1 準備
- GoogleColab.
にログイン、もしくは、ローカル環境の Jupyter
を起動し、「
PG1-第12回講義.ipynb」という名前でノートブックを作成しておいてください。 - 授業の冒頭で「小テスト❹」を実施します。筆記用具を準備しておいてください。
- 前回講義で課題05
(自由課題)が出題されています。期限はだいぶ先ですが、計画的に取り組んでください。
- 期限: 2025年8月6日 (水) 23:00
2 プログラミング学習について (再確認)
第01回講義でも話したように、ジュニアレベルのプログラマ(=ソフトウェアエンジニアのタマゴとして就職して困らないレベル)に到達するには 1,000~2,000 時間 の学習 (経験) と言われています。また「超初心者」が「初心者」になるには 約250時間 の学習 (経験) が必要とも言われています。
- 参考:プログラミングを始める前に知りたかったことトップ3@YouTube
( https://www.youtube.com/watch?v=8XwG81rHRhU )
つまり、毎週の2コマ (90分) の 授業時間だけ の取組み (=90分×30回=45時間) では圧倒的に学習時間が足りません。授業だけでは4年間 (経験) 続けても1,000時間には到達せず😭、その状況で就職しても同僚や後輩とのスキル差に起因して 不安感😱、焦燥感🥵、劣等感🤮、孤独感🥶、自己否定感🤒 に悩まされる日々がつづく可能性があります。もしかして、現段階で既にそのような状況になっていませんか🙁
これは 「プログラミング」に限った話ではありません。毎週の2コマの体育 (音楽) の授業を受けているだけではスポーツ選手 (ミュージシャン) になれないこと、毎週6コマの英語の授業を受けているだけでは「通訳」や「翻訳者」になれないこと、と同じです。
では、どうすればいいのか…🙁
答えは、授業という枠を超えてプログラミングを学ぶこと (親しむこと) です。例えば、日々のスマホゲームや娯楽動画に費やす時間をプログラミング学習に変えてみてください。平日1時間、休日3時間をプログラミングに使えば、週あたり「約10時間」が確保できます。1年間は約52週なので、1年では「520時間の学習時間」となります。
普通の中高校生が 部活動や入試勉強に費やしている時間 を考えれば「平日の1時間・休日の3時間」という時間は、それほど無理な設定ではありません。また、将来的に1日8時間 × 40年間を費やす仕事に関わるスキルと考えれば、十分に投資価値のある行動・時間だと分かると思います。
…とはいえ、授業や塾、部活動のように強制力が働かない環境で「学び」を継続することは簡単ではありません。「学び」に充てる時間を無理なく確保する方法は「プログラミング関係のコンテストやセミナーに参加すること」あるいは「チームとして開発活動すること (=例えば 総合課題実習や高専祭展示に向けた開発活動!!)」です。これらの機会や環境を上手に利用して、自然とプログラミングを学ぶこと (親しむこと) ができるようにして欲しいと思います。それも楽しめないようであれば、ICTエンジニアとして働くことは苦行になると思います。
「どんな活動をすればよいか分からない」「何から学んだらよいのか分からない」「どうやって学んだらよいのか分からない」という場合は、皆さんからアポをとって足を運んでくれれば、いつもでアドバイスします。
3 復習 (リストとnparray)
前々回、前回の講義では、NumPy
(ナンパイ) の np.arange を使った
繰り返し計算処理
について学びました。基本的かつ様々な場面で利用する処理なので定着させておいてください。
3.1 練習問題
※ 今回の演習の実装例 (解答例) は こちら を参照してください。
3.1.1 問題 1
次の値を np.arange を利用して数値計算せよ。※
微分積分1の教科書 p.12 の「例1.12」から抜粋。
\[ \sum_{k=1}^{10}(4k-3) \]
- 適切に計算できれば 190 が求めるはずです。
3.1.2 問題 2
次の級数の和を np.arange を利用して数値計算せよ
(近似計算で可)。※ 微分積分1の教科書 p.28 の [6] から抜粋。
\[ \sum_{n=1}^{\infty}\frac{1}{2^{n-1}} \]
- 適切に計算できれば「2」が求めるはずです。
- この問題は プログラミング (数値計算的なアプローチ) だけでは正解にたどり着けない場面がある例で、数学的理論も必要であることを実感してもらうこと を意図した問題です。
4 辞書 (dict)
Python における 辞書 (=dict, Dictionary) は、他のプログラミング言語では 連想配列 や ハッシュ、ハッシュテーブル と呼ばれているものです。
辞書は「キー (Key)」と「値 (Value)」の組み合わせを格納する組込み型のデータ構造で「キー (多くの場合は文字列) 」を使って「値 (Value)」を高速に参照 (=取得) できる点に特徴があります。
例えば、辞書は次のように初期化して
(初期値を設定して)、その後、キーを使ってそれに対応する値を参照することができます。なお、辞書に使用する括弧は
[ ] ではなく { }
なので注意してください。
下記のプログラムを実行し、その結果を確認してください (元ネタ)
%reset -f
# 辞書の【初期化】 keyとvalueを : で区切って与える
player = {
'name': '勇者ヨシヒコ', # 各ペアはカンマで区切る
'level': 3,
