1 連絡と準備
小テスト❻ を実施します。
- シラバス記載のように、小テストは最終評価の 35% に相当します。
- 遅刻・欠席等により追試験を希望する場合は第01回講義で案内した手続きをしてください。
課題1の提出期限は 11月26日 (水) 23時 です。
参考 👉 2025年度プログラミング3 (3年生) の 課題1 (TodoApp) の作品共有 (学内のみ)
1.1 後期中間試験に関する連絡
後期中間試験 (筆記試験) は、11月28日 (金) の2時限目に試験時間 60分 で実施します。
1.1.1 持ち込み品について
- ER図の作図も出題予定なので よく消える消しゴム と 直定規 を準備してください。
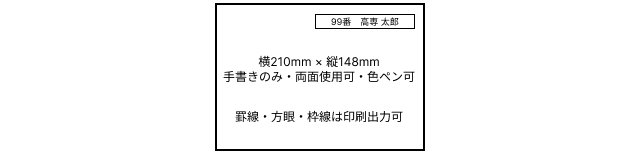
- A5サイズ1枚の手書きのメモ (両面使用可・色ペンなど使用可)
を持ち込み可とします。持ち込みメモは、答案とともに提出してもらいます
(採点後に答案とともに返却します)。
- 片面の 右上部に横10cm、縦1.5cmの四角枠 を作成して、そのなかに
XX番 高専 太郎の形式で出席番号とフルネーム氏名を記入してください。四角枠内には、それ以外の情報を記入しないでください。 - 出席番号と氏名の枠がないメモ、手書き以外で作成したメモ (プリントアウトやコピー) の持ち込みは 不正行為 として扱います。
- ルーズリーフなども、A5サイズに切り取られたものであれば使用可能です。また、出席番号と氏名の枠線、罫線や方眼などは印刷でも問題ありません。
- 片面の 右上部に横10cm、縦1.5cmの四角枠 を作成して、そのなかに
1.1.2 出題内容と範囲について
- 第01回講義 から 第07回講義 (今回) の内容を出題範囲としています。
- 本科目は、学修単位科目であり、その授業時間外学習を前提とした「難易度」で試験問題を作成しています。
- 主として「定着確認」と「SQLドリル」から出題します。ただし、そのままの出題ではなく類題や解答形式を変更した問題となることも想定してください。
- 実施済みの「小テスト」についても、十分に復習しておいてください。特に、どのような問題で、どのような間違いをしたのか、は振り返っておいてください。
- 小テストの解答例は Teams で公開済みです。今回の小テスト❻の解答例も、近日中にアップします。
- 小テストでは部分点となっていた解答も、試験では誤答 (部分点なし) とするので注意してください。
1.1.3 SQLの記述について
- 各種引用符は、実際のSQLで記述するように
'と"を使用してください。- 「
‘と’」「“と”」のような開始引用符と終了引用符の使用は誤答として扱います。
- 「
- 次のような SQLキーワード (予約語) や 型、関数などは全て「大文字」で記述
してください。
INSERT、INTO、VALUES、DELETE、SELECT、FROM、ORDER BY、LIMIT、OFFSET、WHERE、GROUP BY、HAVING、AND、OR、BETWEEN、NOT、AS、CASE、WHEN、THEN、ELSE、END、DISTINCT、ASC、DESCなどSTART TRANSACTION、ROLLBACK、COMMIT、ASC、DESCなどTRUE、FALSEなどLOWER、UPPER、COALESCE、CAST、TO_CHAR、LOCALTIMESTAMP、LOCALTIME、CURRENT_DATEなど
- テーブル名やカラム名は、問題文に示されたもの同じ表記 (大文字・小文字) で記述してください。
1.2 ハンズオン学習の準備
次の手順でSQL演習環境の立ち上げと、教材の更新を取得してください。
- SQL演習環境の動作確認@ 第04回講義
- 教材の更新の取得@ 第04回講義
1.3 今回の講義内容
前回の講義では、データベース設計の「概念設計」と「論理設計」を取り上げ、IE記法 (Crow’s Foot記法) によって「概念ER図」と「論理ER図」を作成する手順と、その具体的な読み取り方、作図法について学びました。この際、論理ER図が適切に設計されていれば 結果的に RDB として自然に「正規化」されたテーブル構造になっていること がほとんどです。
ただし、必ずしも十分に正規化されているとは限らないため、今回の講義では、データの 正規化 (Normalization) という観点から、「RDBのテーブル設計」について詳しく学んでいきます。
また、物理設計の基礎についても学び、実際に RDB にテーブルを作成するための
CREATE 文についても学んでいきます。
なお、正規化は IPAの各種試験 (基本情報試験や応用情報試験) においても、知識や理解が問われるもの (頻出のテーマ) になります。この講義のなかで、しっかりと学んでおくことをお勧めします。
- 基本情報試験などは、受験から合格証書発送までに 約2ヶ月のタイムラグ があります。就活や単位認定に利用する場合は、早めに受験するようにしてください(参考)。
1.3.1 参考: 基本情報技術者試験過去問道場
基本情報技術者試験過去問道場では、当該試験の過去問に挑戦することができます。
2 正規化 (概要)
データベース設計における 正規化 (Normalization) とは、データの冗長性を排除し、効率的かつ一貫性が保たれるようにテーブルを設計 するための概念、および、その具体的な作業を意味します。これは、エンティティの持つ情報を失うことなく、無損失分解の原則(=分解しても元の情報を完全に復元できるという原則)に従い、1事実1箇所 (1 fact in 1 place) となるようにテーブルを分解していく作業になります。そして、その結果として得られるテーブル構造を 正規形 (Normal Form) と呼びます。
正規形には、いくつかの段階 (レベル) があります。非正規形からはじまり、第1正規形、第2正規形、第3正規形、ボイス・コッド正規形 (第3.5正規形)、第4正規形、第5正規形 へと整理していきます。ただし、実務上は 第3正規形 までで十分とされることが多く、本科目でも「第3正規形」までを扱います。なお、第1正規形 (First Normal Form) は「1NF」のように略表記されることがあるので覚えておいてください。同様に 2NF、3NF… と表現されます。
整理すると以下のようになります。以下、これを詳しくみていきます。
- 非正規形: 非スカラー値を含むカラムが存在し、列方向に同種のデータが繰り返されている。
- 第1正規形 (1NF): 各カラムがスカラー値のみを格納し、列方向の繰り返しが排除されている。
- 第2正規形 (2NF): 第1正規形の要件を満たし、複合主キーの一部に対する 部分関数従属 が排除されている。
- 第3正規形 (3NF): 第2正規形の要件を満たし、非キー属性同士の 推移的関数従属 も排除されている。
(プロンプト例)
RDB設計に関する質問です。テーブルが正規形になっていないと何か困ることがあるのですか。簡単な例を示して教えてください。
2.0.1 定着確認
- RDBにおいて、データの冗長性を排除し、効率的かつ一貫性が保たれるようにテーブルを設計するための概念を何というか。次のうち最も適切なものを答えよ。
- 選択肢: 正則化,正規化,正準化,標準化
- 答え: 正規化
- RDB の正規化に関する文脈で「2NF」は何の略語か英語および日本語で答えよ。
- 答え: Second Normal Form (2nd Normal Form)、第2正規形
- RDB
のテーブルは、理論上、非正規形から第5正規形まで段階的に正規化することができる。しかし、一般的な開発現場では通常
( ) までの正規化を行なう。括弧にあてはまる最も適切な語を答えよ。
- 答え: 第3正規形
- RDB
の正規化では、テーブルを分解する際、結合によって元のテーブルを完全に再構成できることが前提となる。この性質は、( )
の原則と呼ばれる。括弧にあてはまる最も適切な語を答えよ。
- 答え: 無損失分解
