname | age |
|---|---|---|
| Alice | Ali | 20 |
| Bob | Bobby | 25 |
| Carol | NULL | 20 |
| David | Dave | 23 |
4.3.1 ageカラムを主キーにできるか?
age カラムは、20 という値を持つレコードが複数存在するので
(また、今後、同年齢のレコードが挿入されることが十分に考えられるので)、age
を主キーにすることはできません。
4.3.2 nicknameカラムを主キーにできるか?
nickname
カラムには重複する値がないので、カラムは重複のない値を持つため、理論上はレコードを一意に識別できます。しかし、RDBMS
には NULL
を許容するカラムを主キーに設定できない決まり があり、nickname
を主キーにすることはできません。
4.3.3 nameカラムを主キーにできるか?
name カラムは NULL を含まず、その値 (Alice や
Bob など) によって一意にレコードを識別できるため、理論上は name
を主キーにすることができます。
ただし、name を主キーに設定すると (RDBMSにより、自動でUNIQUE制約が付与されるため)、同名の別人を追加できなくなるという運用上の制約 が生じます。実際のシステムでは人名の重複は一般的に起こりうるため、name を主キーとするのは現実的ではありません。
- UNIQUE制約 とは、一意性制約 とも呼ばれ、指定したカラム(またはカラムの組み合わせ)について同じ値を持ったレコードが登録されないように保証する制約です。
- 主キーに設定されたカラムには、UNIQUE制約に加えて NOT NULL制約 も自動的に適用されます。
このような問題を避けるには id や character_id
のような人工的なカラムを追加し、連番 や UUID
を割り当てて主キーとするのが一般的です。こうしたカラムを
サロゲートキー (代理キー、Surrogate Key) といいます。サロゲートキー
(整数値の連番) を追加した例を以下に示します。
| id | name | nickname | age |
|---|---|---|---|
| 1 | Alice | Ali | 20 |
| 2 | Bob | Bobby | 25 |
| 3 | Carol | NULL | 20 |
| 4 | David | Dave | 23 |
なお、「学籍番号」や「メールアドレス」のように、現実世界で意味を持ちつつデータを一意に識別可能なカラム (アトリビュート) を ナチュラルキー (自然キー、Natural Key) といいます。
サロゲートキーとして連番を使うべきか、UUID などを使うべきか
サロゲートキーには、整数の連番を使う方法と、UUID (主に v4) や Nano ID などのランダムな識別子を使う方法があります。
