1 準備・案内
GoogleColab. にログイン、もしくは、ローカル環境の Jupyter を起動し「
PG1-第13回講義.ipynb」という名前でノートブックを作成しておいてください。前々回講義で課題05 (自由課題)が出題されています。期限はまだ先ですが、計画的に取り組んでください。
- 期限: 2025年8月6日 (水) 23:00
1.1 次回 (夏休み明け) 、小テストを実施します。
- 今回の講義資料の範囲からの出題です。特にリストの浅いコピーと深いコピーについて理解しておいてください。
- 「参照」の概念を理解しておいてください。
- 多次元リストを
=で代入した場合、リストのcopy()メソッドでコピーした場合、copy.deepcopy()関数でコピーした場合の挙動の違いを理解し、id()関数や要素の変更による影響を通して確認できるようになっておいてください。
2 課題06
- 今回の講義が「夏休み前の最終授業」となります。そして、次回の授業は
9月18日 (木) なので、約2カ月のブランク(空白期間)
が生じることになります。
- 語学やスポーツと同様に、プログラミング初心者が
2カ月のブランクをつくると、未学習に近い状態 (本年度の4月の状態)
まで戻ってしまいます。それは皆さんも教員も望まないはずです。そのため、夏休み中も、言語や内容・方法・スタイルは問わないので、最低でも3時間/週
は何かしらプログラミングに取り組んでください。
- クラブ活動や総合課題学習に関連するプログラミングの取り組みでも全然OKです
- …とはいえ、人間、何も縛りがないとやらずじまいになってしまいます。わずかでも、強制力を働かせるために、課題06 として、週単位で「プログラミングの学びの報告」をしてもらい、それを課題点として成績反映させる方法をとります。
- 語学やスポーツと同様に、プログラミング初心者が
2カ月のブランクをつくると、未学習に近い状態 (本年度の4月の状態)
まで戻ってしまいます。それは皆さんも教員も望まないはずです。そのため、夏休み中も、言語や内容・方法・スタイルは問わないので、最低でも3時間/週
は何かしらプログラミングに取り組んでください。
- 08/08(金) ~ 08/14(木) の取組み \(\to\) 課題06-学習報告①入力期間 08/15 ~ 08/21
- 08/15(金) ~ 08/21(木) の取組み \(\to\) 課題06-学習報告②入力期間 08/22 ~ 08/28
- 08/22(金) ~ 08/28(木) の取組み \(\to\) 課題06-学習報告③入力期間 08/29 ~ 09/04
- 08/29(金) ~ 09/04(木) の取組み \(\to\) 課題06-学習報告④入力期間 09/05 ~ 09/12
- 09/05(金) ~ 09/11(木) の取組み \(\to\) 課題06-学習報告⑤入力期間 09/13 ~ 09/18
※ 入力期間中にフォームが開けない場合は、Teamsのチャットで和田に連絡をお願いします。
※ フォームの回答後は、以下のように「回答を保存して編集する」を押下して、回答を保存しておくことを強く推奨します。保存しておくことで、未提出とされた場合でも、提出済みであることを証明する手段となります。
2.1 補足
入力期間になると、上記のリンクから Microsoftフォーム にアクセスできます。
202X年XX月XX日~XX月XX日のプログラミング学習の取り組みの報告フォームです。最低ラインとして毎週180分以上、理想としては毎週840分以上(1日2時間)を推奨しています。

フォームには「出席番号」と「氏名」につづけて次の項目があるので、記入して送信してください。期限を過ぎると、そのフォームにはアクセスできません。入力期間中は何度でも編集が可能です。
- この期間の総取り組み時間を記入してください。単位は「分(min)」で記入してください。
- この期間の取組み内容を具体的かつ客観的に報告してください。最低180文字以上を記入していないと加点対象になりません。
例えば、以下のような感じで、具体的に記入してください。
Progateのレッスン「Python I」で「変数を使ってみよう」「真偽値と条件分岐」「お買い物代金を計算しよう」にに取り組んだ。「型」についてYouTube動画とウェブ記事で学習した。総合課題学習のプロジェクト「XXXX」のYYY機能の実装のために、YYについて調べて、実装を進めた(TypeScript)。YYY機能の設実装に関して進捗率が20%から40%になった。YouTubeでスクレイピング、HTTP関連の動画を5本視聴した。
プログラム1の講義資料の第01回~第03回までの内容(演習問題と課題を含む)に再度、取り組んだ。不明点については ChatGPT を使って深堀りした。特に、演習については、理解を定着させるために時間を空けて2回以上、繰り返し取り組んだ。YouTube でプログラミングの苦手を克服する系の動画を数本視聴して、ポイントをスマホメモに残した。「プログラミングが苦手な人の特徴!現役エンジニアが解説」「【ひろゆき】※プログラマーになれない人の特徴※ あなた向いてないね。残念ですが…」「子どもがプログラミング嫌いになる理由3選」など。
GitHub Education について調べて申請した。VSCodeに「GitHub Copilot」の拡張機能をインストールしてコードの補完機能を使ってみた(合計3時間)。「苦しんで覚えるC言語」というウェブサイトでC言語の勉強をはじめた。3章の「画面への表示」まで進めた(2時間ぐらい)。VSCodeでC言語の環境環境の構築したが思った以上に苦戦して、とりあえず paiza.io で開発することにした。
「課題06」として何に取り組めばよいか分からないときは…
本科目の講義資料を第01回から、「演習問題」や「課題」を含め、再度、取り組んでください。資料を読むだけではなく、必ず手をも動かしてください。また、2周目なので、生成AI機能をオフにして取り組むこともよいと思います。
以前にも、伝えていますが 「調べる」「試す」「考える」 をバランスよく行なうことがポイントです。
3 プログラミングの上達のためには…
プログラミングは「語学」や「スポーツ」「楽器演奏」と同じく、方法や理論のレクチャーを受ける だけ、解説を読む だけでは、いつまでもモノにはなりません (=頭のなかに描いた「やりたいこと」を、プログラムとして自由に記述できるレベルにはなりません) 。語学、スポーツ、楽器演奏のように、実際に繰返し手を動かして試行錯誤しながら、その感覚をつかむ必要があります。
例えば、バスケにおいて「コーチからレイアップシュートの指導を受けて、その後、レイアップシュートを成功させることができた」という事実から、俺はレイアップシュートを完全に習得した (これ以上は練習する必要はないし、試合でもレイアップシュートで得点をとれる)、とか思ってしまう人がいたら、かなり問題ですよね ?