- ボイス・コッド正規形は、( ) 正規形と ( )
正規形の中間に位置づけられる。括弧にあてはまる最も適切な語を答えよ。
- 答え: 第3、第4
3 非正規形
非スカラー値 (=複合値、つまり、単一ではない値) を含むカラムが存在したり、列方向に同種のデータが繰り返されている構造のテーブルは 非正規形 (=第1正規形(1NF)を満たしていない) とよばれます。
たとえば、次のようなテーブルは、典型的な 非正規形 (Unnormalized Form) となります。テーブル上で、主キーは 下線 で示しています。
▼ 非正規形テーブル1
| character_id | name | job | skill |
|---|---|---|---|
| 1 | Alice | Priest | Heal, Resurrection |
| 2 | Bob | Monk | DragonKick |
| 3 | Charlie | Wizard | Fire, Thunder, Venom |
| 4 | Ellen | Wizard | Thunder |
▼ 非正規形テーブル2
| character_id | name | item1 | qty1 | item2 | qty2 | item3 | qty3 |
|---|---|---|---|---|---|---|---|
| 1 | Alice | Map | 1 | Potion | 5 | ||
| 2 | Bob | Ring | 3 | ||||
| 3 | Charlie | Wand+1 | 1 | Scroll | 4 | Potion | 3 |
| 4 | Ellen |
- qty は quantity (数量) の略表記です。略語としてよく使用されるので覚えておいてください。
非正規形テーブル1 は、skill カラムに 非スカラー値 (複合値)
を含んでいます。このようなテーブル設計にすると、個々の skill
を独立したデータとして扱うことができなくなり、検索や更新における扱いが煩雑
になります。たとえば「スキルとして Heal
を使えるキャラクターを検索したい」といった単純な問い合わせでも、LIKE述語を使用した部分一致検索
(WHERE skill LIKE '%Heal%')
が必要になり、検索や更新に際して、正確性やパフォーマンスに関して考慮すべきことが多くなります。
- 部分一致検索は、インデックスを利用できないため、全件走査 (フルスキャン) が必要であり、大量データを扱うときに性能面で大きな負荷となります。なお、インデックスについては、今後の授業で扱います。
カラムに複合値を入れると検索精度や更新容易性が損なわれる理由
単純な部分一致検索 LIKE '%Heal%' では MegaHeal や
HealBlock のように、名前の一部に Heal
を含むスキルを含むレコードを抽出してしまう可能性があります。
また、スキルの一部だけを更新したい場合 (たとえば Fire, Thunder, Venom に
Quake を追加するような処理)
に、文字列の部分編集や置換操作が必要となります。
また、非正規形テーブル2 では、同じ種類の情報 (アイテムとその数量) が列方向に繰り返されています。これも、第1正規形 (1NF) に違反する典型的なパターンとなります。このようなテーブル設計は「所持可能なアイテムを4種類に増やしたい」といった仕様変更に対して、新しいカラムの追加 (=テーブルスキーマの変更) が必要となるという問題があります。
レコード追加とカラム追加は何が違うのか
RDB において INSERT による「レコードの追加・削除」は DML操作
に属し、比較的軽い処理になります。これに対して「カラムの追加・削除」は ALTER
を用いた DDL操作 は、テーブル構造そのもの (テーブルのスキーマ)
を書き換える処理となるため、負荷も時間も大きくなります。
さらに、スキーマの変更は、既存 SQL の前提を崩すおそれがあるため慎重に実行する必要があります (既存の SQL がカラム名や構造をどのように参照しているかを全て確認する必要があります)。このため、運用開始後にカラム追加が必要になる状況を極力避けられるようにテーブルを設計することが重要になります。
また、非正規形テーブル2
のようなテーブル構造は、大多数のキャラクタがアイテムを1種しか所持しないようなケース
(=ほとんどのカラムが NULL となるようなケース)
では、ストレージを無駄に消費することになります。さらに、SUM() や
COUNT()
を使った集計処理を行う際にも、列を横断的に扱わねばならず、SQLが複雑化し保守性や性能面で問題を抱える設計となります。
(プロンプト例)
RDBに関する質問です。ワイルドカードを使用した部分一致検索は、インデックスを利用できないため、全件走査 (フルスキャン) が必要であると聞きました。そもそもインデックスとは何ですか。
3.0.1 定着確認
- RDB において、配列やオブジェクトのような ( ① ) を含むカラムが存在したり、( ② )
方向に同種のデータが繰り返されている構造のテーブルを「非正規形」という。括弧にあてはまる最も適切な語を答えよ。
- 答え: ① 「非スカラー値」または「複合値」
- 答え: ② 「列」。「横」でも良いが「列」が望ましい。
4 第1正規化
第1正規化、つまり、非正規形を第1正規形に整えるには、複合値や列方向 (横方向) に繰り返されている情報を 行方向 (縦方向) に展開して保持する ようにします。
具体的には、以下のようにします。
▼ 先ほどの「非正規形テーブル1」を「第1正規化」したテーブル
| character_id | name | job | skill |
|---|---|---|---|
| 1 | Alice | Priest | Heal |
| 1 | Alice | Priest | Resurrection |
| 2 | Bob | Monk | DragonKick |
| 3 | Charlie | Wizard | Fire |
| 3 | Charlie | Wizard | Thunder |
| 3 | Charlie | Wizard | Venom |
| 4 | Ellen | Wizard | Thunder |
これにより、第1正規形の要件である「各カラムがスカラー値のみを格納し、列方向の繰り返しが排除されている」を満たした構造となりました。
ただし、このままで character_id という「主キー」だけでは、レコードを一意に識別できない構造となってしまっているため、以下に示すように skill_id カラムを追加して「複合主キー」を構成します。
▼ 「非正規形テーブル1」を「第1正規形」にして「複合主キー」を設定したテーブル
| character_id | name | job | skill_id | skill |
|---|---|---|---|---|
| 1 | Alice | Priest | 1 | Heal |
| 1 | Alice | Priest | 2 | Resurrection |
| 2 | Bob | Monk | 3 | DragonKick |
| 3 | Charlie | Wizard | 4 | Fire |
| 3 | Charlie | Wizard | 5 | Thunder |
| 3 | Charlie | Wizard | 6 | Venom |
| 4 | Ellen | Wizard | 5 | Thunder |
同様に、さきほどの 非正規形テーブル2 についても、第1正規化して、さらに複合主キー (character_id と item_id) を設定すると以下のようになります。
| character_id | name | item_id | item | qty |
|---|---|---|---|---|
| 1 | Alice | 1 | Map | 1 |
| 1 | Alice | 2 | Potion | 5 |