- 連番IDは、検索や結合の処理も効率的に行えるため性能面で有利になります。しかし、値が連続して増えるために 外部からデータ件数や登録順序を推測されやすく、また分散環境では 重複や競合が発生しやすい という欠点があります。
- UUID などのランダムIDは、アプリ側で独立して生成しても衝突が起きない という特徴があり、さらに推測耐性があり、列挙攻撃に強いという利点があります。一方で、値のサイズが大きいためにインデックスが肥大化しやすく、また検索性能で連番IDに劣るという欠点があります。
(プロンプト例)
UUID v4 と Nano ID をRDBのサロゲートキーとして使用する観点から比較してください。
ウェブアプリのバックエンドとして使用する RDB において、整数値の連番をサロゲートキーとして使用するときのリスクについて具体的に解説してください。
参考 📖 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」の pp.266-280「8-2 代理キー ~主キーが役に立たないとき~」
4.3.4 定着確認
- RDB において「主キー」を表すアルファベット2文字を大文字で答えよ。
- 答え: PK
- RDB において「主キー」の英語表記 (略語ではない) を答えよ。
- 答え: Primary Key
- RDB
において、NULLを許容しているカラムを「主キー」に設定することはできない。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え: 適切である
- RDB
において学籍番号やメールアドレスのように、現実世界で意味を持ち、さらにデータを一意に識別可能なカラムを主キーにした場合、それはサロゲートキーと呼ばれる。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え: 適切ではない
- RDB において主キーに設定したカラムには、自動的に NOT NULL 制約と ( )
制約が適用される。括弧にあてはまる語を大文字の英語で答えよ。
- 答え: UNIQUE
- UNIQUE制約 を日本語で表記すると ( ) 制約となる。括弧にあてはまる語を漢字で答えよ。
- 答え: 一意性
4.4 複合主キー
テーブルの主キーは、1つのカラムだけでなく、複数のカラムを組み合わせて設定することもできます。このような主キーを、特に複合主キー
(Composite Primary Key) といいます。複合主キーは、多対多 のリレーションを
1対多 に変換するための中間テーブル (詳細は後述) などで頻繁に使われます。
- 複合主キーは、文脈的に主キーであることが分かる場合は、単に「複合キー」とよばれることもあります。
たとえば、以下のようにキャラクタとアイテムの対応関係を管理する中間テーブル