これは、プログラミングでも同じで「Pythonの辞書型についての講義資料を読んで理解し、そのあとの演習課題もクリアした」からといって、それが身に付いたことにはなりません。実際に、繰返して使うことで、その結果として辞書型が身に付きます。この事実をしっかりと意識しておくようにしてください。
わからないまま、進んでいませんか🤔
「前回の講義資料、やり残しがあるけどまあいいか」 「AIが書いてくれたコードで動いたからヨシ!(コードの意味は理解してないけど…)」 ――その「まあいいか」が、未来の自分を追い詰めます。
プログラミングは、地面にブロックを積み上げていくようなものです。 昨日積んだブロックがしっかりしていなければ、今日のブロックは崩れます。 一段でもスカスカだと、その上には何も積み上げられません。
しかも困ったことに 新しい内容ほど「前に学んだこと」を当然のように使ってきます。 その「なんとなく」は、後から必ずツケとなって返ってきます。
気づいたときには「何をしているのか、まったくわからない」状態。 そこから一人で取り返すのは、正直、かなりしんどいです。
だから今、わからないまま放置しないでください。 この瞬間が、取り返しのつく最後のチャンスかもしれません。
4 リストに格納な可能な変数の型
C言語における「配列 (Array) 」では、以下のように「配列の要素を すべて同じ型で統一 する必要」がありました。
一方で、Pythonの「リスト (List)」では、要素として 異なる型を混在させること が可能です。
実際に、以下に示すPythonプログラムのリスト arr
には「整数型」「文字列型」「真偽型
(ブール型)」「リスト型」「辞書型」を混在させていますが、問題なく動作します。実際に動作と結果を確認してください
(C言語ではこのようなことはできません)。
特に、ここではリスト arr の内部要素としてリスト
[66,77,88] を持つことができる点に着目してください
(このことがPythonで 2次元リスト
を実現する仕組みになります) 。
なお、第04行目 の enumerate
については 第12回講義
で既に学習済みです。同様に 第05行目 の
type についても 第12回講義
で既に学習済みです。
%reset -f
arr = [ 52, 'ABC', True, [66,77,88], {'秀':5, '優':4, '良':3, '可':3} ]
for i,a in enumerate(arr):
print(f'arr[{i}] の内容は {str(type(a)):<14} 型の {a} です。')実行結果
arr[0] の内容は <class 'int'> 型の 52 です。
arr[1] の内容は <class 'str'> 型の ABC です。
arr[2] の内容は <class 'bool'> 型の True です。
arr[3] の内容は <class 'list'> 型の [66, 77, 88] です。
arr[4] の内容は <class 'dict'> 型の {'秀': 5, '優': 4, '良': 3, '可': 3} です。ここで、arr[3] に格納されている
[66,77,88] の 77
という数値を取得するためには arr[3][1]
のように記述します。また、arr[4] の辞書型が持つ
3 という数値を取得するためには arr[4]['良']
のように記述します。
arr[3][1]やarr[4]['良']という記述によって、実際に77と3が取得できることを確認してください (printで実際に値を出力してみてください)。- ヒント:
print(f'arr[3][1] の内容は { } です。')の{と}に適切な変数を記述する。 - ヒント:
print(f'arr[4]["良"] の内容は { } です。')の{と}に適切な変数を記述する。- 第12回講義 で学んだように f文字列内で辞書型を参照する場合は、シングルクォートとダブルクォートを使い分けてください。
- ヒント:
4.1 演習1 ( 目標時間: 8分)
期待する出力が得られるように、次のプログラムを追記してください。なお、第03行目
と 第04行目 の assert は 第11回講義
で既に学習済みです。
%reset -f
arr = [ [55,66,77,88], {'秀':5, '優':4, '良':3, '可':2} ]
assert type(arr[0]) is list
assert type(arr[1]) is dict
# ここから先にコードを追記する期待する出力
arr[0][0] の内容は 55 です。
arr[0][1] の内容は 66 です。
arr[0][2] の内容は 77 です。
arr[0][3] の内容は 88 です。
arr[1]['秀'] の内容は 5 です。
arr[1]['優'] の内容は 4 です。
arr[1]['良'] の内容は 3 です。
arr[1]['可'] の内容は 2 です。なお、ここでは次のようなプログラムを期待しているわけではありません。arr
と for の組み合わせで対応する方法
(いずれも既に学習済み) を考えてください。ヒント1ヒント2
%reset -f
arr = [ [55,66,77,88], {'秀':5, '優':4, '良':3, '可':2} ]
assert type(arr[0]) == list
assert type(arr[1]) == dict
msg='''\
arr[0][0] の内容は 55 です。
arr[0][1] の内容は 66 です。
arr[0][2] の内容は 77 です。
arr[0][3] の内容は 88 です。
arr[1]['秀'] の内容は 5 です。
arr[1]['優'] の内容は 4 です。
arr[1]['良'] の内容は 3 です。
arr[1]['可'] の内容は 2 です。
'''
print(msg)※ 今回の演習の実装例 (解答例) は こちら を参照してください。
5 二次元リスト
C言語 (Arudino言語) では次のようなコードで「3行4列」の 2次元配列 を扱うことができました。
#include <stdio.h>
int main(void){
int i,j;
int mat[3][4] = { { 10, 20, 30, 40},
{ 50, 60, 70, 80},
{ 90,100,110,120} };
for(i=0;i<3;i++){
for(j=0;j<4;j++){
printf("mat[%d][%d]=%d\n",i,j,mat[i][j]);
}
}
}この「C言語プログラム」の実行結果は次のようになります。
mat[0][0]=10
mat[0][1]=20
mat[0][2]=30
mat[0][3]=40
mat[1][0]=50
mat[1][1]=60
mat[1][2]=70
mat[1][3]=80
mat[2][0]=90
mat[2][1]=100
mat[2][2]=110
mat[2][3]=120これと同等の「Pythonプログラム」は次のように記述することができます。なお、(1次元の)リストの「初期化」については 第08回講義 で既に学習済みです。
%reset -f
# mat: Matrix(行列) 2次元リストの初期化
mat = [[10, 20, 30, 40],
[50, 60, 70, 80],
[90,100,110,120]]
# row: Row(行)
for i,row in enumerate(mat):
for j, e in enumerate(row) :
print(f'mat[{i}][{j}]={e}')上記のプログラムが十分に理解できない場合、まずは次のように
プログラムの途中に print
文を挿入するなど、自分で手を動かし、動作を確認・理解するように努めてください。
%reset -f
# mat: Matrix(行列)
mat = [[10, 20, 30, 40],
[50, 60, 70, 80],
[90,100,110,120]]
# row: Row(行)
for i,row in enumerate(mat):
print(f'mat[{i}]={row}') # 追加:ループ変数 i と row の内容を確認
# for j, e in enumerate(row) : # 不明な範囲はコメントアウト
# print(f'mat[{i}][{j}]={e}') # 不明な範囲はコメントアウト- コメントアウト/アンコメントのショートカットは
[Ctrl]+[/]です。頻繁に使用するので定着させてください。
enumerate を使用ない例
enumerate を使用せずに、以下のように C言語ライクに実装することもできます。どちらのスタイルで書かれていても読解できるようになっておいてください。
なお、range(len(...)) は第08回講義で既に学習済みです。
5.1 C言語との違い
C言語で2次元配列を構成した場合、行の要素数 (=列の長さ) を全て同じにする必要 がありました。一方、Pythonの2次元リストでは、行ごとの要素数が異なっていても問題ありません。
次のプログラムを実行し、行ごとに要素数が異なっていても問題ないことを確認してください。
%reset -f
arr2 = [[10, 20], # 要素数2
[10, 20, 30, 40], # 要素数4
[10, 20, 30]] # 要素数3
for i,row in enumerate(arr2):
for j, e in enumerate(row) :
print(f'mat[{i}][{j}]={e}')5.2 2次元配列の様々な初期化の方法
次の各プログラムは、どれも同じように2次元リスト
mat
を初期化します。いずれの初期化方法も読み書きできるようになっておいてください
(自分では使わない初期化方法でも、プロジェクトメンバーの誰かが使う可能性があります)
。
なお、どの方法で初期化するのが最善であるかは状況によって異なります。また、第10回講義のリスト操作の負荷量の比較についても、再度確認しておいてください。
プログラムは眺めだけでは身に付かないので、少なくとも貼り付けして、実行してください。
%reset -f
mat = [] # 長さ0のリスト (空のリスト) を作成
mat.append([10,20,30]) # 要素にリストを追加
mat.append([40,50,60])
print(mat)%reset -f
mat = [0]*2 # 長さ2のリストを作成。[1]*2 でも [None]*2 でもよい
mat[0] = [10,20,30] # 0番目の要素を上書き
mat[1] = [40,50,60]
print(mat)%reset -f
mat = [ [0]*3, [0]*3 ] # mat = [[0]*3]*2 とすると予期せぬ結果
# print(mat)
mat[0][0] = 10
mat[0][1] = 20
mat[0][2] = 30
mat[1][0] = 40
mat[1][1] = 50
mat[1][2] = 60
print(mat)%reset -f
mat = [ [0]*3, [0]*3 ] # mat = [[0]*3]*2 とすると予期せぬ結果
for i in range(6):
mat[i//3][i%3] = (i+1)*10
print(mat)特に list_init4.py において
mat = [ [0]*3, [0]*3 ] ではなく
mat = [[0]*3]*2 のように初期化すると 予期せぬ結果 になることを
実際に確認 (超重要)
してください。
6 確認
次のセクションの解説は、基本的な変数やリスト操作の理解を前提としています。以下の定着確認が解けない場合、解説を読んでも十分に理解することができません。その場合は、自分が理解できている段階まで戻って、もう一度学習し直してから進んでください。
6.0.1 定着確認1
次のプログラムの実行結果 (標準出力される文字列) を答えよ。
- 答え:
a=20, b=10
6.0.2 定着確認2
次のプログラムの実行結果 (標準出力される文字列) を答えよ。
- 答え:
a=[50, 20]
6.0.3 定着確認3
次のプログラムの実行結果 (標準出力される文字列) を答えよ。
- 答え:
a=[80, 90], b=[10, 20]
7 リストの浅いコピーと深いコピー
実用的なプログラム (例えば 課題05 など) を作成する場合、「リスト型」や「辞書型」の利用は必要不可欠です。そして、それらを利用するにあたり、知っておかないと大きくハマるもの (詰むもの) として 浅いコピー/深いコピー という概念があります。
また、またそれと密接に関連する概念として 参照、オブジェクトID、バインド (束縛)、ミュータブル/イミュータブル というものがあります。
C言語の学習では「ポインタ」という概念/仕組みの壁を超えられずに脱落・挫折する人が多いことがよく知られています。同様にPythonの「浅いコピー/深いコピー」や「参照/バインドという仕組み」も 初学者にとって大きな壁 となります。一旦、理解してしまえば何ということもない概念・仕組みなのですが、初めて学ぶときには「非常に難解」「理解不能」という印象を受けると思います。しかし、ここの壁を超えて本質的な理解を得ないと、今後の開発や学習に多大な支障が生じることになります (例えば 分数や小数の本質を理解しないままに、中学数学に取り組むようなもの です) 。
(プロンプト例)
先生が、C言語の学習では「ポインタ」という概念・仕組みの壁を超えられずに脱落・挫折する人が多い、と言っていたのですが、本当ですか?
