1 概要・連絡
1.1 連絡事項
- 課題07 (内容の詳細)の提出期限は
11月21日 (水) 23:00 です。
- 課題07の提出先 Teamsの「PG1-課題07」
- 今回講義では
IPython.Displayを用いて表 (=DataFrame型) を整形出力します。そのためGoogleColabもしくはローカルPCに構築したJupyter環境を利用することを推奨します。- 演習問題の解答例はこちらを参照してください。
1.2 今回講義の達成目標
- ラムダ式 (無名関数) を理解して記述することができる。
- ラムダ式とmap関数を組み合わせた処理をリストに対して適用ができる。
- Pandas を使って CSVファイル の読込みができる。
- Pandas を使って 表形式データ に対する初歩的な操作や処理ができる。
2 京都大学「プログラミング演習」の教科書
昨年度の「情報1」などで既に何度か紹介していますが、京都大学の全学共通科目である「プログラミング演習 (Python)」のテキスト (教科書) の 2023年度版 が公開されています。
皆さんでも十分に取り組めるものになっている (と思う) ので、ちょっと背伸びして読んでみて欲しいと思います。特に、本科目では余り触れていないコンピュータサイエンスの内容が充実しているのでおすすめです。
3 ラムダ式
ここでは「ラムダ式」というものについて学びます。ラムダ式は 無名関数 と呼ばれることもあります。
3.1 準備: 関数の定義と呼び出し (復習)
第11回講義で学んだように、Python では次のように 関数 (Function) を「定義」して、さらに「呼び出し (Call)」をすることができます。
%reset -f
# 自作関数 add の定義する
def add(a,b):
c = a+b
return c
x = 10
y = 20
z = add(x,y) # 自作関数 add の呼び出し (コール)
print(f'z => {z}') # z=> 30 このプログラムのでは、第04行目から第06行目にかけて
add
という名前の自作関数を「定義」し、引数
(ひきすう) として受け取った2つの値 a b
を加算して変数 c に格納し、それを
return c
で「戻り値」としています。ここで def
は Define (定義という意味) の略語になります。
つづいて 第10行目 では、変数 x と
y を 引数
として与えて自作関数 add を呼び出して、その 戻り値 を変数 z
に代入しています。
このプログラムを実行すると、次のような結果が得られます。
z => 30以上は、第11回講義の「復習」であり、以降の解説を理解する大前提になります (ここまでの内容が曖昧だと以降の説明を理解することはできません、第11回に戻って復習してください) 。
演習1: 関数の「定義」が「呼び出し」以降の行に記述されている場合、つまり、第04行~第06行の内容が、第10行目よりも後に記述されていた場合、どのような結果になるか予想してください。また、実際にコードを書き換えて結果を確認してください。
演習2: 関数 add を
add(10,20,30) あるいは add(10)
のように呼び出すと (つまり、引数の過不足がある状態で呼び出すと)
どのようになるか確認してください。
演習3: 関数 add
について、3個の引数を受け取り、それらを加算する処理に書き換えてください。
- たとえば
add(10,20,30)のように呼び出して、戻り値として60を得るようにaddの定義を書き換えてください。
3.2 関数における変数の省略
前のセクションにおいて、関数 add の定義
(第04行目から第06行目)
では、変数 c に計算結果を格納し、それを
return c
のようにして「戻り値」を明示しました。この処理は、次のように
変数 c
を作成せずに直接的に記述することができます。つまり return 変数 ではなく return 式
のように記述することができます。
3.3 関数を変数に代入する
関数は、次のように 変数に代入 (格納) して、そこから呼び出すこと ができます。
%reset -f
def add(a,b):
return a+b
sum_two_numbers = add # 関数 add を 変数 sum_two_numbers に代入
print(type(sum_two_numbers)) # => <class 'function'>
z = sum_two_numbers(10,20) # 注目!