character_items があるとします。このとき character_id と
item_id の2つを組み合わせて、このテーブルの主キー
(複合主キー) とすることができます。
| character_id | item_id | quantity |
|---|---|---|
| 1 | 38 | 3 |
| 1 | 46 | 1 |
| 2 | 10 | 5 |
| 2 | 11 | 2 |
| 2 | 46 | 1 |
複合キーを主キーに設定したとき、その組み合わせに対して UNIQUE制約
が自動的に働きます。そのため、同じキャラクタが同じアイテムを重複して所持するような不整合
(例えば、テーブルのなかに (character_id,item_id,quantity)=(1,38,3) と
(character_id,item_id,quantity)=(1,38,4) というレコードが存在ような状況)
が抑制され、テーブル内の整合性が保たれます。
また、複合主キーを構成する各カラムについては、NOT NULL制約 が自動的に適用されます。
複合主キー v.s. サロゲートキー
中間テーブルの主キー設計、つまり「複合主キーとすべきか」あるいは「サロゲートキーを導入すべきか」は、設計者によって意見が分かれるテーマとなっています。どちらにも一貫した理論的正当性があり、現在のところ明確な定石はありません。興味があれば、複合主キー アンチパターン
などのキーワードで検索したり、生成AIで深掘りしてみてください。
(プロンプト例)
RDBの設計に関する質問です。中間テーブルは、複合主キーにすべきか、サロゲートキーを導入すべきかという主キー設計は、よく議論になると聞きました。双方の主張について詳しく解説してください。
4.4.1 定着確認
- あるテーブルにおいて article_id カラムと category_id
カラムが複合主キーとして設定されている。このとき、article_id カラムには
UNIQUE制約 が自動的に適用されるので、article_id
カラムに同じ値を持つレコードは存在し得ない。この説明 (下線部)
は「適切である」か「適切ではない」かを答えよ。
- 答え: 適切ではない
4.5 論理ER図における主キーの表記
論理ER図において、主キー (PK)
となるカラムを示す表記には、いくつかの方法があります。代表的なものとしては、❶
カラムに下線を引く、❷ id (PK)
のように明示する、あるいは ❸ 四角形の上部を区切って配置する
などがあります。

本講義資料では、上図の右端のように四角形の上部を区切ってPKカラムを配置する表記を主に使用します。
4.6 外部キーを使用した「1対多」のリレーションの表現
概念ER図で 1対多 の関係を持つリレーションは、論理ER図では、1