(プロンプト例)
情報系学科に所属していてPythonを勉強中なんですが、先生から「浅いコピー/深いコピー」や「参照/バインド」を理解しないと、後で絶対に地獄を見ると脅されました💦実際のところ、これらを学ぶ必要性って本当にあるのでしょうか?
ここからの先の内容は 多くの人にとって簡単に理解できるものではない (一発理解はまず不可能)、少なくとも 数時間、2週間~1ヵ月程度 は悩むもの、という前提で挑んでください (2時間悩んで理解できなくても普通です、2・3日の時間をあけて見直すことで理解できることも多々あります) 。取り組む際のポイントは 頭で悩む (考える) だけではなくて「調べる」と「試す」をバランスよく組み合わせる ことです。
(プロンプト例)
Python において「浅いコピー (シャローコピー) / 深いコピー (ディープコピー) 」や「参照の概念」は、初心者が2時間悩んで理解できなくても普通です。2・3日かけてやっと理解できることもあります。…と言われたのですが、そんなものですか?
また、この講義資料だけではなく「ウェブ」や「YouTube」などの様々な資料や解説、生成AIなどもあわせて理解に努めてください。
アドバイス
ここから先は、皆さんが脳内にこれまでにコツコツと築いてきた「プログラムの動作モデル」を、破壊し再構築してもらうような内容となります。例えば「昼と夜があるのは太陽が動くから」と思っている幼稚園児や小学生に対して 「昼と夜があるのは、太陽が動くからじゃなくて、実は地球が自転してるから」 だと理解してもらう、それを受け入れてもらうような内容となります。
「地球は平面であり、また動いているのは太陽である」という理解のほうが直感的であり、また、その解釈であっても (身近な生活に関わるようなことは) ほとんど矛盾なく説明ができてしまいます。それゆえに「意味不明」と思考停止し、理解の追及を諦めてしまう子供もいます。
以降の説明も、同じようなもので、「意味不明」と思考停止し、理解の追及を諦めてしまう人もいますが、なんとか乗り越えてください。
7.1 理解のためのステップ1 ~出題編~
次のプログラムを実行したときの 第21行目の実行結果 (出力) について考えてみてください。そのうえで実際にプログラムを実行し…
- 自分の考えた実行結果 (出力)
- 実際の実行結果 (出力)
…を比較してみてください。
%reset -f
# a の初期化
a = [10,20,30]
# b に a をコピー (ここがポイントです)
b = a
# a と b の内容を確認
print(f'a={a}') # => a=[10, 20, 30]
print(f'b={b}') # => b=[10, 20, 30]
assert a == b # a と b が「等しいこと」を念のために確認
# a のゼロオリジンで2番目の要素を変更
a[2] = -1
# a と b の内容を確認
print('---')
print(f'a={a}') # => a=[10, 20, -1]
print(f'b={b}') # => 🤔どのような出力がえられるか?実行してみると、次のような結果が得られたはずです。
この実行結果は、初心者にとっては
予期せぬ不可解な現象
(a[2] = -1が、なぜか b
にも影響を与えている謎現象💦) だと思います。
a=[10, 20, 30]
b=[10, 20, 30]
---
a=[10, 20, -1]
b=[10, 20, -1] 👈なぜ、ここも変化するの?第16行目で変数aしか操作してないのに...では、上記の 第07行目 の b=a を
b=[10,20,30]
に書き換えて、再度、実行してみてください。今度は、脳内で予測したものと同じ結果が得られるはずです。
a=[10, 20, 30]
b=[10, 20, 30]
---
a=[10, 20, -1]
b=[10, 20, 30]「なぜ、このような結果の違いが生じるのか」について、ここから順を追ってじっくりと考え、丁寧に謎を解明していきます。
1文1文を注意深く読んでください (既に理解しており仕組みを説明ができる学生は流し読みでOKです)。
第一に「ここで不可解と感じること」は上記の
step1-1.py の 第16行目
で、a[2] = -1 のように リストaを対象に要素 a[2]
の書き換えをしている はずが、どういうわけか リストbに対しても影響を与えていること
です。
このようなことは、少なくとも以下の step1-2.py
のように 変数 a に「リスト」ではなく
「整数値」
を代入していたケースでは起きていませんでした**
(実際に実行して確かめてください)。
%reset -f
a = 30 # リストではなく整数値
b = a
# a と b の内容を確認
print(f'a={a}, b={b}') # => a=30, b=30
assert a == b # a と b が「等しいこと」を念のために確認
# 変数 a に変更をくわえる
a = -1
# a と b の内容を確認
print('---')
print(f'a={a}, b={b}') # => a=-1, b=30 (bは影響を受けずに30のまま)。実行結果は、次のようになるはずです。つまり、第11行目
の a = -1 は、変数 b に対して影響を与えていないこと が分かります。
a=30, b=30
---
a=-1, b=30「整数値」を扱っているときは起きないのに、「リスト」を扱うとき「だけ」に起きる不思議な挙動を、よりしっかりと認識するために、以下の
step1-3.py
を使って実験してみます。ここまでのことを踏まえて、以下のプログラムの実行結果を十分に検討・予想したうえで、実行して、その結果を確認してください。
%reset -f
a = [10,20,30]
b = a
c = a
a[0] = -1
b[1] = -2
c[2] = -3
print(f'a={a}') # 出力はどうなるか
print(f'b={b}') # 出力はどうなるか
print(f'c={c}') # 出力はどうなるか上記 step1-3.py
の第03行目以降を色々と書き換え
(例えば、第04行目を c=a から
c=b に書き換えるなどして)
、その挙動について考察してみたり、仮説を立ててみたりしてください。現段階では「なぜ、このような結果となるか」ではなく、まずは「(仕組みはブラックボックスでかまわないので、結果として)
どのようなことが生じするのか」を推理してみてください。
また、次の step1-4.py のようにリスト
a に対して pop()
で「要素数を減らす操作」をするとどうなるか、確認してみてください。
%reset -f
a = [10,20,30]
b = a
c = a
a.pop() # aを対象に末尾の要素を削除
print(f'a={a}') # => [10,20]
print(f'b={b}') # 出力はどうなるか
print(f'c={c}') # 出力はどうなるか7.1.1 「ステップ1」の定着確認
次のプログラムの実行結果 (標準出力される文字列) を答えよ。なお、現段階では「なぜ?」という仕組みを説明できる必要はありません。実行結果だけが答えられれば問題ありません。
- 答え:
a=90, b=10
- 答え:
a=[10, 20, 90], b=[10, 20, 90]
- 答え:
a=[10, 90, 30], b=[10, 90, 30]
7.2 理解のためのステップ2 ~出題編~
(十分に手を動かして結果について分析すれば) 以下の
step2-1.py
ようなプログラムでは、第05行目以降で変数
a に対して何らかの操作をすると…
- 変数
bと 変数cに対しても同じ操作が連動して適用されるような挙動を示すのではないか - (連動しているのではなく) 変数
aとbとcの実体は同じモノではないのか- つまり、Windowsファイルシステムの「ショートカット」のように、ひとつの実体に対して複数のアクセス手段を持っている状態になっているのではないか?