print(f'z => {z}')第02行目~第03行目 で自作関数 add
を定義しています。つづいて 第05行目
では、この自作関数 add を変数
sum_two_numbers
に代入しています。代入の際は
「=add()」ではなく「=add」
のように記述している点に注意してください。もしも、括弧をつけて代入すると
「関数そのものを代入」ではなく「関数を実行した結果の戻り値を代入」
という意味になってしまいます。
そして、第07行目では、z=sum_two_numbers(10,20)
のように関数を呼び出しています。これは、関数 add に
sum_two_numbers
という「別名」を与えて、その別名で関数を呼び出していると捉えることもできます。無論、別名を与えた後も
z=add(10,20)
のようにオリジナルの名前で関数を呼び出すことは有効です。
このように Python では、数値や文字列と同様に、「関数」も変数に代入して利用することができます。これは、自作関数に限らず 各種ライブラリが提供する関数 についても同様です。
例えば、math
ライブラリには、引数に「弧度法のラジアン」を与えて「度数法の角度」を返す関数
math.degrees がありますが、以下のように、これに
r2d という省略命 (別名)
を与えて利用することができます (r2d は「Radians to
Degrees」の略です。関数名などで「to」の代わりに「2」を使うこと
がよくあるので覚えておいてください)。
%reset -f
import math
r2d = math.degrees # ここに注目!
print(f'pi/2 は {r2d(math.pi/2):.1f} 度です。')
print(f'pi/4 は {r2d(math.pi/4):.1f} 度です。')関数に別名を与える場合の注意事項
関数を変数に代入することは、つまり「関数に別名を与えること」であり、これは非常に便利です。例えば、p=print
のように記述することで、コードを劇的にシンプルにすることができます。しかし、この方法(標準関数やライブラリ関数に別名を与える方法)には注意が必要です。
クローズな個人開発では問題ありませんが、チームでの開発や他の人がコードを閲覧する可能性がある場合、別名の使用はプログラムの 可読性 や 移植性 に悪影響を与えます。特にチーム開発において、チーム内での合意がないままに利用すると、確実に注意と修正の指示をうけることになります。
また、変数に 格納 (代入) できるということは、次のように 「辞書型」や「リスト型」の要素にすることもできる
ということになります。以下のプログラムで calc
という変数は「Calculation (演算)」の略称として使用しています。
%reset -f
def add(a,b):
return a+b
def subtract(a,b):
return a-b
calc = {} # 空の辞書
calc['加算']=add # 関数を辞書の「値」として登録
calc['減算']=subtract # 〃
z1 = calc['加算'](10,20) # 辞書calcから関数を呼び出し
z2 = calc['減算'](10,20) # 〃
print(f'z1 => {z1}')
print(f'z2 => {z2}')演習
上記のプログラムに「乗算」をする関数
multiply を追加実装して、辞書型の変数
calc
に追加してください。また、それが問題なく呼び出せることも確認してください。
3.4 ラムダ式 (無名関数)
Pythonには ラムダ式 あるいは 無名関数 と呼ばれる概念・構文があります (これは Python 固有のものではなく最近のプログラミング言語にも一般的に備えられているものです)。この講義では主に「ラムダ式」という呼称を使用します。
ラムダ式は、関数定義の構文のひとつで 名前を持たない一時的な関数を定義
するための構文です。lambda
キーワードを使用して定義され、主に「短い処理の関数」や「関数を引数として渡す場合」に使用されます。ラムダ式には名前を付ける必要がなく
(=適切な関数名を考えることに悩まされることなく)
1行 (ワンライナー)
で記述できるため、実務的なコードでは頻繁に使用されます。
ラムダ式を使うと、先ほどのプログラムは次のように記述することができます。ここでは
add や subtract 、multiply
などの名前付けた関数定義が不要な点に着目してください。calc['XX']=
という代入部分 (右辺)
で関数を定義しています。
%reset -f
calc = {}
calc['加算']= lambda a,b : a + b
calc['減算']= lambda a,b : a - b
calc['乗算']= lambda a,b : a * b
z1 = calc['加算'](10,20)
z2 = calc['減算'](10,20)
z3 = calc['乗算'](10,20)
print(f'z1 => {z1}, z2 => {z2}, z3 => {z3}')Pythonのラムダ式には 1個の式しか記述できないこと に注意してください。つまり、複数行を必要とする処理をラムダ式として記述することはできません (そのような場合は、通常の関数定義を使用します)。一方で、C# や JavaScript などの言語では、ラムダ式 (JSの場合は「アロー関数」と呼称) に複数の文を含むことができます。
3.5 ラムダ式の記述法
「通常の関数定義
func-lambda-01.py」と「ラムダ式による関数定義
func-lambda-02.py」について相互変換 (相互書き換え)
ができるようになっておいてください
(構文の違いについて理解しておいてください)。
通常の関数もラムダ式も、定義した後の「型」や「呼び出し方法」は同じです。
演習 add = lambda a,b : a+b を
add = lambda (a,b) : a+b
のように書き換えるとどのようになるか確認してください。
4 mapとラムダ式の組み合わせ
ラムダ式は、一般に map 関数、filter
関数、sorted 関数、functools.reduce
関数などと組み合わせて使用することが多いです。ここでは、最も利用頻度が高いと思われる
map 関数との組み合わせについて紹介しておきます。
4.1 map関数
Pythonの組み込み関数である map は リストやタプルを構成する個々の要素に任意の関数を適用
する機能を提供します。
例えば、次のように「文字列」を要素に持つリスト
arr1 があるとします。
実行結果は次のようになります。<class 'str'>
と出力されることからも、['10',...