| 2 | Bob | 3 | Ring | 3 |
| 3 | Charlie | 4 | Wand+1 | 1 |
| 3 | Charlie | 5 | Scroll | 4 |
| 3 | Charlie | 2 | Potion | 3 |
| 4 | Ellen |
なお、上記の item_id のように、本来は主キー (複合主キーを含む) に NULL (空欄) を含めること はできません。しかし、ここでは説明の都合上 (=Ellen のレコードを残しておくために)、一時的に許容しています。この問題は、第2正規化のなかで解決していきます。
- 第1正規形 (=第2正規形未満) の問題として、上記の Ellen のように複合主キーが設定できないレコードが存在することや、所有者がいないアイテム情報 (MegaPotionなど) を管理できないことが挙げられます。
なお、第1正規形にしたことで「各キャラクタが所持可能なアイテム種は最大で3つまで」といった制約が無くなってしまいましたが、一般にこれらの制約は
RDB を利用するアプリケーション側
で管理・制御します。たとえば、INSERT の実行前に SELECT COUNT(*)
で現在の所持数を確認するなどの方法で対応します。
4.0.1 定着確認
- RDB の運用において、レコードの追加は DML操作 であるが、カラムの追加は DDL操作
であり、既存テーブルの構造変更をともうなうため、その影響はシステム全体に及ぶ可能性がある。この説明は「適切である」か「適切ではない」か答えよ。
- 答え : 適切である
- 次に示す非正規形のテーブルを第1正規形に変換せよ。変換後のテーブルでは、各レコードが一意に識別できるように複合主キーを設定すること(必要に応じて新たなカラムを追加してよい)。
- 主キーを構成するカラムのヘッダ行には下線をつけること。
- 著者の並び順(author1、author2、author3 の順序情報)も保持すること。必要に応じて新たなカラムを追加してよい。
- 答え : こちら
| book_id | title | author1 | author2 | author3 |
|---|---|---|---|---|
| 1 | New Python | Alice | Ellen | |
| 2 | React 1 | Bob | ||
| 3 | React 2 | Bob | Alice | Charlie |
| 4 | PostgreSQL | Charlie | Ellen |
5 第2正規化
第1正規形の要件を満たし、複合主キーの一部に対する 部分関数従属 が排除 されている構造を 第2正規形 といいます。
まずは、関数従属 という概念について解説し、その後、第2正規化を解説します。なお、「関数従属」という用語は、資格試験などでも頻出するのでしっかりと理解しておいてください。
5.1 関数従属
関数従属 (FD: Functional Dependency) とは…
ある属性集合 \(\mathrm{X}\) の値が決まると、別の属性集合 \(\mathrm{Y}\) の値も一意に定まる
…という「属性間の関係を表す概念」になります。
このような関係があるとき「\(\mathrm{Y}\) は \(\mathrm{X}\) に関数従属する」と言い、記号では「 \(\mathrm{X}\rightarrow\mathrm{Y}\) 」や「 \(\{x_1,\ x_2\}\rightarrow\{y_1,\ y_2,\ y_3\}\) 」のように表現します。ただし \(\mathrm{X}=\{x_1,\ x_2\}\)、\(\mathrm{Y}=\{y_1,\ y_2,\ y_3\}\) とします。
RDB のテーブル設計の文脈では、「あるカラム集合 \(\mathrm{X}\) の値」が決まると「別のカラム集合 \(\mathrm{Y}\) の値」が一意に決まるようなとき「\(\mathrm{Y}\) は \(\mathrm{X}\) に関数従属する 」といいます。単に「\(\mathrm{Y}\) は \(\mathrm{X}\) に従属する」と表現する場合もあります。
- あとで詳しく解説しますが、関数従属には「部分関数従属」や「推移的関数従属」といった概念もあります。
たとえば、次のようなテーブルがあるとします。
| character_id | name | job_id | job | level | guild |
|---|---|---|---|---|---|
| 1 | Alice | J5 | Priest | 42 | Yamato |
| 2 | Bob | J2 | Monk | 33 | hameln |
| 3 | Charlie | J6 | Wizard | 57 | |
| 4 | Ellen | J6 | Wizard | 51 |
このとき、次のようなことが言えます。
- character_id
が決まれば、name、job_id、job、level、guild
は一意に決まるので…
- name, job_id, job, level, guild は、character_id に関数従属する
- \(\{\) character_id \(\} \rightarrow \{\) name, job_id, job, level, guild \(\}\)
- job_id が決まれば、job は一意に決まるので…
- job は、job_id に関数従属する
- \(\{\) job_id \(\} \rightarrow \{\) job \(\}\)
なお、テーブルのなかに格納されている現時点のレコードだけに着目すれば…
character_id, name, job_id, job, guild は、level に関数従属する
…のように判断できそうですが、これは誤りです。
正規化に関して、関数従属とはすべての可能なデータ状態において常に成り立つ制約を指し「現時点のデータでは、たまたまそうなっているだけ (つまり、偶然の一致や偶然依存) 」の関係については、関数従属とは見なしません。
たとえば、上記の例で、レベル51のキャラクタが将来的に複数存在する可能性がある場合、level カラムから、他のカラムへの関数従属は成立しません。関数従属の判断は、ビジネスルールやドメイン知識に基づいた分析 が必要になる点に注意してください。
RDBのテーブルは、「主キー以外のすべてのカラム」が「主キー」に関数従属するように設計することが基本となります。ただし、第2正規形では、さらに 複合主キーの一部に対する 部分関数従属 を排除し、完全関数従属 することが求められます。
(プロンプト例)
RDBにおいて、関数従属であるかは、レコードのサンプルで判断するだけではなく、ドメイン知識に基づいて判断するべきであると説明されました。そもそも「ドメイン知識」とはなんですか。
5.1.1 定着確認
- RDB において、id が決まれば name、age、address
が一意に決まるとき、その関係を適切に表現しているのは「name, age, address は id
に関数従属する」と「id は name, age, address
に関数従属する」のどちらか。「前者」または「後者」で答えよ。
- 答え : 前者
- RDB において、id が決まれば name、age、address
が一意に決まるとき、この関係を関数従属を示す記号で表せ。
- 答え : \(\{\) id \(\} \rightarrow \{\) name, age, address \(\}\)
- 関数従属は「データの偶然の並び」によって判断するのではなく、属性間の意味的な結びつき
(制約)
として常に成り立つ関係として考えるべきである。この説明は「適切である」か「適切ではない」か答えよ。
- 答え : 適切である
5.2 部分関数従属と完全関数従属
RDB において、テーブルの主キーが複数のカラムから構成される場合 (つまり、複合主キーである場合)、その主キーを構成するカラムの一部だけに従属するカラムが存在することがあります。