…といった仮説が立てられると思います。
ところで、次の step2-2.py
ようなプログラムは試したでしょうか。結果を予測したうえで、実際に実行して確認してみてください。
%reset -f
a = [10,20,30]
b = a
c = a
a = [60,70,80] # a[0]=1 や a.pop() のような操作ではない点に注意!!
print(f'a={a}') # => [60,70,80]
print(f'b={b}') # 出力はどうなるか
print(f'c={c}') # 出力はどうなるかこれにより さらに混乱してきた と思います。
7.2.1 「ステップ2」の定着確認
次のプログラムの実行結果 (標準出力される文字列) を答えよ。なお、現段階では「なぜ?」という仕組みを説明できる必要はありません。実行結果だけが答えられれば問題ありません。
- 答え:
a=[90, 80, 70], b=[10, 20, 30]
- 答え:
a=[10, 20, 30], b=[90, 80, 70]
- 答え:
a=[10, 20, 90], b=[10, 20, 90]※bも影響を受けている
- 答え:
a=[10, 20, 90], b=[10, 20, 30]※bは影響を受けていない
7.3 理解のためのステップ3 ~出題編~
ここまでの状況を整理してみます。
まず、以下の step3-1a.py や
step3-1b.py のように変数 a
に代入しているものが「整数型」や「文字列型」のとき
は直感に反しない動作となります。ここでは、念のために
assert を使って a と b
が「等しくないこと」も確認しています。以下のプログラムを実際に実行して結果を確認してください。
%reset -f
a = 10 # aに代入するのは「整数型」
b = a
a = a+1 # 変数 b は、この操作の影響を受けない
assert a != b
print(f'a={a}') # => a=11
print(f'b={b}') # => b=10%reset -f
a = 'ABC' # aに代入するのは「文字列型」
b = a
a = a+'DEF' # 変数 b は、この操作の影響を受けない
assert a != b
print(f'a={a}') # => a=ABCDEF
print(f'b={b}') # => b=ABCまた、変数 a
に代入しているものが「リスト」であっても、以下の
step3-2a.py のように 第04行目 で
a = [10,10,30] とした場合は直感どおりの動作 (= 変数bは影響を受けていない結果 )
となります。実際に実行して結果を確認してください。
%reset -f
a = [10,20,30]
b = a
a = [10,90,30] # a[1]を90にするために a[1]=90 ではなく a=[10,90,30] を実行
print(f'a={a}') # => [10,90,30]
print(f'b={b}') # => [10,20,30] 影響を受けていないしかし、上記 step3-2a.py の
第04行目 を a = [10,10,30] から
a[1]=90 に書き換え、以下の step3-2b.py
のようにすると…
実行結果は、以下のようになります。
a=[10, 90, 30]
b=[10, 90, 30] 👈影響を受けている以上の動作は「a に対する操作 (
a[1]=10 ) が、b
に対しても適用されている」あるいは「a
と b
が同じ実体を指すショートカットのように機能している」といえる結果となります。
一方で、step3-2b.py の 第03行目
を b=a から b = [10,20,30]
にすれば、a と b
は独立した変数として振る舞うようになります。
%reset -f
a = [10,20,30]
b = [10,20,30] # ここを b=a から b=[10,20,30] に書き換えた
a[1]=90
print(f'a={a}')
print(f'b={b}')実行結果は、以下のようになります。
a=[10, 90, 30]
b=[10, 20, 30]以上のようにPythonプログラムが振る舞うことは、どのように説明をつけることができるのでしょうか。
7.3.1 「ステップ3」の定着確認
次のプログラムの実行結果 (標準出力される文字列) を答えよ。なお、現段階では「なぜ?」という仕組みを説明できる必要はありません。実行結果だけが答えられれば問題ありません。
append()は第08回講義で既に学習済み。- 答え:
a=[10, 90, 30, 40], b=[10, 90, 30, 40]。仮説:aとbは同一の実体を指し示している?
- 答え:
a=[10, 20, 30, 40], b=[10, 90, 30]。aとbは独立した変数として振る舞う。
7.4 理解のためのステップ4 ~解答編~
結論から言えば、次のような解釈によって step3-2b.py
のようなPythonプログラムの振る舞いを全て説明することができます。
7.4.1 1.
Pythonにおいて「データを抽象的に表したもの」を
オブジェクト
とよび、具体的には「整数」「実数」「文字列」「リスト」「辞書」…のように、変数に代入可能な全てのものは「オブジェクト」に位置づけられます。例えば
10 も 'ABC' も [10,20,30]
も True
も「全て変数に代入可能なデータ」であり、したがってオブジェクトとなります。
中級者向け:Pythonでは「関数」も変数に格納可能なので オブジェクト (第一級オブジェクト) に属します。
7.4.2 2.