のように要素がシングルクォーテーションで囲まれて出力されることからも、arr1
の要素は「文字列型」であることが確認できます。
<class 'str'>
['10', '20', '30', '40']次に、そして、この arr1 の各要素に対して
int() 関数を適用して「(文字列を)
整数値に変換したい」とします (a=int('100') のようにすれば、変数
a には整数型の100
が得られることは学習済みです)。このようにしたいときは、次のように
map 関数を活用します。
%reset -f
arr1=['10','20','30','40']
# print(type(arr1[0])) # => <class 'str'>
# print(arr1)
# map を適用
arr2 = map(int, arr1)
print(type(arr2)) # => <class 'map'>
# map型をリスト型に変換
arr2 = list(arr2)
print(type(arr2)) # => <class 'list'>
print(type(arr2[0])) # => <class 'int'>
print(arr2)実行結果は次のようになります。
<class 'map'>
<class 'list'>
<class 'int'>
[10, 20, 30, 40]以上の結果から、最終的に arr2 には
[10, 20, 30, 40]
のように整数型を要素に持つリストが得られていることが分かります。また、第07行目と第11行目はまとめて
arr2 = list(map(int,arr1))
のように1行で書くこともできます
(基本的には1行で書くことが多いです)。
ここでは、map 関数を使うことで for
などの繰り返し構文を使用せずに簡潔に処理が書けていること
に注目してください。もし、for
を使用して同じ処理を実行する場合は、以下のようになります。
%reset -f
arr1=['10','20','30','40']
# for を適用
arr2 = []
for a in arr1:
arr2.append(int(a))
print(arr2)両者を比較すると map
を使ったほうがシンプルに記述できることが分かります。そのため、実務プログラムでも
map が多用されます。map
を使ったプログラムも読めるようになっておいてください。
なお、タプル型で結果を得たい場合は、arr2 = tuple(map(int,arr1))
のようにします。
4.2 mapと自作関数の組合せ
先の例では arr2 = list(map(int,arr1))
のように標準関数である int と map
を組み合わせました。しかし、map
には標準関数以外にも、次のように自作関数を組み合わせることができます。
次のプログラムは、文字列として数値が格納されるリストを対象に、整数型に変換して、さらに値を2倍にする処理を行ないます。実際にプログラムを実行して結果を確認してください。
%reset -f
# 値を2倍にする関数
def double(a):
return a*2
arr = ['10','20','30','40']
arr = list(map(int, arr)) # 標準関数 int を適用し...