たとえば、以下のようなテーブルがあるとします。
| character_id | name | item_id | item | qty |
|---|---|---|---|---|
| 1 | Alice | 1 | Map | 1 |
| 1 | Alice | 2 | Potion | 5 |
| 2 | Bob | 3 | Ring | 3 |
| 3 | Charlie | 4 | Wand+1 | 1 |
| 3 | Charlie | 5 | Scroll | 4 |
| 3 | Charlie | 2 | Potion | 3 |
| 4 | Ellen |
このテーブルは character_id と item_id で複合主キーを構成していますが、次のように 複合主キーの「一部だけ」に従属するカラム が存在しています。
- item カラムは、item_id だけ に従属しています
- item_id だけで item が一意に決定し、character_id には依存していません
- name カラムは character_id だけ に従属しています
- character_id だけで name が一意に決定し、item_id には依存していません
このような状態を 部分関数従属 (PFD: Partial Functional Dependency) といいます。それに対して、複合主キーのすべてのカラムをそろえてはじめて値が一意に決定する関係を 完全関数従属 (FFD: Full Functional Dependency) といいます。
たとえば、上記のテーブルで qty カラムは、character_id と item_id の両方がそろわなければ値が一意に決まってきません。このようなとき、qty は character_id と item_id に完全関数従属している といいます。
主キーが1つのカラムで構成される場合 (=複合主キーではない場合)、主キーに「部分」という概念が存在しないため、部分関数従属の関係になるようなカラムは存在しません。ただし、サロゲートキーを設定しているときは、潜在的に部分関数従属が存在している場合があり、第2正規化では、そのようなケースを含めて排除する必要があります。
5.2.1 定着確認
次のテーブルは、book_id と author_id により、複合主キーが設定されている。以下の各問いに答えよ。
| book_id | author_id | title | author | author_order |
|---|---|---|---|---|
| 1 | 1 | New Python | Alice | 1 |
| 1 | 2 | New Python | Ellen | 2 |
| 2 | 3 | The React 1 | Bob | 1 |
| 3 | 3 | The React 2 | Bob | 1 |
| 3 | 1 | The React 2 | Alice | 2 |
| 3 | 4 | The React 2 | Charlie | 3 |
| 4 | 4 | PostgreSQL | Charlie | 1 |
| 4 | 2 | PostgreSQL | Ellen | 2 |
- このテーブルは、第1正規形としての要件を「満たしている」か「満たしていない」かを答えよ。
- 答え: 満たしている
- title
カラムは、この複合主キーに対して「部分関数従属」しているか、「完全関数従属」しているかを答えよ。
- 答え: 部分関数従属
- author
カラムは、この複合主キーに対して「部分関数従属」しているか、「完全関数従属」しているかを答えよ。
- 答え: 部分関数従属
- author_order
カラムは、この複合主キーに対して「部分関数従属」しているか、「完全関数従属」しているかを答えよ。
- 答え: 完全関数従属
- このテーブルは、第2正規形としての要件を「満たしている」か「満たしていない」かを答えよ。
- 答え: 部分関数従属を含むため、満たしていない。
5.3 第2正規形
第2正規化 では、第1正規形の要件を満たしつつ、複合主キーの一部に対する 部分関数従属 を排除するように (=完全関数従属 になるように) テーブルを分解していきます。
たとえば、次のようなテーブル (=部分関数従属を含むテーブル) があるとき…
▼ 第1正規形 (第2正規形未満)
| character_id | name | item_id | item | qty |
|---|---|---|---|---|
| 1 | Alice | 1 | Map | 1 |
| 1 | Alice | 2 | Potion | 5 |
| 2 | Bob | 3 | Ring | 3 |
| 3 | Charlie | 4 | Wand+1 | 1 |
| 3 | Charlie | 5 | Scroll | 4 |
| 3 | Charlie | 2 | Potion | 3 |
| 4 | Ellen |
このテーブルを、第2正規形の要件を満たすように3つのテーブルに分解することができます。一部、カラム名を整理しています。
▼ characters テーブル (第2正規形)
| character_id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
| 4 | Ellen |
▼ items テーブル (第2正規形)
| item_id | name |
|---|---|
| 1 | Map |
| 2 | Potion |
| 3 | Ring |
| 4 | Wand+1 |
| 5 | Scroll |
▼ character_items テーブル (第2正規形・複合主キー・完全関数従属)
| character_id (FK) |
item_id (FK) |
qty |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 2 | 5 |
| 2 | 3 | 3 |
| 3 | 4 | 1 |
| 3 | 5 | 4 |
| 3 | 2 | 3 |
- FK は、外部キー (=他テーブルの主キーを参照するカラム) であることを表しています。
既に気づいたかもしれませんが、この分解操作は、前回講義で学んだ多対多のリレーションの分割 (中間テーブル化)と本質的に同じ考え方です。そのため、論理ER図を適切に設計できていれば、結果として自然に第2正規形となっている場合が少なくありません。

5.3.1 定着確認
- RDB において第2正規形とは、第1正規形の要件を満たしつつ、複合主キーの一部に対する ( )
が排除されている構造を指す。括弧にあてはまる最も適切な語を答えよ。
- 答え : 部分関数従属
- RDB において第2正規形とは、第1正規形の要件を満たしつつ、非キー属性が複合主キー全体に対して
( ) している状態を指す。括弧にあてはまる最も適切な語を答えよ。
- 答え : 完全関数従属
- 次に示す第1正規形のテーブルを、第2正規形の要件を満たす複数のテーブルに分解せよ。分解後の各テーブルには、適切なテーブル名を付け、必要に応じてカラム名も整理すること。また、各テーブルには主キー
(必要に応じてサロゲートキーを含む) を設定すること。
- 主キーを構成するカラムのヘッダ行には下線をつけること。
- 答え: こちら
| book_id | author_id | title | author | author_order |
|---|---|---|---|---|
| 1 | 1 | New Python | Alice | 1 |
| 1 | 2 | New Python | Ellen | 2 |
| 2 | 3 | The React 1 | Bob | 1 |
| 3 | 3 | The React 2 | Bob | 1 |
| 3 | 1 | The React 2 | Alice | 2 |