プログラム実行中に新たにオブジェクトが作成されると、そのオブジェクトには オブジェクトID という識別子 (番号) が自動的に割り振られます。この「オブジェクトID」は、他のオブジェクトIDとは重複しない固有の整数値 (int型) であり、それは「オブジェクト」と1対1の関係になります。
オブジェクトIDは、組込み関数の id()
を使って確認することができます。
%reset -f
a = [10,20,30]
b = a
print(f'変数 a 指し示すオブジェクトのID = {id(a)}')
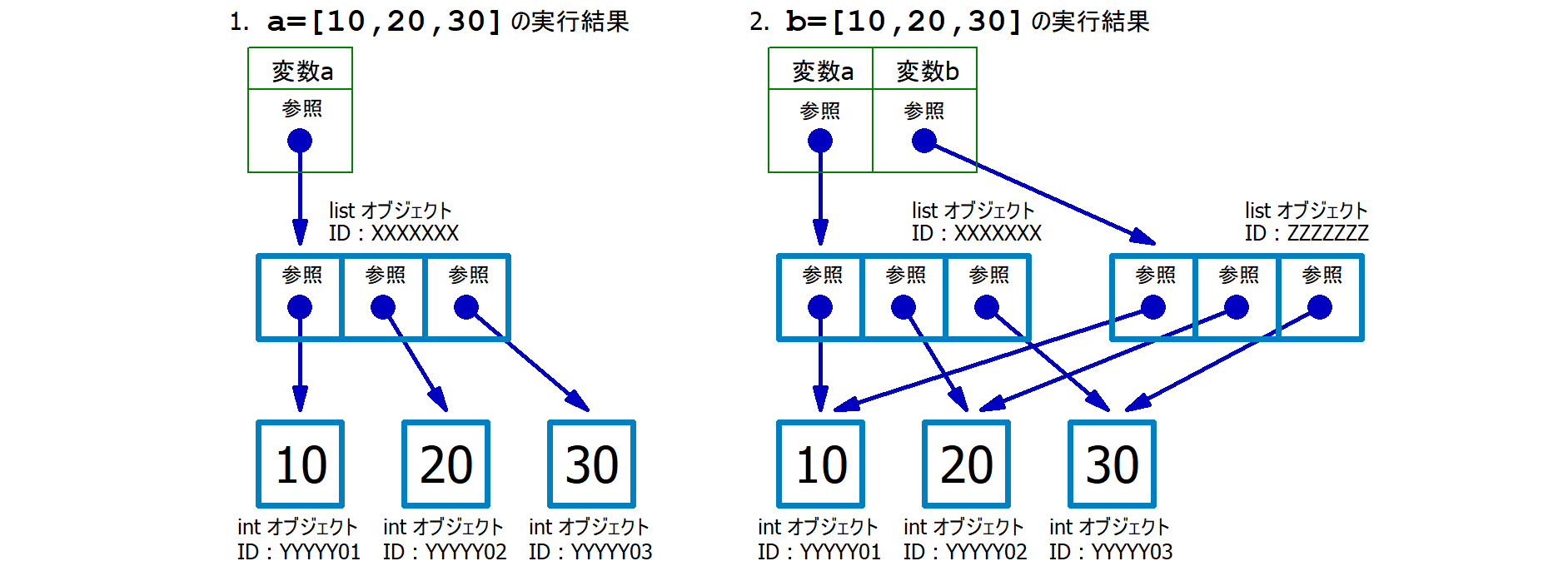
print(f'変数 b 指し示すオブジェクトのID = {id(b)}')上記を実行してみると、以下のように、変数 a が指し示しているオブジェクト (=a の参照先) と、変数 b が指し示しているオブジェクト (=b の参照先) が 同じであること が分かります。なお、実行毎にオブジェクトIDは変化します。
変数 a 指し示すオブジェクトのID = 132664295951936
変数 b 指し示すオブジェクトのID = 132664295951936 👈 a と同じID一方で、以下のようにすると…
%reset -f
a = [10,20,30]
b = [10,20,30] # ◀◀◀ ここが先ほどとは違う
print(f'変数 a 指し示すオブジェクトのID = {id(a)}')
print(f'変数 b 指し示すオブジェクトのID = {id(b)}')以下のように、変数 aの参照先と、変数
b 参照先が 違うこと
が分かると思います。
変数 a 指し示すオブジェクトのID = 132664650495168
変数 b 指し示すオブジェクトのID = 132663523312768 👈 a と違うID7.4.3 3.
プログラム内部では「オブジェクトの参照 (=オブジェクト本体を指し示すものを「参照」といいます)」から「オブジェクトの本体 (つまり、データそのもの)」にアクセスすることができます。
- オブジェクトの参照 (ID)
は「電話番号」のようなものと考えるとイメージを掴みやすいかと思います。
- 変数には、オブジェクト本体が格納されるのではなく、オブジェクトにコンタクト可能な電話番号 が格納されるイメージです。
7.4.4 4.
プログラミング初学者に対して a=10 を…
aという箱に10という値を入れる
… のように説明することが多いですが、実は正しくありません。
また、同様に b=a を…
bに、aに格納されている「10」を複製して格納する
… のように説明することも多いですが、これも正しくありません。
(実は正確ではない内部モデルの図解)

7.4.5 5.
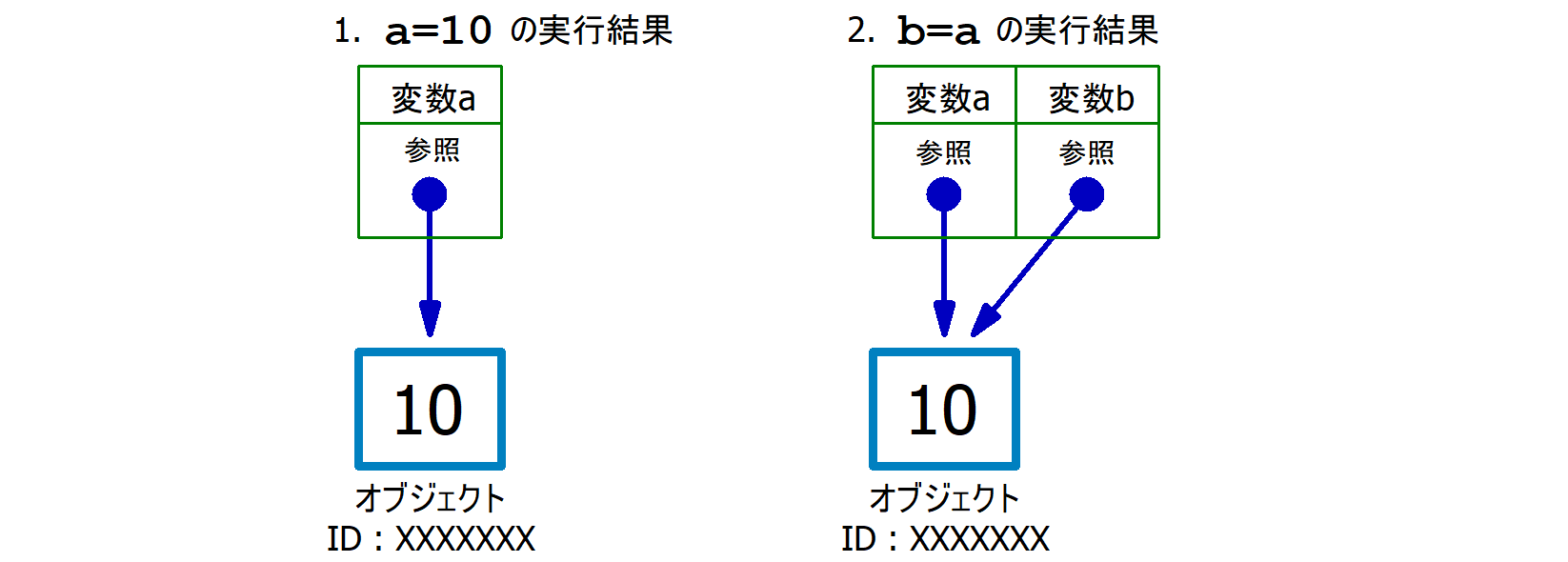
a=10 については…
10というオブジェクトを生成し、そのオブジェクトを指し示すもの (=参照) を変数aに格納する
…が、正確な説明・解釈となります。
また、同様に b=a については…
bに、aに格納されている「参照」を複製して格納する
…が、正確な説明・解釈となります。
(適切な内部モデルの図解)
中級者向け:より正確には…
より正確には、変数に格納されるのは「オブジェクトID」ではなく「オブジェクトへの参照」になります。
id()
で取得できる「オブジェクトID」は参照先を特定する値ですが、変数が直接IDを格納しているわけではありません。
7.4.6 6.
同様に print(a) は「変数 a
に格納されている値を表示する」ではなく、「変数
a
に格納されている参照が指し示す「オブジェクト」の値を表示する」というのが、より厳密な説明になります。
7.4.7 7.
このように、変数に対して (オブジェクト本体ではなく) オブジェクトを一意に特定できる「参照」を格納することを バインド と表現します。バインドとは「束縛する、結びつける、紐づける」という意味で、ここでは「変数」と「オブジェクト」を 紐づけする という意味で使われます。
7.4.8 8.