'hp': 120,
'attack': 16,
'称号': '正義漢', # key には日本語も利用可能
'items': ['いざないの剣','たびびとのふく','やくそう'] # リストも格納可能
}
# 辞書の値【参照】[] に key を与えて value を参照
print( player['name'] ) # => 勇者ヨシヒコ'
# print( player[name] ) # => 実行時エラー。name という変数は存在しない上記の 第15行目 をアンコメントすると (=コメントアウトを解除すると) 実行時エラーになることを確認してください。
player['name'] ではなく player[name]
のようにしてしまうと、name
という文字列をキーとするのではなく、name
という変数を探し、その変数に格納されている値をキーとして事象の値を参照する処理
になってしまいます。プログラムのなかには name
という変数は存在しないので、当然ながら NameError
が発生します。
もし、print(player[name])
によって、意図する値を出力したいのなら、その文の前に
name='name' を記述しておく必要があります。
なお、f文字列の内部で キー (文字列) を使って辞書の値の参照する場合 は、以下のように「シングルクォーテーション」と「ダブルクォーテーション」を使い分けしてください。
もしくは、次のようにすることも可能です。
- HPを画面表示するためのコードを
dict01.pyに追加して、その結果を確認してください。 - ダブルクォーテーションだけで記述した
print(f"HP = {player["hp"]}")のような文を実行するとどうなるか。結果について推測したうえで、実際にコードを実行して検証してください。 print(player['mp'])のように存在しないキーを与えるとどうなるか。結果について推測したうえで、実際にコードを実行して検証してください。print(player)を追記し、その実行結果を確認してください。
4.1 演習1 ( 目標時間: 8分)
次のような 期待する出力 が得られるように
dict01.py の第13行目以降を書き換えてください。
(期待する出力)
勇者ヨシヒコ (正義漢)
- Lv : 3
- HP : 120
- 持ち物 : いざないの剣, たびびとのふく, やくそう(ヒント)
- 「持ち物」の一覧を出力するためには「for文」か「アンパック」を使用します。アンパックは
第10回講義
既に学習済みです。
- for文を利用する場合のヒント :
for item in player['items'] : - アンパックを利用する場合のヒント :
print( *player['items'], sep=', ' )
- for文を利用する場合のヒント :
4.2 辞書の値 (value) の更新、キーと値のペアの追加
次のプログラムを実行して、その結果を確認してください。また、その実行結果とプログラムを照らし合わせて、辞書型の特性について理解してください。必要に応じてコードを書き換えて、その実行結果がどう変化するかを実証的に確認してください。
%reset -f
# キーとして 'x' と 'y' を持った辞書の値を「整形表示」する関数を定義
def print_point(p):
assert type(p) is dict # 辞書型(dict)であることを確認
print(f"({p['x']:.1f}, {p['y']:.1f})")
p1 = {} # 空の辞書を作成(辞書の初期化)。「p1=dict()」でも同じ処理になる
p1['x'] = 10 # key:'x' value:10 の追加
p1['y'] = 20
p2 = {'y':100, 'x':50} # キーは順不同で可
p2['y'] = 40 # 書き換え(上書き)
print_point(p1)
print_point(p2)上記のプログラムの解読を通して、以下のことが分かると思います。
- 関数の引数に「辞書型」を与えることもできる。関数については第11回講義で学習済みです。
- 第05行目 のように
type(xxx) is dictによって、引数として受け取ったxxxが辞書型かどうかを確認できる。assertについても第11回講義で学習済みです。 - 変数
yyyを「空のリスト」として初期化するにはyyy=[]あるいはyyy=list()のように記述しました。これに対して「空の辞書」として初期化するにはxxx={}あるいはxxx=dict()のように記述します。 - 関数を利用することでプログラムをすっきりと記述することができます。
4.2.1 定着確認
- 変数
itemsを「空のリスト」として初期化するための文を答えよ。- 答え: list=[]
- 変数
playerを「空の辞書」として初期化するための文を答えよ。- 答え: player={}
4.3 辞書が特定のキーを持つかチェックする方法
次のようにして、辞書が 特定のキーを持っているか を判定することができます。プログラムを実行して、その結果を確認してください。
%reset -f
items = {
'やくそう':8,
'どくけしそう':2,
'ぬののふく':1
}
for x in ['やくそう', 'きえさりそう'] : # ループ変数 x は「やくそう」→「きえさりそう」
print(f'勇者ヨシヒコは「{x}」を',end='')
if x in items.keys() : # 辞書型にキー「x」が含まれるか?