arr = list(map(double,arr)) # 自作関数 double を適用
print(arr) # => [20, 40, 60, 80]4.3 mapとラムダ式の組合せ
先の例では、自作関数 double を定義して
map の第1引数に与えましたが、次のように ラムダ式を直接与えること
ができます。実際に上記のプログラムを実行して結果を確認してください。
%reset -f
arr = ['10','20','30','40']
arr = list(map(int, arr))
arr = list(map( lambda a : 2*a, arr))
print(arr) # => [20, 40, 60, 80]このプログラムは 第03行目 と 第04行目 をまとめて次のように書くこともできます。
%reset -f
arr = ['10','20','30','40']
arr = list(map( lambda a : int(a)*2, arr))
print(arr) # => [20, 40, 60, 80]なお、map
を使わずに記述すると、次のような繰返し構文を含むプログラムとなります。
%reset -f
arr = ['10','20','30','40']
for i in range(len(arr)):
arr[i] = int(arr[i])*2
print(arr) # => [20, 40, 60, 80]4.4 三項演算子とラムダ式
いま、「何らかの計測実験で電流」を測定したとします。本来、その実験では電流は「非負の値」となるはずですが、ノイズの影響で稀にマイナスの値も計測されてしまうという問題があります。このため、マイナスの計測値は全て「0.0」に書き換えたいという要求があるとします。
このような処理は、自作関数と map
関数を組み合わせで実現できます。プログラムを実行して、意図した結果が得られるか確認してください。
%reset -f
def clip_negative(a):
if a >= 0:
return a
else :
return 0.0
arr = [2.3, 0.2, -1.9, 1.8]
arr = list(map(clip_negative,arr))
print(arr) # => [2.3, 0.2, 0.0, 1.8]この処理を「ラムダ式」を使って記述することを考えます。しかし、既に述べたように
Python のラムダ式は 1つの式しか含めることができず、複数行にわたる文を含むこと
はできません。上記の clip_negative
関数は条件分岐を含み、複数の文から構成されており、そのままラムダ式として記述することはできません。
このようなとき、条件式(三項演算子) を使用することでラムダ式にできる場合があります。
4.5 条件式 (三項演算子)
条件式 (三項演算子)
は、a = [真のときの値] if [条件] else [偽のときの値]
という形式で記述します。そして、次のように動作します。
[条件]を評価します。- 評価が
Trueであれば[真のときの値]が返され変数aに代入されます。 - 評価が
Falseであれば[偽のときの値]が返され変数aに代入されます。
具体的な記述を見たほうが分かりやすいです。既に学習済みですが
%
は割った「余り」を求める演算子です。つまり、dice%2==0
は 2で割ったときの余りは 0 であるか?
の意味になります。次のプログラムを実行して動作を確認してください。
%reset -f
import random as r
dice = r.randint(1,6) # 1~6の整数乱数
a = '丁(偶数)' if dice%2==0 else '半(奇数)' # 条件式 (三項演算子)
print(f'賽の目 {dice} で {a} です')この条件式を使えば、先ほどのプログラム (リストに含まれる負の値を 0.0 にする) は次のように記述することができます。
%reset -f
def clip_negative(a):
b = a if a >= 0 else 0.0 # 条件式 (三項演算子) で記述
return b
arr = [2.3, 0.2, -1.9, 1.8]
arr = list(map(clip_negative,arr))
print(arr)さらに、関数 clip_negative の変数 b
を省略して次のように記述できます。
%reset -f
def clip_negative(a):
return a if a >= 0 else 0.0 # 注目
arr = [2.3, 0.2, -1.9, 1.8]
arr = list(map(clip_negative,arr))
print(arr)ここまでくれば、関数 clip_negative
をラムダ式で記述できることに気付いたと思います。条件式
(三項演算子) を含むラムダ式と map
関数の組み合わせたプログラムを次に示します。実行して動作を確認してください。
%reset -f
arr = [2.3, 0.2, -1.9, 1.8]
arr = list(map( lambda a : a if a >= 0 else 0.0, arr)) # 注目
print(arr)条件式 (三項演算子) を使用すると可読性は犠牲になるもののプログラムを劇的に短くすることができます。
標準関数 max
標準関数の max
を使用すると上記の処理はよりシンプルに記述できます。max
は与えられた引数のうち、大きいほうの値を返す標準関数
(インポート不要) です。例えば a = ( -1.2, 0.0 )
とした場合は、変数 a には 0.0
が格納されます。
max
関数には「3つ以上の引数を与えること」や「リスト形式で1個の引数を与えること」もできます。同様に、引数のうちもっとも小さい値を返す
min 関数もあります。
演習: arr1
には100点満点の「成績」が格納されている。60点未満を「不合格」、60点以上を「合格」として
第04行目
ような値が得られるようにプログラムを記述してください。
%reset -f
arr1 = [60, 70, 45, 55, 90]
arr2 = 0 # ここを書き換え
print(arr2) # => ['合格', '合格', '不合格', '不合格', '合格']なお、次のような解答は期待していません (ここでは
map、ラムダ式、条件式を使用することを期待しています)
。
%reset -f
arr1 = [60, 70, 45, 55, 90]