側のテーブルの主キー (PK) を、多 側のテーブルに
外部キー (FK: Foreign Key)
として保持することで表現します。このようにすると、RDB では SQL の結合操作 JOIN
により、テーブル間の関係を正しく関連づけて扱うことができます。
- 言い換えれば、「他テーブルの主キーを参照する (=値として保持する) カラム」のことを「外部キー」と表現します。
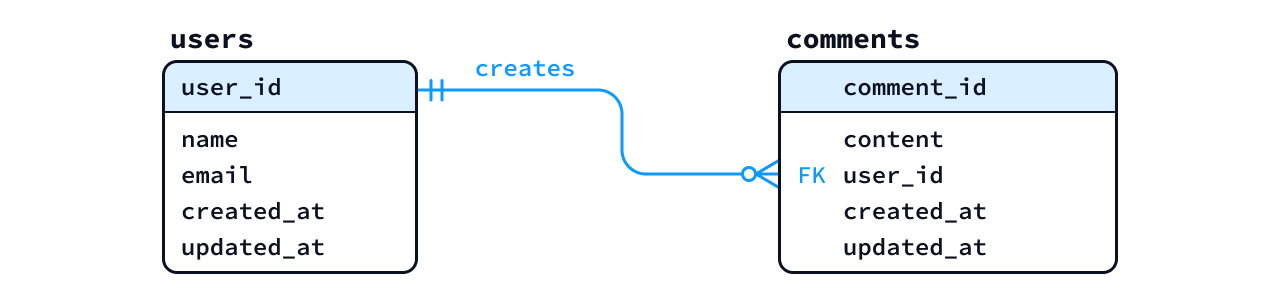
たとえば、ブログシステムの「概念ER図」では、以下のように「Userエンティティ」と「Commentエンティティ」が
1対多 の関係となっています。つまり、1人のユーザーは、0個以上の複数のコメントを作成できる
という関係を表現しています。

この関係を「論理ER図」で表す場合は、以下の図のように comments
テーブルのなかに、users テーブルの 主キー (user_id)
を追加します。このように他のテーブルの主キーを参照するカラムを「外部キー
(FK)」と呼び、論理ER図ではFK という略称で表記します。
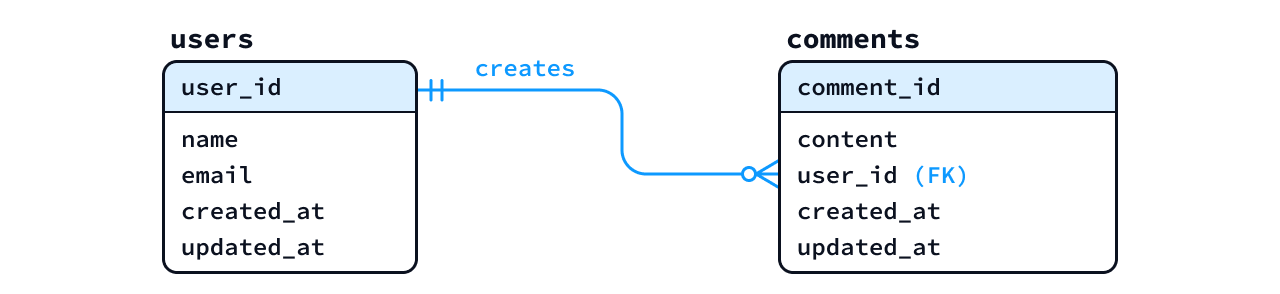
論理ER図では、外部キーを以下のようにカラム名のあとに括弧付きで user_id (FK)
のように示すこともあります。
なお、リレーションはテーブルを表す四角形の任意の位置を端点にできますが、上図のように 「主キー」と「外部キー」を端点 として描くのが最も直感的に理解しやすく推奨されます。
4.6.1 定着確認
- RDB において、値として「他のテーブルの主キー」をとるカラムのことを ( )
という。括弧にあてはまる最も適切な語を答えよ。
- 答え: 外部キー。Foreign Key
- テーブルBは、テーブルAの主キーを参照する外部キーを持っている。このとき、テーブルAから見たテーブルBとのリレーションとして考えられるのは
1対1もしくは( )である。括弧にあてはまる語として最も適切なものは1対多、多対1、多対多のうちどれか答えよ。- 答え: 1対多
- RDB において「外部キー」を表すアルファベット2文字を大文字で答えよ。
- 答え: FK
- RDB において「外部キー」の英語表記 (略語ではない) を答えよ。
- 答え: Foreign Key
- 次に示すような characters テーブルと、jobs
テーブルから構成される RDB が存在する。各テーブルにおいて主キーとなるカラムは 下線
で示している。以下の各問いに答えよ。
- characters の job_id カラムは、jobs
テーブルの主キーを参照し、その値を保持している。このようなカラムを ( )
という。括弧にあてはまる最も適切な語を答えよ。
- 答え: 外部キー
- characters テーブルからみた jobs