print(f'{items[x]}個もっている。')
else :
print('もっていない。')4.3.1 定着確認
- 辞書型のオブジェクト
itemsのキーに'こんぼう'を含むかどうかを判定する条件式を答えよ。- 答え:
'こんぼう' x in items.keys()
- 答え:
- 辞書型のオブジェクト
itemsのキーの数を出力するprint文を記述せよ。- 答え:
print(len(items.keys()))
- 答え:
4.4 演習2 ( 目標時間: 10分)
期待する結果に示すように 辞書が持っているキーと値を全列挙する方法 について、ウェブ検索や生成AIなどを利用して調べて理解し、実際に検証してください (処理の目的が明確なとき、それを自己解決するための演習です) 。
具体的には、次のように初期化された辞書から 期待する結果 を得るようなコードを記述してください。
%reset -f
# この関数を書き換える
def print_dict(d):
assert type(d) == dict
print('...')
character_status = {
'name': 'Hiro',
'level': 10,
'hp': 100,
'mp': 30,
'attack': 15,
'defense': 10,
'experience': 0,
}
print_dict(character_status)(期待する結果)
name : Hiro
level : 10
hp : 100
mp : 30
attack : 15
defense : 10
experience : 0ヒント f文字列の書式指定 (左寄せの空白埋め、右寄せの空白埋め) を上手に活用してください。書式指定は第03回講義で既に学習済みです。
4.4.1 定着確認
- 辞書型のオブジェクト
itemsのキー (key) を全表示するためのprint文を記述せよ。- 答え:
print(*items.keys())
- 答え:
- 辞書型のオブジェクト
itemsの値 (value) を全表示するためのprint文を記述せよ。- 答え:
print(*items.values())
- 答え:
5 リストの扱いに関する補足① : for構文との組み合わせ
第08回講義で学んだように、for構文を使ってリストの全要素を参照するような処理は、次のように記述することができます。
%reset -f
items = ['やくそう', 'どくけしそう', 'ひのきのぼう', 'たびびとのふく']
# print(len(items)) # => 4
for i in range(len(items)):
print(items[i])上記では、ループ変数 c には数値ではなく、リスト
arr の要素 (つまり「やくそう」「どくけしそう」…)
が順番に格納されながら繰返し処理されます。
Python では基本的に loop01b.py
のような記述が推奨されます。loop01a.pyの記述は非推奨です。
5.1 Enumerate
リストと繰返しを組み合わせる場合、以下のように「その要素は何番目か」もあわせて出力したい場合があります。
1. やくそう
2. どくけしそう
3. ひのきのぼう
4. たびびとのふくこのような場合は enumerate 関数
(イニューマレイト関数) を利用して次のように記述できます。enumerate
は 列挙する
という意味になります。実際に実行して、その結果について確認してください。
%reset -f
items = ['やくそう', 'どくけしそう', 'ひのきのぼう', 'たびびとのふく']
for i,c in enumerate(items): # ここに注目!