以上より a=10 は「変数 a に
10 を格納する」ではなく、「変数 a
と、10 というオブジェクトを (オブジェクトIDを通して)
バインドする (紐づけする)」と解釈するのが適切です。
バインドについては、実は 第02回講義 でも触れていました。
中級者向け: 厳密には「代入」ではなく「バインド(束縛)」
Pythonにおいて city='堺' という文は
厳密にいえば「変数 city
を『堺』という文字列 (オブジェクト) にバインド
(束縛)する」という意味になります。詳しくは 小山高専・技術支援室
を参照してください。
7.4.9 具体的なプログラムで解説①
次のプログラムを使って動作を具体的に解説していきます。
%reset -f
a = [10,20,30]
b = a
a[1]=40
print(f'a={a}') # => a=[10, 40, 30]
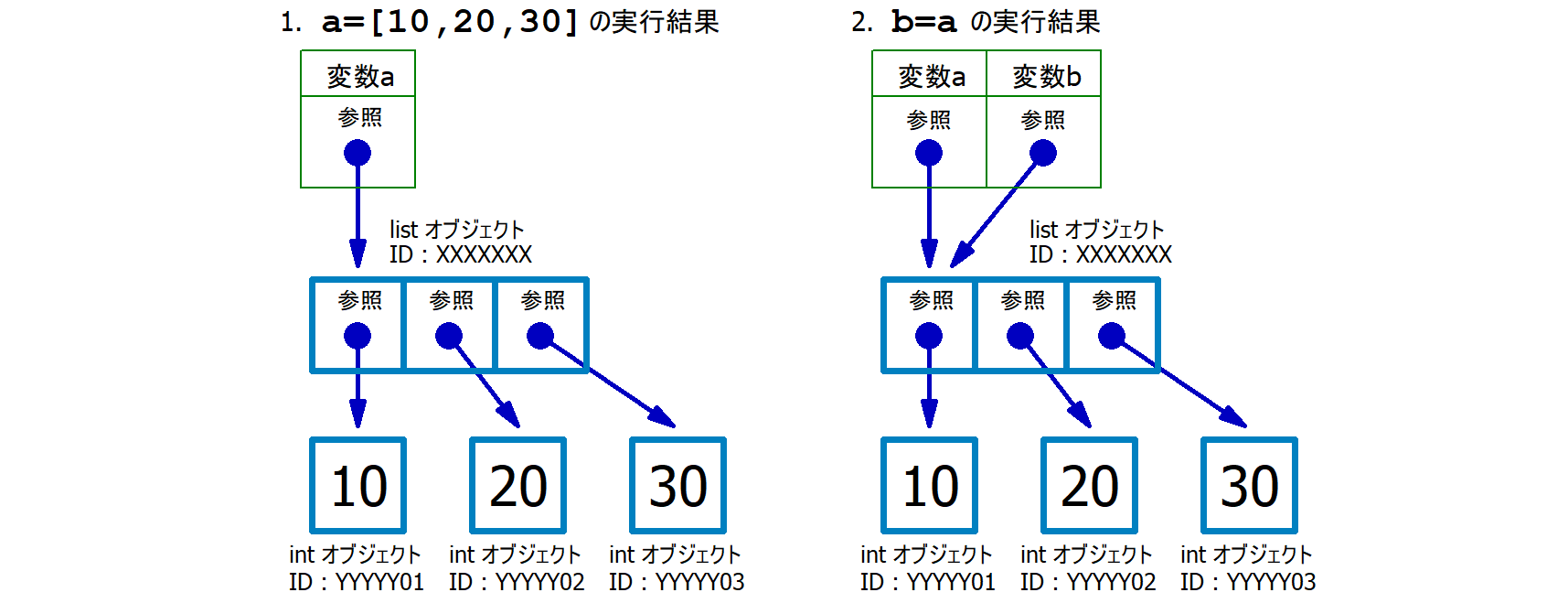
print(f'b={b}') # => b=[10, 40, 30]第02行目 : [10,20,30]
というオブジェクトを生成し、そのオブジェクトの参照
(=オブジェクトを指し示すもの) を変数
a に格納する。厳密には、10
という整数オブジェクトを生成しその参照を0番目の要素、20
という整数オブジェクトを生成しその参照を1番目の要素、30
という整数オブジェクトを生成しその参照を2番目の要素とするリストオブジェクトを生成し、その参照を変数
a に格納する。
第03行目 : 変数 a
に格納されている「参照」をコピー (複製) して、変数 b
に格納する。ここで a から b に
コピーされたのは「オブジェクト本体」ではなく「オブジェクトの参照」であることに注意
する。この結果、変数 a と 変数 b
に格納されている「オブジェクトID」は同じものとなった。
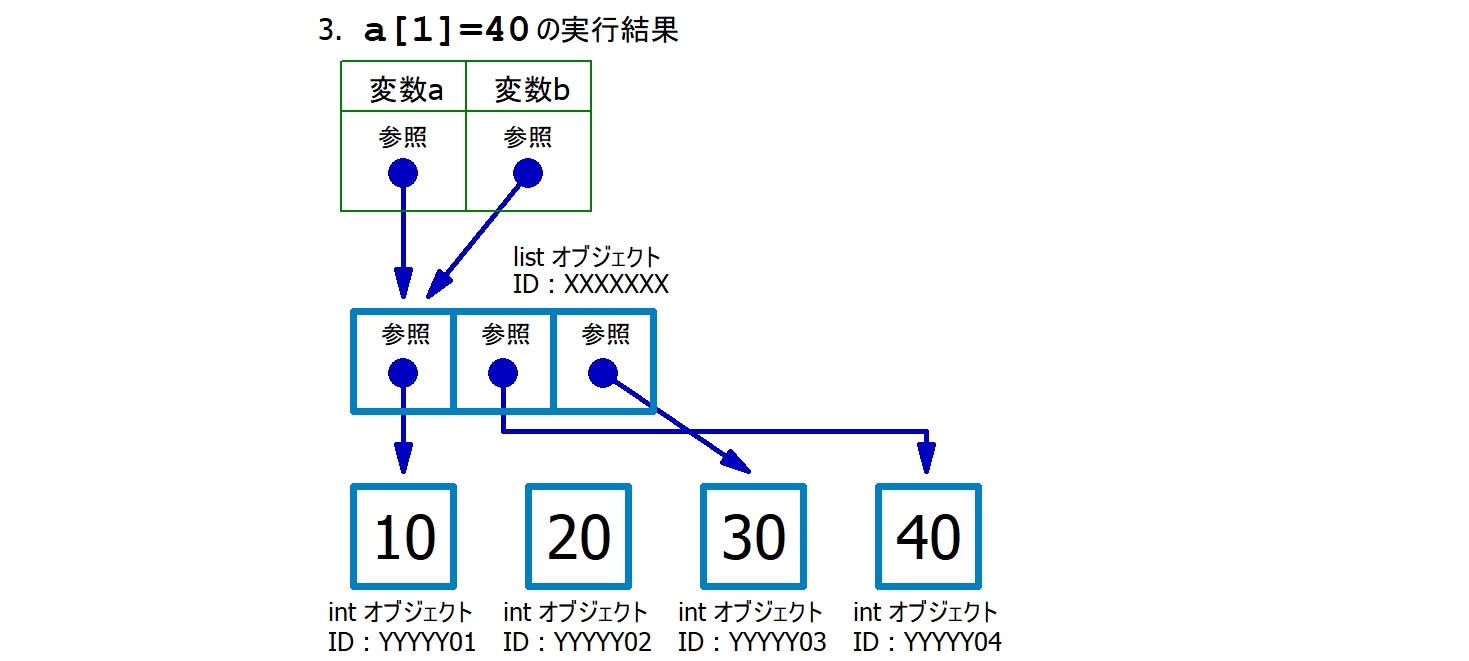
第04行目 : 40
という整数オブジェクトを新たに生成し、その参照を「変数
a が参照するリスト型オブジェクトの1番目の要素
a[1]」に格納する。
第05行目 : 変数 a
に格納されている参照先 (リストオブジェクト) の値を表示する。
第06行目 : 変数 b
に格納されている参照 (=変数 a
に格納されている参照と同じ) の値を表示する。
以上の解釈・説明によって、第06行目の出力が
b=[10, 40, 30] となることが自然に説明できました。
7.4.10 具体的なプログラムで解説②
次のプログラムを使って動作を具体的に解説していきます。
%reset -f
a = [10,20,30]
b = [10,20,30] # ここを書き換えた
a[1]=40
print(f'a={a}') # => a=[10, 40, 30]
print(f'b={b}') # => b=[10, 20, 30] # ここの結果が異なる第02行目 : [10,20,30]
というオブジェクト (ID:XXXXXXX)
を生成し、その参照を変数 a に格納する。
第03行目 : 新たに [10,20,30]
というオブジェクト (ID:YYYYYYY)
を生成し、その参照を変数 b
に格納する。第02行目で生成されたリストオブジェクトと、この第03行目で生成されたリストオブジェクトは別物なので、当然、そのオブジェクトIDは違う。
第04行目 : 40
という整数オブジェクトを生成しその参照を、変数 a
が参照するリスト型オブジェクトの1番目の要素に格納する。
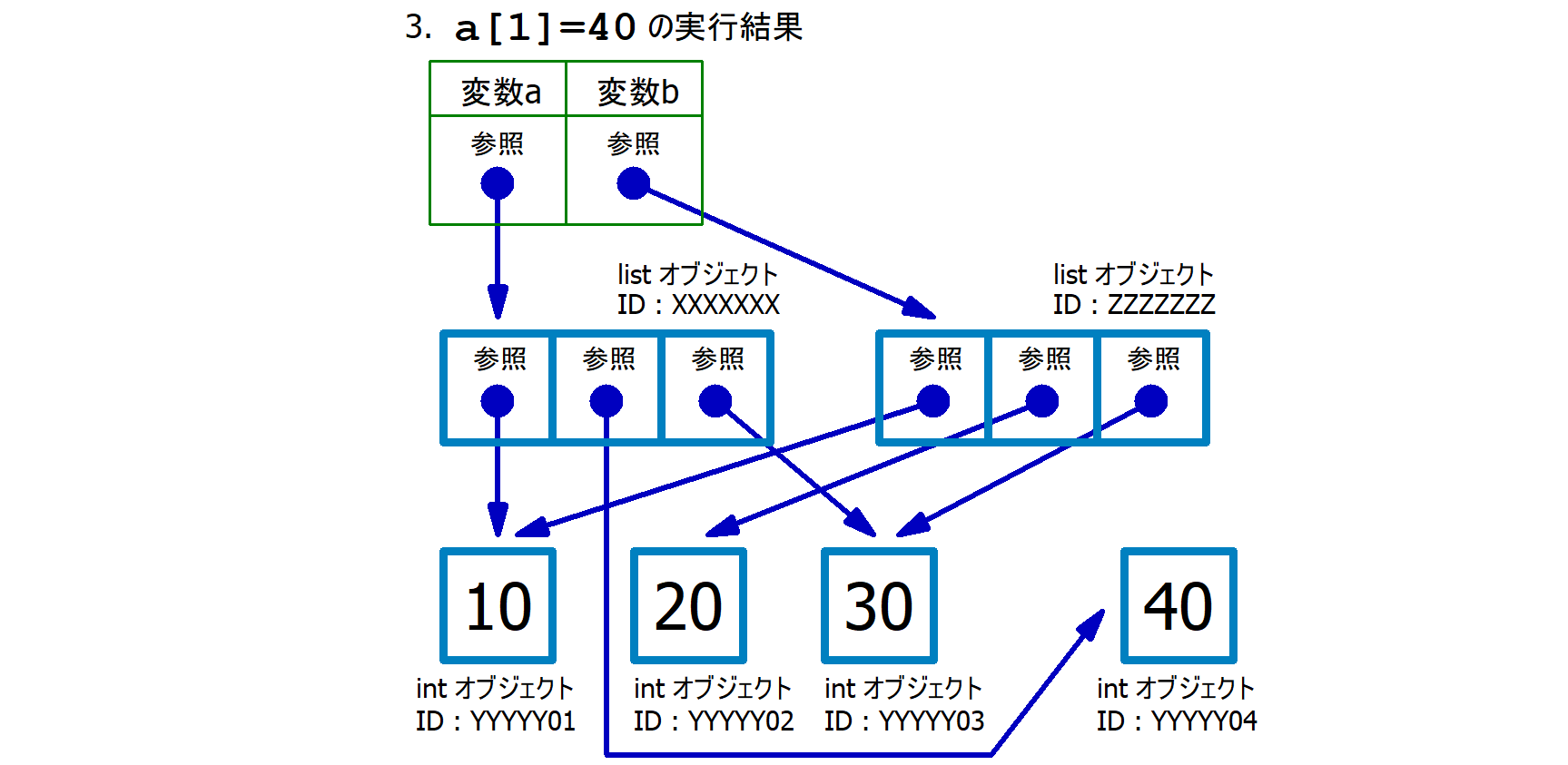
第05行目 : 変数 a
に格納されている参照先のリストオブジェクトの値を表示する。
第06行目 : 変数 b
に格納されているオブジェクトID (=変数 a
に格納されている「オブジェクトID」とは違う)
に紐づいたリスト型のオブジェクトの値を表示する。
以上の解釈・説明によって、第06行目の出力が
b=[10, 20, 30] となることが自然に説明できました。
次のプログラムを使って、変数 a と変数
b が参照するリストオブジェクトが 異なるものであること が確認できます。また
a[2] と b[2] が参照するオブジェクトが
同じものであること
が確認できます。
%reset -f
a = [10,20,30]
b = [10,20,30]
print(f'id(a) => {id(a)}')
print(f'id(b) => {id(b)}')
print()
print(f'id(a[2]) => {id(a[2])}')
print(f'id(b[2]) => {id(b[2])}')実行結果の一例です。
id(a) => 135993393253760
id(b) => 135993385921472 👈id(a)と違う
id(a[2]) => 10758664
id(b[2]) => 10758664 👈id(a[2])と同じ中級者向け: 一部の整数オブジェクトのキャッシュについて
CPythonでは、よく使われる -5 から 256
までの整数オブジェクトについては、インタープリタの初期化時に自動生成され、プログラム実行中は同じオブジェクトが「再利用」されます。これにより、頻繁に使用される小さな整数の処理が高速化されるようになっています。
%reset -f
# -5〜256の整数は事前にキャッシュされている
# 同じ値への参照は常に同一オブジェクトを指す
a1 = 30
a2 = 30
print(f' a1 == a2 => {a1 == a2}')
print(f'id(a1) == id(a2) => {id(a1) == id(a2)}')
print()
# 上記以外の整数は、通常、新規作成される
# (同一ブロック内では最適化により再利用される場合もある)
b1 = 30000
b2 = 30000
print(f' b1 == b2 => {b1 == b2}')
print(f'id(b1) == id(b2) => {id(b1) == id(b2)}')実行結果は次のようになります。