テーブルとのリレーションとして、最も適切なものは
1対1、1対多、多対1、多対多のうちどれか答えよ。- 答え: 多対1
- 論理ER図を作成せよ。ただし、characters テーブルの job_id
カラムには NOT NULL 制約 があると仮定すること。
- 答え: 作成例
- 論理ER図を作成せよ。ただし、characters テーブルの job_id
カラムは
NULLも許容されると仮定すること。- 答え: 作成例
- characters の job_id カラムは、jobs
テーブルの主キーを参照し、その値を保持している。このようなカラムを ( )
という。括弧にあてはまる最も適切な語を答えよ。
{kind=link}
{kind=link}
▼ characters テーブル
| character_id | name | job_id |
|---|---|---|
| 1 | Alice | J5 |
| 2 | Bob | J2 |
| 3 | Charlie | J6 |
| 4 | Ellen | J6 |
▼ jobs テーブル
| job_id | name |
|---|---|
| J1 | Fighter |
| J2 | Monk |
| J3 | Ninja |
| J4 | Samurai |
| J5 | Priest |
| J6 | Wizard |
4.6.2 演習
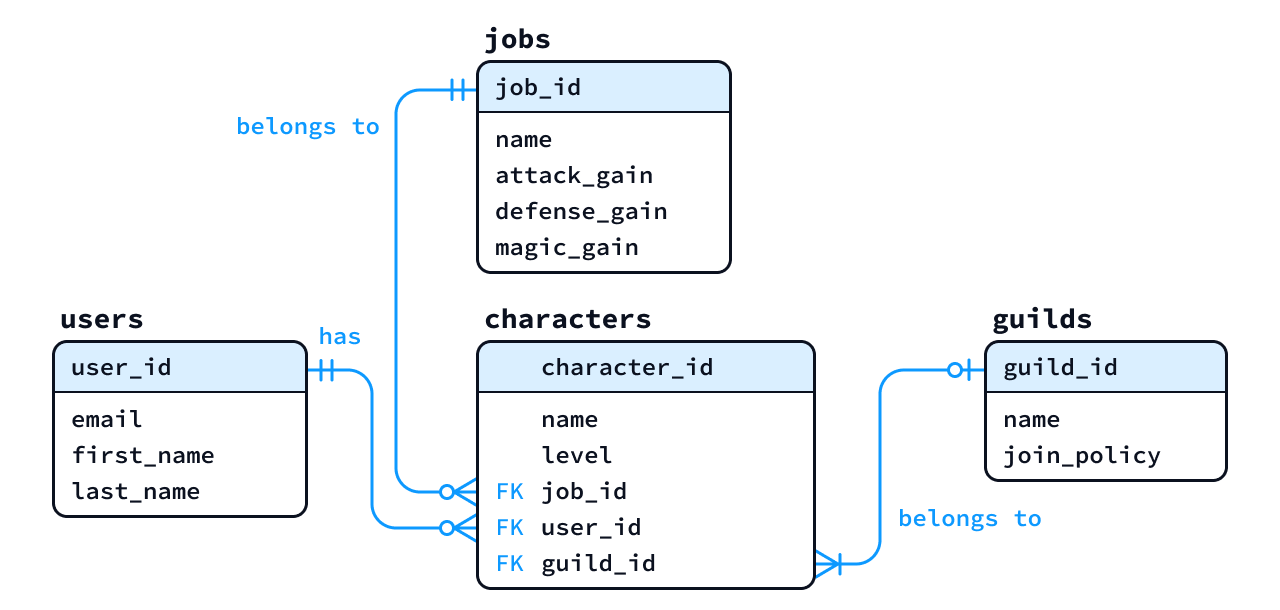
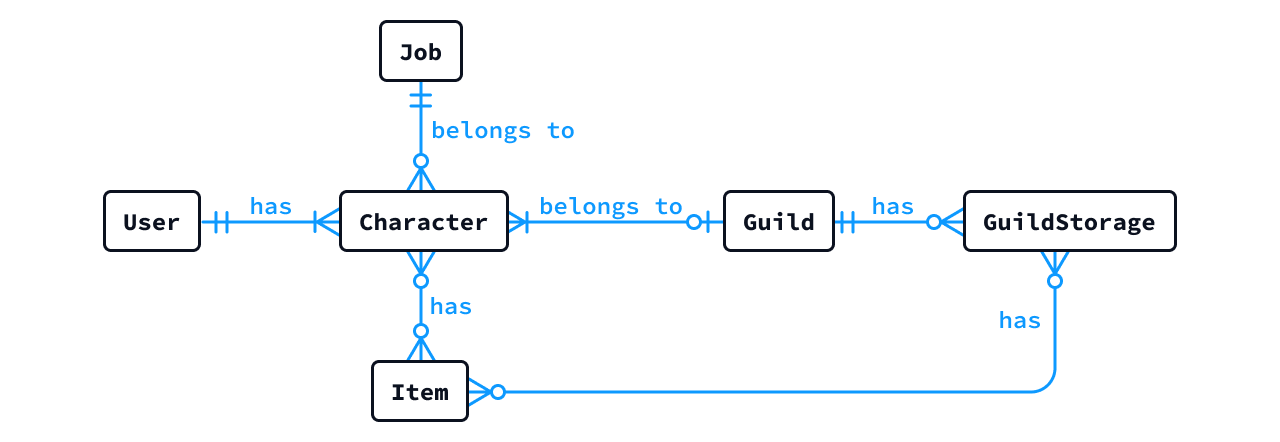
次に示す概念ER図を参考に、User、Character、Guild、Job エンティティに直接関係する範囲の「論理ER図」を作成せよ (Item および GuildStorage エンティティは対象としなくてよい)。なお、論理ER図のテーブルとカラムの名前は英語で適切に設定すること (必要に応じて生成AIを活用すること)。また、各エンティティは、少なくとも次のアトリビュート (属性) を持たせること。
- Userエンティティ: ID、電子メール、姓、名
- Characterエンティティ: ID、名前、レベル
- Guildエンティティ: ID、名前、参加ポリシー
- Jobエンティティ: ID、名前、攻撃補正、防御補正、魔法補正
- 答え (作成例) : 部分的な論理ER図
{kind=link}
(プロンプト例)
RDBのDB設計をしています。テーブルのカラム名 (英語・スネークケース) を検討する手伝いをしてください。MMORPGの世界観において、
jobsテーブルのカラム (属性) として「攻撃補正」「防御補正」「魔法補正」の命名案を複数提案してください。
4.7 多対多のリレーションの分割 (中間テーブル化)
RDB では、2つのテーブル間の 多対多 となる関係を 直接的に定義すること