print(f'{i+1}. {c}')さらに、enumerate
関数は、第2引数に初期値を設定可能で、以下のように記述することもできます。
%reset -f
items = ['やくそう', 'どくけしそう', 'ひのきのぼう', 'たびびとのふく']
for i,c in enumerate(items,1): # i の初期値を 1 に設定
print(f'{i}. {c}')enumerate
関数は、利用頻度が高いので覚えておくようにしてください
(
自分は使う予定がなくても、他人のプログラムを読む場面で出現するので、enumerateの挙動は十分に理解しておいてください
)。
5.2 演習3 ( 目標時間: 10分)
下記の「期待する出力」が得られるように、次のプログラムを変更・追記し、その実行結果を確認してください。
- ここでは
range関数とlen関数の組み合わせではなく、enumerate関数の利用を意図しています。 - ここでは
enumerateの第2引数に、適切な初期値を設定することを期待しています。 - 数値のゼロ埋め方法を忘れてしまった場合は「Python f文字列 書式指定 ゼロ埋め」などで検索してください。
%reset -f
codename = ['Coffee Lake Refresh','Comet Lake',
'Rocket Lake','Alder Lake','Raptor Lake','Meteor Lake']
# ここから先にコードを追加期待する出力
■ intel デスクトップPC用Coreプロセッサのコードネーム
第09世代 Coffee Lake Refresh
第10世代 Comet Lake
第11世代 Rocket Lake
第12世代 Alder Lake
第13世代 Raptor Lake
第14世代 Meteor Lake6 リストの扱いに関する補足② : アンパック
第10開講で簡単に触れていますが
unpack-01a.py は unpack-01b.py
のようにスマートに記述することができます。
どちらのプログラムも同じ出力が得られることを確認してください。
Pythonにおける アンパック または
アンパッキング
とは、リスト内の要素を個々の変数に分割して関数の引数に与える手法を指します。アンパックするためには、変数名の先頭に
* を与えます。
unpack-01b.pyの第03行目をprint(ip_addr,sep='.')のようにした場合 (アスタリスク*を付けていない場合) 、どのような出力を得るか。結果について推測したうえで、実際にコードを実行して確認せよ。
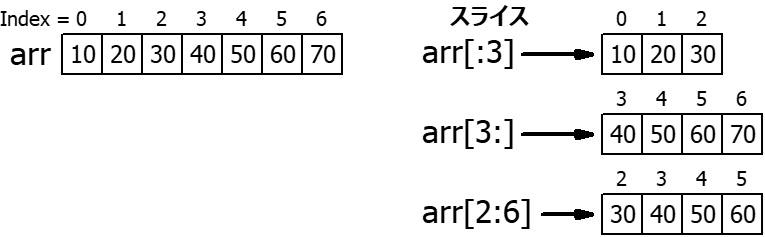
7 リストの扱いに関する補足③ : スライス
Pythonのリストでは スライス
という操作により、指定の部分範囲を取得することができます。スライスは
[] の内部で、コロン :
を使って、[開始値:終了値]
のように範囲を表現します。
例えば arr[2:6] とした場合、次の図のようにリスト
arr の「2番目から5番目
(=6-1番目)までの範囲」の部分取得ができます。また、開始値を省略すると「リストの先頭から」となり、終了値を省略すると「リストの末尾まで」の意味になります。
スライスしたものは、関数の引数などに利用可能です。例えば、次のプログラムは、合計 を求める組み込み関数 sum()
の引数に「スライスしたリスト」を与えています。実際に実行して、その結果について確認してください。
%reset -f
arr = [10,20,30,40,50,60,70,80]
s1 = sum(arr)
print(f's1 = {s1}') # sum
s2 = sum(arr[:3]) # 0番目から2番目(3番目を含まない)までの合計
s3 = sum(arr[3:]) # 3番目から最後までの合計
s4 = sum(arr[2:6]) # 2番目から5番目までの合計
print(f's2={s2}, s3={s3}, s4={s4}') print(arr[:3])、print(arr[3:])、print(arr[2:6])を追記すると、その出力はどのようになるか。結果について推測したうえで、実際にコードを実行して確認してください。arr[:]とすると、どのようになるか (何らかのスライス処理がされるのか、それとも文法エラーや実行エラーとなるのか、以下同様) 。結果について推測したうえで、実際にコードを実行して確認してください。arr[]とすると、どのようになるか。arr[:100]とすると、どのようになるか。arr[3:3]とすると、どのようになるか。arr[5:3]とすると、どのようになるか。arr[-1:]やarr[-2:]とすると、どのようになるか。arr[:-1]やarr[:-2]とすると、どのようになるか。arr[2:6:2]とすると、どのようになるか。
8 文字列に対する1文字参照やスライス処理
「文字列」は「リスト」ではありませんが、「リスト」と同じように
[] を使って要素 (=1文字)
を参照したり、スライスで部分文字列を取得することができます。半角文字、全角文字、絵文字を含めてPythonでは適切に「1文字」を切り分けることができます。
例えば、変数 item
に「やくそう」という文字列が格納されている場合…
name[0]で「や」name[0:2]で「やく」name[-1]で「う」name[1:]で「くそう」
…を参照することができます。
ただし、あくまで「リストと同じように操作できる」だけで、文字列はリストではないので
name[0]='ど'
のような操作はできません