| 3 | 4 | The React 2 | Charlie | 3 |
| 4 | 4 | PostgreSQL | Charlie | 1 |
| 4 | 2 | PostgreSQL | Ellen | 2 |
- 上記で第2正規形に分解して得られたテーブル群について、それらの構造と関連を示す「論理ER図」を作成せよ。なお、1冊の書籍には必ず1名以上の著者が存在し、一方で著者は書籍を持たない場合があるものとしてオプショナリティを適切に設定すること。
- 答え: 作成例
{kind=link}
6 第3正規化
第3正規化 では、第2正規形の要件を満たしつつ、非キー属性同士の 推移的関数従属 を排除していきます。非キー属性とは 主キーを構成しないカラム、つまり主キー以外のすべてのカラム を指します。
6.1 推移的関数従属
推移的関数従属 (TFD: Transitive Functional Dependency) とは、主キー以外のカラムに関数従属している関係 を表します。砕けた表現をすれば「主キー以外のカラムが「中継点」のようになって、別の非キーを決めてしまう関係」を推移的関数従属といいます。
つまり、\(\{\) 主キー\(\} \rightarrow \{\) 非キーA \(\} \rightarrow \{\) 非キーB \(\}\) という依存の連鎖があるとき「非キーBは、主キーに推移的に従属している」のように表現します。
たとえば、次のようなテーブルを考えます。このテーブルで「主キー」は 下線 で示すように character_id であり、「非キー」は name、job_id、job_name となります。このテーブルは…
- 各カラムがスカラー値のみを格納し、列方向の繰り返しが排除されているので、第1正規形の要件を満たしています。
- 複合主キーを構成していないので部分関数従属は存在せず、第2正規形の要件も満たしています。
| character_id | name | job_id | job_name |
|---|---|---|---|
| 1 | Alice | J5 | Priest |
| 2 | Bob | J2 | Monk |
| 3 | Charlie | J6 | Wizard |
| 4 | Ellen | J6 | Wizard |
このテーブルで注目すべきは、
- 主キーである character_id が決まれば job_id は一意に決まる
- そして、非キーである job_id が決まれば job_name は一意に決まる (=主キーである character_id によって直接的に job_name が決まっている訳ではない)
という構造になります。つまり、\(\{\) character_id \(\} \rightarrow \{\) job_id \(\} \rightarrow \{\) job_name \(\}\) という関係が成立し、「job_name は、主キーに推移的に従属している」といえます。
このような 推移的関数従属 を排除するようにテーブルを分解する操作が 第3正規化 となります。
6.2 第3正規形
次のような推移的関数従属 (=具体的には \(\{\) character_id \(\} \rightarrow \{\) job_id \(\} \rightarrow \{\) job_name \(\}\)) を含むテーブルは…
| character_id | name | job_id | job_name |
|---|---|---|---|
| 1 | Alice | J5 | Priest |
| 2 | Bob | J2 | Monk |
| 3 | Charlie | J6 | Wizard |
| 4 | Ellen | J6 | Wizard |
以下のような第3正規形の2つのテーブル (characters と jobs) に分解することができます。
▼ characters テーブル (第3正規形)
| character_id | name | job_id (FK) |
|---|---|---|
| 1 | Alice | J5 |
| 2 | Bob | J2 |
| 3 | Charlie | J6 |
| 4 | Ellen | J6 |
▼ jobs テーブル (第3正規形)
| job_id | name |
|---|---|
| J1 | Fighter |
| J2 | Monk |
| J3 | Ninja |
| J4 | Samurai |
| J5 | Priest |
| J6 | Wizard |
これらのテーブルについて「論理ER図」を作成すると次のようになります (characters テーブルの job_id カラムに NOT NULL制約 を想定して作成した図になります)。

第3正規形にすることで、いずれのキャラクタも就いていないジョブ情報 (たとえば、Fighter や Ninja、Samurai など) が保持可能な構造になることに注目してください。
- 元々の1つのテーブルでは、そのジョブに就いているキャラクタが存在しないと、Fighter や Ninja などのジョブ情報をシステムとして持てない構造 (=問題のある構造) になっています。
6.2.1 定着確認
- RDB における第3正規形とは、第2正規形を満たしたうえで、すべての非キー属性が ( )
のみに関数従属している状態、すなわち推移的関数従属が存在しない構造を指す。括弧にあてはまる最も適切な語を答えよ。
- 答え : 主キー
- 次に示すテーブルに内在している「推移的関数従属」を、関数従属を示す記号により表せ。
- 答え: \(\{\) book_id \(\} \rightarrow \{\) primary_author \(\} \rightarrow \{\) primary_author_tel \(\}\)
- 答え: \(\{\) book_id \(\} \rightarrow \{\) publisher \(\} \rightarrow \{\) publisher_tel \(\}\)
| book_id | title | primary_author | primary_author_tel | publisher | publisher_tel |
|---|---|---|---|---|---|
| 1 | New Python | Alice | 5501 | Hoge Inc. | 4771 |
| 2 | React 1 | Bob | 3000 | Fuga Inc. | 4649 |
| 3 | React 2 | Bob | 3000 | Fuga Inc. | 4649 |
| 4 | PostgreSQL | Charlie | 5432 | Hoge Inc. | 4771 |
| 5 | Hello COBOL | Ellen | 8080 | Piyo Inc. | 2951 |
| 6 | OpenCV ! | Alice | 5501 | Piyo Inc. | 2951 |
- 上記に示したテーブルを、第3正規形としての要件を満たす複数のテーブルに分解せよ。
- 分解後の各テーブルには、内容に応じた適切な名前を付けて、カラム名も整理すること。
- 各テーブルには主キー (必要に応じてサロゲートキーを含む) を設定し、主キーとなるカラムの見出しには下線を付けて示すこと。
- 外部キーのカラムには、カラムの見出しに
(FK)を付けて示すこと。 - 答え: こちら
- 上記で第3正規形に分解して得られたテーブル群について、それらの構造と関連を示す「論理ER図」を作成せよ。なお、リレーションには、books
エンティティ (テーブル) を基準とした関連名 (動詞句) を記載すること。
- 答え: 作成例
{kind=link}
6.3 高次正規化