ができません。そのため、両者を仲介する中間テーブル
(関連エンティティ) を設け、1対多 と 多対1
の関係に分解して扱います。
たとえば、ブログシステムでは「Articleエンティティ」と「Categoryエンティティ」が
多対多
の関係となります。つまり、1つの記事は「1つ以上の複数のカテゴリ」に属することができ、同時に、1つのカテゴリは「0個以上の複数の記事」を持つことができるという関係になります。
この関係を概念ER図では以下のように表現しました。

これを論理ER図に落とし込むときには、article_categories
という中間テーブルを設けて、以下のように変換します (RDB
でも同様にこの構造で実装します)。なお、中間テーブルの名前は任意ですが、一般に 両側のエンティティ名を組み合わせる方法 がよく用いられます。

参考 📖 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」の pp.157-158「4-4 「多対多」と関連実体」
4.7.1 定着確認
- RDB
の設計において「多対多」のリレーションを、テーブル間に直接定義することはできない。そのため、両テーブルの間に
( )
を作成し、これを介して「1対多」と「多対1」のリレーションに分割して設計する。括弧にあてはまる語を答えよ。
- 答え : 中間テーブル または 関連エンティティ
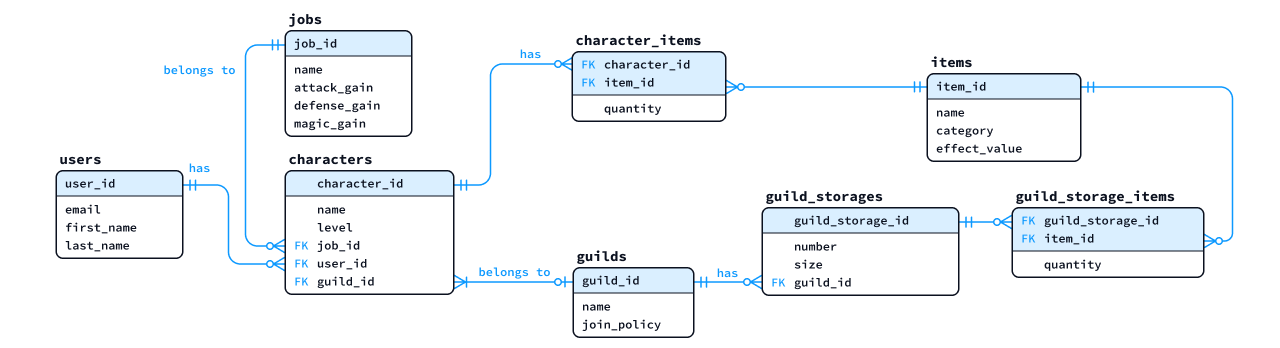
- (前セクションの演習のつづきとして)
次に示す概念ER図を参考に「論理ER図」を作成せよ。各エンティティは、少なくとも次のアトリビュート
(属性) を持たせること。
- Itemエンティティ: ID、名前、種別 (整数値)、効果量 (整数値)
- GuildStorageエンティティ: ID、番号、サイズ
多対多の関係は、中間テーブルを用いて1対多、多対1に落とし込む必要がある点に注意すること- 答え (作成例) : 論理ER図
{kind=link}
5 課題1
- 内容 : 後述の指示に従い、任意のツールを使用してER図を作成し、指定のWordファイルに貼り付けて提出してください。
- 提出期限 : 11月26日 (水) 23時
- 課題の採点後は、修正版の再提出や追提出があっても原則として再評価はしません。
- 担当教員に事前相談することなく、提出期限から168時間(=1週間・7日間)を超過して提出されたもの(再提出を含む)は、未提出と同じ0点評価とします。
- 採点 : 7.5点
を標準として、10点満点で評価 します。
- 本科目では、本課題を含めて最大で3件の課題を出題する予定です。
- 総合成績において課題は 20% に相当します。
- 提出先 :
Teamsの「DB-課題1」にWordファイルを提出 👉📄雛形ファイル