(薬草を毒草に変えることはできません)。書き換えようとすると、どのようなエラーになるのか実際にコードを書いて確認してください。
以下は、トランプのカードを「スート (♠♦♥♣) 」と「ランク
(A234…JQK) 」の 2文字からなる文字列
として表現し、さらに []
を使って「スート」と「ランク」を個別参照している例です。実際に実行して結果を確認し、プログラムを解読・理解してください。
%reset -f
import random as r
cards = ['♠A', '♠2', '♥3', '♥4','♣Q', '♣K']
print(f'山札は {cards}')
print()
card = r.choice(cards)
print(f'山札から1枚ひいたカードは「{card}」')
print(f' スートは「{card[0]}」、ランクは「{card[1]}」でした。')
print()
cards.remove(card)
print(f'よって、現在の山札は {cards}')また、文字列は、次のようにfor文にも使うことができます。
%reset -f
string = '微分積分1で爆死'
print(' _人人_')
for c in string : # for in (文字列)
print(f'_) {c} (_')
print(' ^Y^Y^^')9 GoogleColab.の出力セルのクリア
Jupyter環境 (Google Colab.) における出力セルは
IPython.display.clear_output()
によって内容をクリア (消去)
することができます。
次のプログラムを実行して、その結果について確認してください。
%reset -f
import time
import IPython.display # 要インポート
for i in range(5,0,-1):
print(f'{i}...')
time.sleep(1) # Arduino の wait に相当。単位は「秒」
IPython.display.clear_output() # 出力セルの消去
print('🚀')
for i in range(3):
time.sleep(0.5)
print('⚡')9.1 応用例
自由課題のヒントにしてください。
%reset -f
import time
import random as r
import IPython.display
n=9 # 9回(イニング)までのゲーム委
G = [-1]*n # スコアの初期化
H = [-1]*n
wait_time = 2 # [Sec]
# チームのスコア #########################
def print_team_score(name,score):
print(f'{name}|',end='')
for i in range(n):
if score[i] != -1:
print(f'{score[i]:>2}|',end='')
else :
print(' |',end='')
print(f'{sum(score[:t]):>2}|')
# スコアボード全体の出力 #################
def print_score_board():
IPython.display.clear_output() # 出力をクリア
print('-+'+'--+'*(n+1))
print(' |',end='')
for i in range(1,n+1):
print(f'{i:>2}|',end='')
print('計|')
print('-+'+'--+'*(n+1))
print_team_score('G',G)
print_team_score('H',H)
print('-+'+'--+'*(n+1))
# メイン処理 #############################
for t in range(n):
# 先攻「G」の攻撃回
G[t] = r.choices([0,1,2,3],[5,3,1,1])[0]
print_score_board()
time.sleep(wait_time)
# 後攻「H」の攻撃回
H[t] = r.choices([0,1,2,3],[4,3,2,1])[0]
print_score_board()
time.sleep(wait_time)
if sum(H) > sum(G):
print('😄😄😄😄😄')
else :
print('😱😱😱😱😱')10 条件式の工夫
ユーザーから入力された文字列が 犬 または
いぬ または イヌ のとき、「ワン
! 」という文字列を出力する処理を考えます。
この処理 (条件分岐)
を素直に記述すると次のようになります。or で
OR条件 を表現しています。or は 第06回講義で既に学習済みです。
%reset -f
animal = input('動物名を入力してください : ')
if animal == '犬' or animal == 'いぬ' or animal == 'イヌ' :
print('ワン!')
else :
print('・・・')これに対して、(初心者において) よくある間違いとして、次の第03行目のように不適切な条件式を記述してしまうことがあります。
%reset -f
animal = input('動物名を入力してください : ')
if animal == '犬' or 'いぬ' or 'イヌ' : # 不適切な条件式
print('ワン!')
else :
print('・・・')上記の条件式 animal == '犬' or 'いぬ' or 'イヌ'
では「ネコ」を入力した場合でも「ワン !