a1 == a2 => True
id(a1) == id(a2) => True
b1 == b2 => True
id(b1) == id(b2) => False変数 b1 と b2
は、異なるオブジェクトを参照していることが確認できます。
7.4.11 具体的なプログラムで解説③
次のプログラムを使って動作を具体的に解説していきます。
第02行目 : 10
という整数オブジェクトの参照を変数 a に格納する。
第03行目 : 変数 a
に格納されている参照を変数 b にコピー(複製)する。
第04行目 : 変数 a
に格納されている参照に紐づくオブジェクト (つまり 10 )
と、1 を加算して、新たなに 11
という新たなオブジェクトを生成し、その参照を変数 a
に格納する。
第05行目 : 変数 a
に格納されている参照の値を表示する。
第06行目 : 変数 b
に格納されている参照の値を表示する。
中級者向け:オブジェクトIDからオブジェクト本体を参照する
オブジェクトIDからオブジェクトを参照する方法を紹介しますが、通常のプログラムでは利用しません。非推奨です。あくまで、動作を理解するための実験に使ってください。
7.4.12 「ステップ4」の定着確認1
次のプログラムを実行したとき、各 print
関数によって標準出力される値を答えよ。
%reset -f
a = [10, 20, 30]
b = a
print(id(a)==id(b)) # 問題1
b = [10, 20, 30]
print(id(a)==id(b)) # 問題2
print(a==b) # 問題3
b[1] = 90
print(a==b) # 問題4- 問題1の答え : True
- 問題2の答え : False
- 問題3の答え : True
- 問題4の答え : False
次のプログラムを実行したとき、各 print
関数によって標準出力される値を答えよ。
%reset -f
a = [10, 20, 30]
b = [] # 空の配列
b.append(10)
b.append(20)
b.append(30)
print(id(a)==id(b)) # 問題1
print(a==b) # 問題2
a = [10, 20, 30]
c = []
for x in a:
c.append(x)
print(id(a)==id(c)) # 問題3
print(id(b)==id(c)) # 問題4
print(a==c) # 問題5
print(b==c) # 問題6- 問題1の答え : False
- 問題2の答え : True
- 問題3の答え : False
- 問題4の答え : False
- 問題5の答え : True
- 問題6の答え : True
7.5 理屈は分かったものの不便ではないか
プログラムのなかで、あるリストを複製して、それを少しだけ変更して使いたい場合があります
(当然ながら、複製元には影響を与えずに) 。そのようなとき 単純に「b=a」のようにリストをコピーする
のではダメであることを学びました。
そのような目的のためには、次のようなプログラムを書く必要があります。
%reset -f
a = [10,20,30]
b = [0]*len(a) # aと同じ要素数でbを初期化
for i in range(len(a)): # 要素を1個1個コピー
b[i]=a[i]
assert a==b # オブジェクトの値は同じだが
assert id(a)!=id(b) # オブジェクトとしては別物
b[1]=10 # 複製したものを部分変更
print(f'a={a}') # => a=[10, 20, 30]
print(f'b={b}') # => b=[10, 10, 30] # 複製先だけが変更されているただし、上記の copy1.py のようなプログラムは 2次元リスト、3次元リスト、あるいは、辞書
を要素とする場合には、その階層分だけ複製処理を繰返す必要があります。
リストの「複製」のテクニック
リストを複製する場合、空のリストに append()
を繰り返すよりも、複製元と同じ要素数のリスト (要素の値は適当でOK)
を作成して、そこに値を代入していくほうが高速です。また、copy()
メソッドを使うとさらに高速になります。
ただし、リストの要素数が少ない場合(数十個程度)では体感的な速度差はほとんどありません。
%reset -f
arr = [10, 20, 30]
cloned_arr = []
for a in arr :
cloned_arr.append(a)
print(cloned_arr) # => [10, 20, 30]
print(id(arr)==id(cloned_arr)) # => False%reset -f
arr = [10, 20, 30]
cloned_arr = [0]*len(arr)
for i in range(len(arr)) :
cloned_arr[i] = arr[i]
print(cloned_arr) # => [10, 20, 30]
print(id(arr)==id(cloned_arr)) # => False%reset -f
arr = [10, 20, 30]
cloned_arr = arr.copy() # 注目
print(cloned_arr) # => [10, 20, 30]
print(id(arr)==id(cloned_arr)) # => Falseなお、.copy()
は、後述のような浅いコピーです。ネストされたリストなどを含む場合は、参照が共有されている点に注意してください。
例えば、次の copy1-a1.py や
copy1-a2.py では意図するコピーができていません。
%reset -f
a = [[10,20],[30,40]] # 2次元リスト
# 詰めの甘いコピー(浅いコピー)
b = [0]*len(a)
for i in range(len(a)):
b[i]=a[i]
b[1][0]=10 # 複製したものを部分変更