- 🚨PDFに変換せずに、Wordファイルのまま提出してください。
- 作成例を参考にして、2頁以内に収めてください。
- ファイル名は
NN-フルネーム.docxとしてください。NNにはゼロ埋め半角で出席番号、フルネームは姓と名にスペースを入れない漢字氏名としてください。ファイルネームのミスは2点減します。 - 提出された課題は、クラスの学生に共有します。
本課題には、ER図を作成するための適切なツールを選定すること、ツールの使い方を自分で学ぶこと、実務水準の見やすく整った正確なER図を作成・出力することも学習内容として含んでいます。
- 本講義資料のER図はFigmaを使用して作成しています。
5.1 提出ファイル作成に関する注意事項
雛形のWordファイルは、ダウンロードして、必ず デスクトップアプリ版の Word を使って編集 してください。
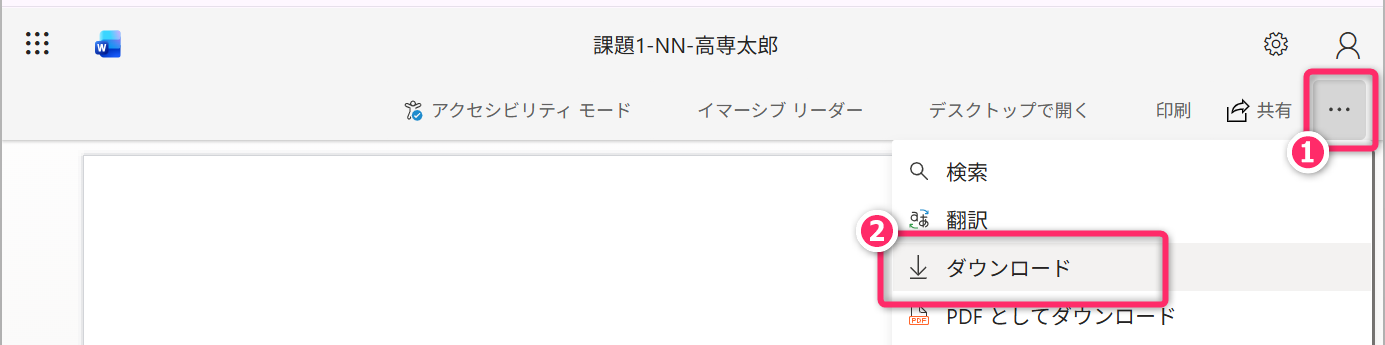
ブラウザ版 (Word for the Web) や Teams版 で閲覧・編集すると、体裁や設定が崩れることがあります(減点対象)。ブラウザで開いてしまった場合は、次の手順でデスクトップアプリで開き直してください。
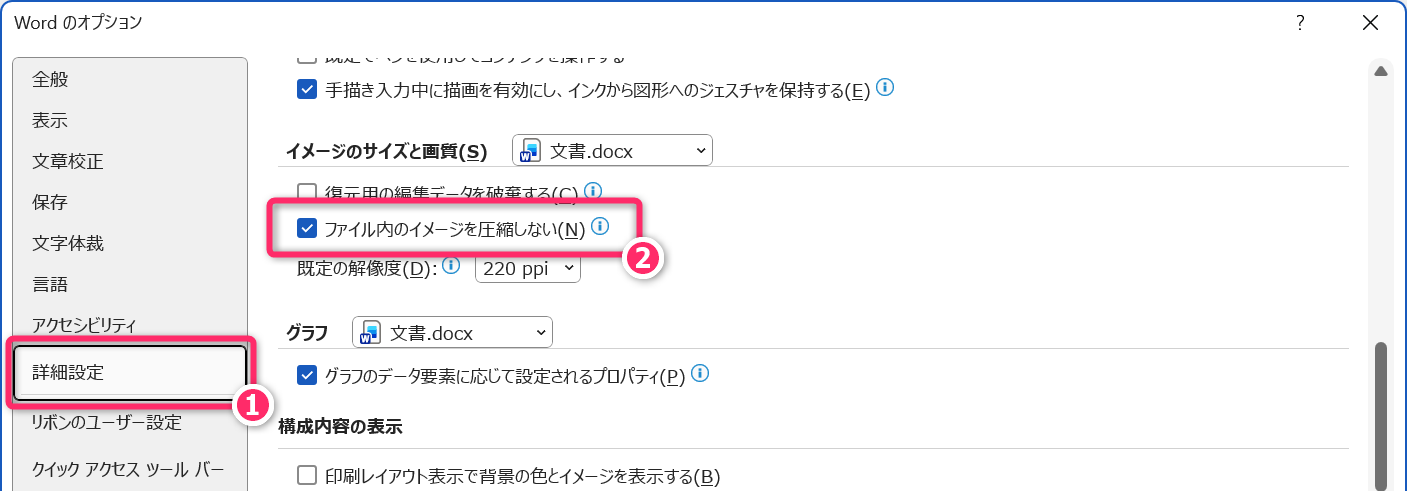
Word のオプションから「画像が自動圧縮されない設定になっていること」を確認してください。
🚨 ER図をラスタ形式 (PNG など) で貼り付ける場合は、印刷時の出力解像度が 300dpi 以上 となるようにしてください。A4 用紙に貼り付けた際の実寸が 約16cm (≒6.3インチ) であれば、6.3 inch × 300 dpi = 1,890 px となるため、図の横幅は少なくとも 1,890 ピクセル以上 としてください。
🚨 ER図をベクタ形式 (SVG や WMF など) で貼り付ける場合は、解像度を意識する必要はありません。ただし、フォントをアウトライン化するなどして、どの環境でも文字化けや崩れが起きないよう配慮してください。
提出された課題は、カラー印刷して紙面上で評価します。提出前には実際に印刷して内容や仕上がりを確認するようにしてください。
(プロンプト例)
学校の課題で次のような指示を受けました。フォントのアウトライン化とは何ですか?👉「ER図をベクタ形式 (SVG や WMF など) で貼り付ける場合は、フォントをアウトライン化するなどして、どの環境でも文字化けや崩れが起きないよう配慮してください。」
5.2 課題内容
次の「演習1」から「演習3」について取り組んでください。演習 (=ER図の作成) には すべて同じツールを使用して取り組んでください。
5.2.1 演習1
次に示す「概念ER図」と同じ情報&論理構造の概念ER図を作成して、それを雛形ファイルに貼り付けてください。
5.2.2 演習2