ここまで、第1正規形、第2正規形、第3正規形 と順に解説してきました。先にも触れたように、この先には ボイス・コッド正規形 (第3.5正規形)、第4正規形、第5正規形 と続いていきますが、実務でも資格試験でも、第3正規形まで満たせていれば十分なケースがほとんどであり、本講義でもそこまでの解説に留めています。
正規化について、より深く学びたい学生は、📖 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」で丁寧に解説されているので、読んでみてください。
- 第3章「論理設計と正規化」
- 3-7 ボイス・コッド正規形 (pp.124-130)
- 3-8 第4正規形 (pp.131-135)
- 3-9 第5正規形 (pp.136-144)
(プロンプト例)
RDB の設計に関する質問です。実務においては第3正規形までの正規化で十分なケースが多いと聞きました。なぜ、第4正規形、第5正規形まで正規化をしないのですか。どのような背景や理由があるのですか。
6.4 論理設計のまとめ
ここまでに解説してきたものは「形式的に正しい構造をつくる」という側面での論理設計でしたが、現実の開発では「どのように アプリ から DB を使うのか」という側面からの設計テクニックや、逆に避けるべきアンチパターンも数多く存在します。これらはビジネスルールやドメイン知識に強く依存するため、授業では踏み込みませんが、Zenn、Qiita、書籍、動画などのナレッジを追いかけておくことで、より現場に近いデータベース設計の感覚を身につけることができるようになります。
以下の動画は、初心者がやらかしがちなデータベース設計のアンチパターンについてクイズ形式で解説しているものになります。ここまでに学んだ知識で十分に理解できる内容となっています。短時間で視聴できる動画なので、ぜひ、視聴してみてください。
- 【初心者向け】クソデータベース設計をしないためのテクニック4選@YouTube (7:51)
- 【初心者向け】クソデータベース設計をしないためのテクニック5選@YouTube (6:56)
また、現場で遭遇する「論理設計のアンチパターン」については📖 教科書「達人に学ぶDB設計 徹底指南書 (第2版)」でも解説されているので、興味のある学生は読んでみてください。上記の動画と同様に、ここまでの授業内容が理解できていれば、概ね内容を理解することができると思います。
- 第7章「論理設計のアンチパターン」pp.225-262
- 第8章「論理設計のグレーノウハウ」pp.263-302
7 物理設計 (基礎)
物理設計 (Physical Design) では、PostgreSQL や MySQL などの実際の RDBMS
で動作させることを前提に、具体的なテーブルやインデックスの設計を行います。ここには、データ型の選択、外部キーやCHECK制約などの設定、テーブル定義
(=CREATE TABLE などのDDL
の記述)、検索性能を意識したインデックス設計といった作業が含まれます。
また、物理設計には、ストレージ、メモリ、CPU などハードウェア特性を踏まえたストレージ構成、冗長化の仕組み (たとえば RAID構成など)、バックアップやレプリケーション、負荷分散など、ハードウェアおよび運用面を含めた設計も含まれます。
なお、本講義ではまず、これらのうち「テーブル設計」「制約設定」「インデックス設計」など、RDBMS 上で完結する基礎的な物理設計を中心に扱います。RDBMS としては PostgreSQL 17 を想定します。
(プロンプト例)
データベースにおける「レプリケーション」とはどのようなものですか。「バックアップ」とは何が違いますか。
7.0.1 定着確認
- データベースの「概念設計」「論理設計」「物理設計」のうち、ハードウェア構成や
RAID、レプリケーションなどを扱う段階はどれか。
- 答え:物理設計
- データベースの物理設計には、障害復旧の仕組みやパフォーマンスチューニングのような運用面の検討は含まれない。この説明は「適切である」か「適切ではない」か答えよ。
- 答え:適切ではない
- データベース (RDB) の物理設計に含まれる作業として適切なものを すべて選択して
記号で答えよ。
- ① テーブルごとのデータ型・制約の設計
- ② ユースケース図の作成
- ③ 正規化による関係の整理
- ④ エンティティやリレーションの抽出
- ⑤
CREATE TABLEなどの DDL 記述 - ⑥ CPU・メモリ搭載量を前提にした性能設計
- 答え:①、⑤、⑥
7.1 テーブルの定義
RDBMS に「テーブル」を作成するためには、SQL の CREATE TABLE
文を使用します。最小構成の CREATE TABLE には ❶テーブル名
(慣例として複数形の名詞もしくは集合名詞)、❷カラム名、❸データ型、❹主キーの指定といった基本要素を記述します。
たとえば、次のような「論理ER図」で示されたエンティティは…

次のような SQL でテーブルを定義/作成できます。
-- 既に存在するなら削除
DROP TABLE IF EXISTS p_characters;
-- テーブルの作成
CREATE TABLE p_characters (
character_id INTEGER PRIMARY KEY, -- 整数型、PK
name VARCHAR(16) NOT NULL, -- 可変長文字列(最大16文字)
buff DECIMAL(3, 2) NOT NULL, -- 固定小数点数型 (-9.99〜9.99)
is_online BOOLEAN NOT NULL, -- 真偽値
notes TEXT, -- 可変長文字列(実質無制限)
created_on DATE NOT NULL, -- 日付型
last_login_at TIMESTAMP -- 日時型(タイムゾーンなし)
);
-- レコードの挿入
INSERT INTO
p_characters (character_id, name, buff, is_online, notes, created_on, last_login_at)
VALUES
(
6,
'Alice',
0.00,
TRUE,
NULL,
DATE '2021-06-14',
TIMESTAMP '2025-09-18 14:22:00'
),
(
8,
'Bob',
9.99,
FALSE,
'Admin note: Detected abnormal behavior; monitoring enabled.',
DATE '2022-03-22',
TIMESTAMP '2025-08-03 09:11:00'
);
-- レコードの確認
SELECT
*
FROM
p_characters;SQL演習用のプロジェクトに sql/07/tmp.sql などの適当なファイルを作成して、この
SQL を貼り付けて、実際に実行してみてください。
次のような実行結果が得られると思います (以下では、notes カラムの表示を省略しています)。
DROP TABLE
CREATE TABLE
INSERT 0 2
character_id | name | buff | is_online | notes | created_on | last_login_at
--------------+-------+------+-----------+-------------+------------+---------------------
6 | Alice | 0.00 | t | | 2021-06-14 | 2025-09-18 14:22:00
8 | Bob | 9.99 | f | Admin no... | 2022-03-22 | 2025-08-03 09:11:00第02行目 は「既に p_characters
テーブルが存在していれば削除する」という意味の文になります。存在しないテーブルを削除
(DROP) しようとするとエラーになるため、IF EXISTS
キーワードを追加しています。
第05行目 から 第13行目 の
CREATE TABLE p_characters (...)