print(f'a={a}') # => a=[[10, 20], [10, 40]] # 複製元も影響を受けた
print(f'b={b}') # => b=[[10, 20], [10, 40]]%reset -f
a = [[10,20],[30,40]] # 2次元リスト
# 詰めの甘いコピー(浅いコピー)
b = a.copy()
b[1][0]=10 # 複製したものを部分変更
print(f'a={a}') # => a=[[10, 20], [10, 40]] # 複製元も影響を受けた
print(f'b={b}') # => b=[[10, 20], [10, 40]]この問題は、次の copy1-b.py
ように解決する必要があります。
%reset -f
a = [[10,20],[30,40]]
# 深く奥までコピーする
b = [0]*len(a)
for i in range(len(a)):
b[i] = [0]*len(a[i])
for j in range(len(a[i])):
b[i][j]=a[i][j]
b[1][0]=10 # 複製したものを部分変更
print(f'a={a}') # => a=[[10, 20], [30, 40]]
print(f'b={b}') # => b=[[10, 20], [10, 40]] # 複製先だけが変更されているしかし、これは階層が増えてくると明らかに面倒です (バグの温床にもなります)。
このようなときは copy モジュールを使用し、以下の
copy2.py
のように記述します。こちらは、2次元リスト、3次元リスト、あるいは、辞書を要素とする場合でも問題なく対応してくれます。
%reset -f
import copy # 要import
a = [[10,20],[30,40]]
b = copy.deepcopy(a) # この1行で深いコピー
b[1][0]=10 # 複製したものを部分変更
print(f'a={a}') # => a=[[10, 20], [30, 40]]
print(f'b={b}') # => b=[[10, 20], [10, 40]]ここで b=a のようなオブジェクトIDだけのコピーを
浅いコピー (Shallow
Copy)、それに対してオブジェクトそのものの複製をつくることを
深いコピー (Deep Copy)
と言います。
7.5.1 「ステップ4」の定着確認2
次のプログラムを実行したとき、各 print
関数によって標準出力される値を答えよ。
%reset -f
a = [[10,20],[30,40]]
b = []
for i in a :
b.append(i)
print(id(a)==id(b)) # 問題1
print(a==b) # 問題2
a.append([50,60])
print(b) # 問題3
a[0].append(25)
print(b) # 問題4
print(id(a[0]) == id(b[0])) # 問題5- 問題1の答え : False
- 問題2の答え : True
- 問題3の答え :
[[10, 20], [30, 40]] - 問題4の答え :
[[10, 20, 25], [30, 40]] - 問題5の答え : True
次のプログラムを実行したとき、各 print
関数によって標準出力される値を答えよ。
%reset -f
a = [[10,20],[30,40]]
b = a.copy()
print(id(a)==id(b)) # 問題1
print(a==b) # 問題2
a.append([50,60])
print(b) # 問題3
a[0].append(25)
print(b) # 問題4
print(id(a[0]) == id(b[0])) # 問題5- 問題1の答え : False
- 問題2の答え : True
- 問題3の答え :
[[10, 20], [30, 40]] - 問題4の答え :
[[10, 20, 25], [30, 40]] - 問題5の答え : True
次のプログラムを実行したとき、各 print
関数によって標準出力される値を答えよ。
%reset -f
import copy
a = [[10,20],[30,40]]
b = copy.deepcopy(a)
print(id(a)==id(b)) # 問題1
print(a==b) # 問題2
a.append([50,60])
print(b) # 問題3
a[0].append(25)
print(b) # 問題4
print(id(a[0]) == id(b[0])) # 問題5- 問題1の答え : False
- 問題2の答え : True
- 問題3の答え :
[[10, 20], [30, 40]] - 問題4の答え :
[[10, 20], [30, 40]] - 問題5の答え : False
次のプログラムを実行したとき、各 print
関数によって標準出力される値を答えよ。
%reset -f
a = [[10,20],[30,40]]
b = a
print(id(a)==id(b)) # 問題1
print(a==b) # 問題2
a.append([50,60])
print(b) # 問題3
a[0].append(25)
print(b) # 問題4
print(id(a[0]) == id(b[0])) # 問題5- 問題1の答え : True
- 問題2の答え : True
- 問題3の答え :
[[10, 20], [30, 40], [50, 60]] - 問題4の答え :
[[10, 20, 25], [30, 40], [50, 60]] - 問題5の答え : True
(プロンプト例)
Pythonにおいて、リスト(特に多次元リスト)の浅いコピーと深いコピー、参照について、正しく理解できているか不安があります。理解度を確認するための問題を作成してください。リストのcopyメソッド、copyライブラリの deepcopy、組込み関数の id についても理解を確認したいです。