次に示す「論理ER図」と同じ情報&論理構造の論理ER図を作成して、それを雛形ファイルに貼り付けてください。
5.2.3 演習3
本校の 本科4年生 を利用者とした 提出物管理システム (ウェブアプリ) を題材としてデータベース設計を行い、「論理ER図」を作成して、それを雛形ファイルに貼り付けてください。
- テーブル名とカラム名は「英語」もしくは「ローマ字表記」のどちらか統一し、スネークケース
を使用してください。
- 英語表記とする場合は、テーブル名は「名詞の複数形または集合名詞」、カラム名は「名詞の単数形」にしてください。なお、応用専門分野や専門課題学習のような用語については、部分的に「ローマ字表記」を使用しても問題ありません。
- 中間テーブルにかかるリレーションを除いて、原則として関連名 (動詞句) も記載してください。
- 必要に応じて、以下のように大まかな型や日本語での説明補足をつけてください。

5.2.4 共通の指示事項
- 一般的に IE記法 (Crow’s Foot記法)
と言える範疇のものであればスタイルは自由に決定し、エンティティ配置や PK・FK
の表記法など、論理構造に影響しない要素は任意に決めてください。
- 特に 演習1 と 演習2 について、エンティティの配置などを必ずしも見本と一致させる必要はありません。
- 論理構造が正しいこと (適切であること)および図として読みやすく整っていることが評価の観点となります。
- 演習3 については、設計内容の適切さも評価の観点となります。
6 授業時間外学習の指示 (宿題)
🚨本科目は「学修単位科目」であり、1回の講義あたり「4時間相当」の授業時間外学習が求められる科目です🏃
- 課題1 に取り組んでください。
- 次回の講義で「小テスト❻」を実施します。
- 定着確認から主に出題します。
- 後期中間試験 (60分・筆記試験) については、次回講義で詳細を連絡します。
- A5サイズ両面のメモ (手書き) は持ち込み可とします。試験終了時に回収します。
- 主に「定着確認」と「SQLドリル」から出題します。
- 次回の講義では、論理設計の仕上げとして「正規化」と「基礎的な物理設計と
CREATE文」を扱います。予習として📖 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」の以下ページを読んできてください (前回の予習指示と重複しますが、今回の授業内容を踏まえて、再度、読むことで理解が深まると思います)。- pp.89-123 第3章「論理設計と正規化」
- 3-3 正規化とは何か
- 3-4 第1正規形
- 3-5 第2正規形~部分関数従属
- 3-6 第3正規形~推移的関数従属
- pp.89-123 第3章「論理設計と正規化」
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。