がテーブルを新規に作成するための文になります。基本的に カラム名 (Column Name) 👉
データ型 (Data Type) 👉 制約 (Constraint) という順で記述します。
- 「データ型」と「制約」の詳細については、あとのセクションで詳しく説明します。
第16行目 から 第36行目
では、作成したテーブルにレコードを挿入しています。第25行目では、DATE '2021-06-14'
のように 型付きリテラル によって値を設定していますが、単に
'2021-06-14' としても (暗黙に変換されるので) 問題ありません。
INSERTについては第04回講義で学習済みです。
7.1.1 演習
- 上記のSQLの 第25・26行目、第34・35行目 において「型付きリテラル」を使用せずとも、問題なくレコードが挿入できること確認してください。
- 上記のSQLの 第10行目 を
notes TEXT NOT NULL,に書き換えて実行すると、どのようになるか確認してください。確認後は、元に戻しておいてください。 - 上記のSQLの 第10行目 を
notes VARCHAR(16),に書き換えて実行すると、どのようになるか確認してください。確認後は、元に戻しておいてください。 - 上記のSQLの 第12行目 を
last_login_at TIMESTAMP,(=末尾にカンマを付ける) に書き換えて実行すると、どのようになるか確認してください。確認後は、元に戻しておいてください。 - 上記のSQLの 第31行目 を
9.999,に書き換えて実行すると、どのようになるか確認してください。確認後は、元に戻しておいてください。 - 上記のSQLの 第22行目 を
0.000,に書き換えて実行すると、どのようになるか確認してください。確認後は、元に戻しておいてください。 - 上記のSQLの 第23行目 を
1,に書き換えて実行すると、どのようになるか確認してください。確認後は、元に戻しておいてください。 - 上記のSQLの 第23行目 を
'TRUE',に書き換えて実行すると、どのようになるか確認してください。確認後は、元に戻しておいてください。
7.1.2 定着確認
- PostgreSQL において、
DATE '2025-01-31'やTIMESTAMP '2025-08-03 09:11:00'のようにリテラル値に型を直接指定して記述する書き方を何というか答えよ。- 答え: 型付きリテラル (Typed Literal)
- PostgreSQL において、次の指示を満たす SQL 文を 1 行で記述せよ。
- 答え:
DROP TABLE IF EXISTS users
- 答え:
テーブル users が存在する場合にのみ、そのテーブルを削除し、存在しない場合はエラーにならないようにすること。
7.2 データ型
PostgreSQL で利用可能な 代表的なデータ型 としては、次のようなものがあります。
INTEGER: -2,147,483,648 から +2,147,483,647 までの範囲の整数値を格納可能な型です。PostgreSQL ではINTという省略形の表記も可能です。- より小さな範囲の整数を格納可能な
SMALLINT、より大きな範囲の整数を格納可能なBIGINTもあります。
- より小さな範囲の整数を格納可能な
TEXT: (最大 1GB まで格納可能な) 可変長文字列型です。空文字 (長さ0の文字列) とNULLは「等価ではない」ので注意してください。VARCHAR(n): 最大n文字までを格納可能な可変長文字列型です。TEXT型と同様、空文字とNULLは異なる値として扱われます。- 書き込みの際に文字数の確認が行われるため、
VARCHARのほうがTEXTよりごくわずかに処理コストが高くなります。ただし、この差は通常のアプリでは誤差レベルとなります。
- 書き込みの際に文字数の確認が行われるため、
DECIMAL(n, m): 正確な精度を保持する数値型 (固定小数点数型) で、全体の桁数をn、そのうち小数点以下の桁数をmで指定します。- たとえば、
DECIMAL(6, 2)は -9,999.99 から +9,999.99 までの範囲を扱い、桁落ちや丸め誤差なしで、小数点以下2桁を保持できます。金額などの精度が重要な値に向いています。 - PostgreSQL では、
NUMERIC(n, m)とDECIMAL(n, m)は同義語で内部実装も同じとなります。 - 単に
DECIMALだけを指定した場合、桁数や小数点以下の桁数が固定されない任意精度型として扱われます。ただし、小数点以下を含む桁数に制限がないため便利ですが、演算処理が重くなりやすく、パフォーマンス面で不利になることがあります。
- たとえば、
BOOLEAN: 真偽値を扱うブール型です。TRUEもしくはFALSEを保持します。DATE: 日付型です。年、月、日の情報だけを保持し、時刻やタイムゾーンの情報は含みません。TIMESTAMP: 日付と時刻を タイムゾーンなし で扱う型になります。時刻は、100万分の1秒 (マイクロ秒) までの精度で保持されます。- タイムゾーン情報を持たせる場合は
TIMESTAMPTZを使用します。
- タイムゾーン情報を持たせる場合は
PostgreSQLで利用可能なデータ型
PostgreSQL は、リレーショナルモデルではあるものの、オブジェクト指向データベース的な機能も有しており、「可変長配列型」や「JSON型」といった構造化データをそのまま扱うカラムを定義することができます。これらの値は文字列としてシリアライズされて保存されるわけではなく、検索や更新を高速化するための構造化された形式で内部的に保持されています。
ただし、本科目ではこれらの機能は扱わず、純粋な RDB としての「基本的なデータ型のみ」を対象とします。
(プロンプト例)
PostgreSQL に関する質問です。データ型の VARCHAR(n) と TEXT は、どのように使い分けたら良いかを実務的な観点から語ってください。
PostgreSQL に関する質問です。データ型として DECIMAL(n, m) ではなく、単に DECIMAL を指定すると、桁数や小数点以下の桁数が固定されない任意精度型になると聞きました。この任意精度型とは、どのようなものか、浮動小数点数型と比較しながら分かりやすく丁寧に解説してください。
7.2.1 定着確認
- PostgreSQL において、データ型
NUMERIC(8, 2)とDECIMAL(8, 2)は、内部実装も含めて同等である。この説明は「適切である」か「適切ではない」か答えよ。- 答え: 適切である
- PostgreSQL において
DECIMAL(5, 3)が扱える数値範囲を答えよ。- 答え: -99.999 から 99.999
- PostgreSQL において
VARCHAR(16)は、日本語などのマルチバイト文字を使うと内部的なバイト数の関係で16文字を保存できないケースがある。この説明は「適切である」か「適切ではない」か答えよ。- 答え: 適切ではない
- PostgreSQL で、タイムゾーン情報ありの日時を扱うために最も適切なデータ型を答えよ。
- 答え: TIMESTAMPTZ。TIMESTAMP WITH TIME ZONE でも可。
7.3 非NULL制約 (NOT NULL制約)
レコード内の特定のカラムに対して 「値が入っていない状態」
を許容したくない場合は、CREATE TABLE
のなかで「非NULL制約」を指定します。たとえば
is_online BOOLEAN NOT NULL のように記述すると、is_online カラムには
NULL が格納できなくなります。逆に言えば、NOT NULL
を明示しなければ、そのカラムには NULL が格納できることになります。
- 「非NULL制約」は「NOT NULL制約」とも呼ばれます。
character_id INTEGER PRIMARY KEYのように、主キーに指定されたカラムには、自動的に「非NULL制約」と「UNIQUE制約」が適用されます。
7.3.1 定着確認
- 以下のように定義される users テーブルにおいて、name
カラムに「非NULL制約」を追加したい。第03行目をどのように書き換えればよいか答えよ。
- 答え:
name VARCHAR(16) NOT NULL
- 答え:
7.4 PRIMARY KEY指定
CREATE TABLE において、主キーは PRIMARY KEY
キーワードを使用して指定します。たとえば、次のようにすることで character_id
を主キーに指定することができます。このような指定方法を「カラムレベルの主キー指定」といいます。
また、次のようにテーブル定義の末尾に主キーの指定を記述することもできます。このような形式を「テーブルレベルの主キー指定」といいます。
CREATE TABLE characters (
character_id INTEGER,
name VARCHAR(16) NOT NULL,
PRIMARY KEY (character_id)
);複合主キーは、テーブルレベルの主キー指定を用いて次のように記述します。
CREATE TABLE character_items (
character_id INTEGER,
item_id INTEGER,
quantity INTEGER NOT NULL,
PRIMARY KEY (character_id, item_id)