」が出力されてしまいます。実際に実行して結果を確認してみてください。この理由は、if文の
条件式を書く位置
には、単なる「数値」や「文字列」も記述可能で、その場合、特定の値以外では条件が「真」として判定されるためです。
実際に確認してみます。以下のプログラムを実行して、その結果を確認してみてください。以下に示す例では、すべての条件が「真」として判定され、処理
(print()) が実行されています。
%reset -f
if 'いぬ' :
print('1')
if 109 :
print('2')
if -20 :
print('3')
if 3.14 :
print('4')
if ['A','B','C'] :
print('5')
if [0] :
print('6')
# 次の XXX の部分を自分で思いつく値に変更して実行してみてください。
# if XXXX :
# print('7')一方で、条件が「偽」として判定されるのは、次のように限られた値だけになります。実際に、その実行結果を確認してみてください。
%reset -f
if 0 :
print('1')
if 0.0 :
print('2')
if [] :
print('3')
if None:
print('4')
if False :
print('5')
if '' :
print('6')以上踏まえ、条件式に
animal == '犬' or 'いぬ' or 'イヌ'
を使用すると、animal
の内容に関係なく、いぬ
が「真」となってしまいます。
よって、animal
が「犬」「いぬ」「イヌ」のいずれかのときだけ「真」とするためには、最初に示したように
animal == '犬' or animal == 'いぬ' or animal == 'イヌ'
と記述するか、第08回講義
で学んだように次のようにする必要があります。
%reset -f
animal = input('動物名を入力してください : ')
if animal in ['犬','いぬ','イヌ'] : # リスト ['犬','いぬ','イヌ'] に anmial は含まれるか?
print('ワン!')
else :
print('・・・')11 プログラマの心得「前向きな怠惰の思想」
ICTエンジニア (特にプログラマやSE) には「面倒な作業はラクして簡単に瞬殺で済ませようとする「前向きな怠惰」の姿勢や信念」が必要です。これは、言い換えれば「めんどくさいことをしないためならいかなる努力も惜しまない姿勢や信念」が必要とも言えます。
「関数化できる処理を、関数定義しない」、「変数を使わずに、数値リテラルを使用する」、「同じような処理をfor文を利用せずに記述する」といった姿勢では、プログラミングスキルは一向に伸びませんし、コーディングはいつまでも面倒なままで、楽にも楽しくもなりません。
11.1 具体的な事例
一般に、自由課題では「トランプ」を使ったゲームをテーマにプログラミングに取り組む学生が多いです。
例えば、52枚のカードの初期化について、最も愚直な方法は次のようなものです。
%reset -f
# プログラマ的な発想・姿勢に基づかない初期化
cards = ['♠A', '♠2', '♠3', '♠4', '♠5', '♠6', '♠7', '♠8', '♠9', '♠10', '♠J', '♠Q', '♠K',
'♦A', '♦2', '♦3', '♦4', '♦5', '♦6', '♦7', '♦8', '♦9', '♦10', '♦J', '♦Q', '♦K',
'♥A', '♥2', '♥3', '♥4', '♥5', '♥6', '♥7', '♥8', '♥9', '♥10', '♥J', '♥Q', '♥K',
'♣A', '♣2', '♣3', '♣4', '♣5', '♣6', '♣7', '♣8', '♣9', '♣10', '♣J', '♣Q', '♣K']
print(cards)上記のコードを記述に要する時間は、せいぜい3分程度ですが、この3分の面倒を避けるために プログラムを、考えたり、調べたり、試行錯誤したりすることに1時間、2時間を費やすことができるか が、プログラミング思考になれているか、否かの指標になります。
このような めんどくさいことをしないためならいかなる努力も惜しまない
ということができれば、上記 card_init_01.py
は、次のように書けることに気付き、その内容の理解に至ると思います。これにより、このカードの初期化に相当するタスクからは
永遠に解放される
という恩恵を得ることができます。
%reset -f
# プログラマ的な発想・姿勢に基づく初期化
suit = ['♠','♥','♦','♣']
rank = ['A','2','3','4','5','6','7','8','9','10','J','Q','K']
cards = [None]*(len(suit)*len(rank))
t = 0
for s in suit:
for n in rank :
cards[t]=f'{s}{n}'
t+=1
print(f'cards={cards}')さらに、時間を費やせば、次のようなプログラムにできるというところに到達すると思います。
%reset -f
suit = list('♠♥♦♣')
rank = ['A'] + list(map(str, range(2, 11))) + list('JQK')
cards = [None]*(len(suit)*len(rank))