);複合主キーに含まれる character_id と item_id には、それぞれ自動的に「非NULL制約」が適用されます。また、character_id と item_id の組み合わせに対して「UNIQUE制約」が自動適用されます。
7.4.1 定着確認
- 次の
CREATE TABLE文において character_id と guild_id を複合主キーとして設定したい。第05行目に記述すべき主キー指定を答えよ。- 答え:
PRIMARY KEY (character_id, guild_id)
- 答え:
- 次のように定義されるテーブルがあり、
INSERT INTO character_items VALUES (1, 1, 3);により、すでに 1 件のレコードが挿入されているものとする。このとき、次のINSERT文のうち、エラーとなるものをすべて答えよ。- ➀
INSERT INTO character_items VALUES (2, 5, 3); - ➁
INSERT INTO character_items VALUES (1, 2, 5); - ③
INSERT INTO character_items VALUES (1, 1, 4); - ④
INSERT INTO character_items VALUES (1,-1, 0); - ⑤
INSERT INTO character_items VALUES (NULL, 2, 1); - ➅
INSERT INTO character_items VALUES (2, NULL, 1); - 答え: ③ (=UNIQUE制約に違反)、⑤・⑥ (=NOT NULL制約に違反)、
- ➀
CREATE TABLE character_items (
character_id INTEGER,
item_id INTEGER,
quantity INTEGER NOT NULL,
PRIMARY KEY (character_id, item_id)
);7.4.2 SQLドリル💻
ex-01_1.sql👉 以下に示す [期待する実行結果] を得るように p_users テーブルの作成、レコードの挿入、集計処理をせよ。
-- トランザクションの開始
START TRANSACTION;
-- p_users テーブルの作成 (ここを記述)
-- p_users テーブルにレコードを挿入 (ここを記述)
-- テーブルの確認
SELECT
*
FROM
p_users;
-- p_users テーブルを集計 (ここを記述)
-- ロールバックによる処理の取り消し
ROLLBACK;[期待する実行結果]
START TRANSACTION
CREATE TABLE
INSERT 0 5
user_id | name | is_admin | height_cm | birthday
---------+---------+----------+-----------+------------
1 | Alice | t | 162.3 | 2003-10-20
2 | Bob | f | 181.9 | 2002-05-05
3 | Charlie | f | |
4 | Ellen | t | 172.7 |
5 | Eve | f | | 2024-06-30
(5 行)
user_count | height_avg | admin_count
------------+------------+-------------
5 | 172.30 | 2
(1 行)- user_id は、整数型で主キーとしてください。
- name は、文字列型として非NULL制約をつけてください。
- is_admin は、ブール型としてください。非NULL制約をつけてください。
- height_cm は、適切に桁数を設定した固定小数点型としてください。NULLを許容してください。
- birthday は、日付型としてください。NULLを許容してください。
- admin_count を集計する方法 (=CASE と SUM
を組み合わせた典型的な条件付き集計) は、授業ではまだ触れていないので解答例
from-teacher/07/drill/ex-01_1.sqlを参考にしてください。
8 授業時間外学習の指示 (宿題)
🚨本科目は「学修単位科目」であり、1回の講義あたり「4時間相当」の授業時間外学習が求められる科目です🏃
- 第01回講義から第07回講義までの内容について総復習して、後期中間試験に挑んでください。
- 試験明けの 第09回講義 (12月11日) では、小テストを実施しません。
- 後期中間試験を 第08回 としてカウントしています。
- 次回講義では、引き続きテーブルの制約 (特に外部キー制約) について学んでいきます。
- この講義資料を再読・熟読し「不明な用語」や「理解が不十分な用語」があればインターネットや、ChatGPTなどの生成AIを利用して解決してください。また、興味関心を持ったトピックについて、ウェブ、生成AI、YouTube動画などを利用して知識を広げ、理解を深めてください。
- 特に (プロンプト例) を示しているものについては、実際に生成AIにプロンプトを投げ、さらに対話を重ねることで、知識の幅を広げるだけでなく、理解をより深く確かなものにしてください。
9 定着確認の解答例
9.0.1 解答例-1nf-01
| book_id | author_id | title | author | author_order |
|---|---|---|---|---|
| 1 | 1 | New Python | Alice | 1 |
| 1 | 2 | New Python | Ellen | 2 |
| 2 | 3 | The React 1 | Bob | 1 |
| 3 | 3 | The React 2 | Bob | 1 |
| 3 | 1 | The React 2 | Alice | 2 |
| 3 | 4 | The React 2 | Charlie | 3 |
| 4 | 4 | PostgreSQL | Charlie | 1 |
| 4 | 2 | PostgreSQL | Ellen | 2 |
- author_id を導入せずに「book_id + author_order」を複合主キーとしても、第1正規形としては正しいです。ただし、後続の第2正規形、第3正規形を見据えると、著者情報を独立したテーブル (エンティティ) として分解できるように、author_id を設けるような構造にした方が望ましいです。
9.0.2 解答例-2nf-01
あくまで設計の「一例」です。
▼ books テーブル
| book_id | title |
|---|---|
| 1 | New Python |
| 2 | The React 1 |
| 3 | The React 2 |
| 4 | PostgreSQL |
▼ authors テーブル
| author_id | name |
|---|---|
| 1 | Alice |
| 2 | Ellen |
| 3 | Bob |
| 4 | Charlie |
▼ book_authors テーブル
| book_id | author_id | author_order |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 2 | 3 | 1 |
| 3 | 3 | 1 |
| 3 | 1 | 2 |
| 3 | 4 | 3 |
| 4 | 4 | 1 |
| 4 | 2 | 2 |
9.0.3 解答例-3nf-01
あくまで設計の「一例」です。
▼ authors テーブル
| author_id | name | tel |
|---|---|---|
| 1 | Alice | 5501 |
| 2 | Bob | 3000 |
| 3 | Charlie | 5432 |
| 4 | Ellen | 8080 |
▼ publishers テーブル
| publisher_id | name | tel |
|---|---|---|
| 1 | Hoge Inc. | 4771 |
| 2 | Fuga Inc. | 4649 |
| 3 | Piyo Inc. | 2951 |
▼ books テーブル
| book_id | title | primary_author_id (FK) |
publisher_id (FK) |
|---|---|---|---|
| 1 | New Python | 1 | 1 |
| 2 | React 1 | 2 | 2 |
| 3 | React 2 | 2 | 2 |
| 4 | PostgreSQL | 3 | 1 |
| 5 | Hello COBOL | 4 | 3 |
| 6 | OpenCV ! | 1 | 3 |
- 外部キーのカラム名は、参照先テーブルの主キー名と 必ずしも同一である必要はありません。たとえば、この例では、authors テーブルでは主キーを author_id とし、books テーブルではそれを指す外部キーとして primary_author_id を用いています。
(プロンプト例)
RDB のテーブル設計に関する相談です。
usersというテーブルの主キーとなるカラムの名前をidにすべきかuser_idにすべきか悩んでいます。それぞれで一長一短があると思うのですが、そのあたりを教えてください。