t = 0
for s in suit:
for n in rank :
cards[t]=f'{s}{n}'
t+=1
print(f'cards={cards}')さらに、時間を費やせば、次のようなプログラムにできるというところに到達すると思います (ラムダ式やmapなどを含んだ下記のコードを理解するためには、数時間~十数時間を必要とします、現時点では以下の詳細について必ずしも理解する必要はありません) 。
itertools.product() 関数は「情報2」の第12回講義
(データベース関連)
で学んだ集合演算の「直積」に相当する処理です。
%reset -f
import itertools
suit = list('♠♥♦♣')
rank = ['A'] + list(map(str, range(2, 11))) + list('JQK')
cards = list(map( lambda x: x[0]+x[1],itertools.product(suit,rank)))
print(f'cards={cards}')11.2 演習4 ( 目標時間: 15分)
次に示すプログラムの Step1
のトランプの初期化を「全52枚」に書き換え、さらに
judge()
関数を完成させてください。ここでカードは、ランクが大きいほうが強いものとします
(ただし、例外的にキングよりもエースが強いものとします)。
また、ランクが同じ場合は、スペード、ハート、ダイヤ、クローバの順で強いものとします (スートではスペードが最強) 。
%reset -f
import random as r
# 引数で受け取った札束の状態を確認する関数
def print_cards (x) :
assert type(x) is list
print(f' ※現在の山札は |',end='')
print(*x,sep='|',end='') # アンパック
print(f'| の {len(x)}枚 です。')
# c1 が強い場合は「True」, c2が強い場合は「False」を返す関数
def judge(c1,c2):
assert type(c1) is str
assert type(c2) is str
assert c1 != c2
return True # 現状では常に True を返す関数になっている
## Step1 ####
print(f'トランプの初期化')
cards = ['♠A', '♠2', '♥10', '♥4','♣Q', '♣K']
print_cards(cards)
## Step2 ####
print()
r.shuffle(cards)
print(f'山札をシャッフルしました。')
print_cards(cards)
## Step3 ####
print()
p1 = cards.pop()
print(f'P1が山札から 1枚ひいたカードは |{p1}| でした。 ',end='')
print(f'このカードのスートは「{p1[0]}」、ランクは「{p1[1:]}」です。')
print_cards(cards)
## Step4 ####
print()
p2 = cards.pop()
print(f'P2が山札から 1枚ひいたカードは |{p2}| でした。 ',end='')
print(f'このカードのスートは「{p2[0]}」、ランクは「{p2[1:]}」です。')
print_cards(cards)
## Step5 ####
print()
print('この勝負、P1の「',end='')
if judge(p1,p2) : # 自作関数 judge の呼び出し
print('勝ち',end='')
else :
print('負け',end='')
print('」です。')(中級者向け) 上記プログラムの Step3 と Step4 は、ほぼ同じ処理といえる。この処理を関数を使ってまとめよ。
ヒント:draw_card
という関数で、「山札」と「名前(P1やP2)」を与え、引いたカードを返すような関数
12 ライブラリのインポートに関する補足
自由課題に取り組む際、様々なウェブを参照すると思います。ウェブに掲載されているサンプルプログラムでは
from math import sin のように from
を含んだ インポートの表記
を見かけると思います。
from
を使用する場合と、使用しない場合では、以下のように、ライブラリに含まれる
関数の呼び出し が、若干変わってきます。
%reset -f
# from を使用したimport文
from math import sin,cos
x = sin(0.25)**2 + cos(0.25)**2 # math.は不要
print(x)%reset -f
# from を使用しないimport文
import math
x = math.sin(0.25)**2 + math.cos(0.25)**2 # math.が必要
print(x)import01.pyでmath.sin(0.25)とすると、どのようになるか。結果について推測したうえで、実際にコードを実行して確認せよ。import01.pyで \(\sin^{2}(\theta)+\cos^{2}(\theta)+\tan^{2}(\theta)\) を計算したい。どのようにコードを書き換えればよいか。実際にコードを書き換え、その結果について確認せよ。