arr2 = []
for a in arr1:
if a >= 60:
arr2.append('合格')
else:
arr2.append('不合格')
print(arr2) # => ['合格', '合格', '不合格', '不合格', '合格']5 Pandas入門
前回講義 で学習したように Pandas (パンダス) は「表形式データ」の操作や処理を得意とするライブラリ (モジュール) です。CSV/Excelをはじめとした様々な表形式データの読込みや書出し、表形式データの操作や処理を効率的かつ高速に実行する機能を提供します。
また、Pandas は、Pythonを使った データ分析 や 機械学習 (マシンラーニング) の 前処理 のための「定番ツール」であり、多くの場合、数値計算ライブラリ「NumPy」と可視化ライブラリ「Matplotlib」と組み合わせて使用されます。特に「データサイエンティスト」や「AIエンジニア」にとって Pandas はほぼ必須ツールになります。
データサイエンティスト・AIエンジニア
データサイエンティスト、AIエンジニアの「業務内容や将来性」「年収」「適性 (向いている人)」「関連資格」などは、下記を参考にしてください。なお、高専卒業後に大学編入して大学院までに進むことで、これらの職に就ける可能性が高くなります (チャンスや機会に恵まれるようになります)。
- データサイエンティスト @ キャリアガーデン
- https://careergarden.jp/ai-engineer/
- AIエンジニア @ キャリアガーデン
- https://careergarden.jp/data-scientist/
5.1 CSVファイルの読込み
前回講義でも体験したように
Pandas ライブラリを使用すると CSVファイル のデータを
DataFrame
型として、プログラムのなかに簡単に取り込むことができました。
以下に score-1.csv
を「DataFrame型」として読込み、その内容を表示するプログラムを示します。なお、ウェブからのファイルダウンロードに使用する
requests ライブラリは、Pythonの標準ライブラリ
(モジュール) ではありません。そのため、実行時に ModuleNotFoundError: No module named 'requests'
が生じたら pip install requests
で当該ライブラリをインストールしてください
(GoogleColab環境ではデフォルトでインストールされています)。
import os
import requests # ウェブからファイルをダウンロードする際に利用
import pandas as pd
# CSVファイルをウェブから取得してカレントフォルダに保存
url = 'https://takeshiwada1980.github.io/Programming1-2025/data/19/score-1.csv'
res = requests.get(url)
# print(type(res)) # => <class 'requests.models.Response'>
if res.status_code != 200:
raise Exception(f'ファイルのDLに失敗。強制終了します。Code:{res.status_code}')
fn = 'score-1.csv'
with open(fn,'wb') as file:
file.write(res.content)
# CSVファイルの読込み
assert os.path.isfile(fn)
df = pd.read_csv(fn,encoding='utf-8')
# print(type(df)) # => <class 'pandas.core.frame.DataFrame'>
# データフレームの整形出力
display(df)第03行目では、Pandas ライブラリ (モジュール) をインポートしています。慣例的に Pandas は
pdという省略名で使用します。インポートの際はpandasのように小文字で表記することに注意してください。第07行目 では、指定したURLに「HTTP GET リクエスト」を送り、その結果 (レスポンス) を変数
resに格納しています。resという変数名は response (応答) の略語としてよく利用されます。変数resはrequests.models.Response型のオブジェクトになります。第10行目~第11行目 では、変数
resのHTTPステータスコードを確認しています。ステータスコードは「3桁の数字」から構成され200は「OK」を意味します。ここでは200以外のステータスコードが返ってきた場合には「エラー」としてプログラムを強制終了するようにしています。raise Exception(...)は、この強制終了に関連した 例外処理 というものに関連する命令です (詳しくは今後の講義で扱います)。- ステータスコードとして知っておいてほしいものとしては
404の「Not Found」、401の「Unauthorized」、501の「Internal Server Error」などがあります。
- ステータスコードとして知っておいてほしいものとしては
第13行目~第15行目 では、
score-1.csvという名前でファイルを バイナリ書き込みモード (wbモード) でオープン (新規作成) して、ウェブから取得した内容 (res.content) を書き込んでいます。実行後、以下の図のようにColabのカレントフォルダにscore-1.csvが出力されていることを確認できます。
第19行目 では、Pandas の
read_csv関数を使って「CSVファイル」を読み込み、DataFrameオブジェクトとして変数dfに格納しています (慣例的に Pandas のサンプルコードでは、DataFrameオブジェクトにdfという変数名をつけます)。なお、CSVファイルに「日本語」が含まれ、その文字コードが ShiftJIS の場合は、引数にencoding='cp932'を指定します。第23行目 では、
dfの内容を整形して表示しています。このdisplay関数は、Jupyter や GoogleColab で有効です。それ以外の Python 環境ではprint(df)を使用してください。
上記のプログラムを実行して動作を確認してください。
演習1: display(df) を
print(df) に書き換えて動作を確認してください。
演習2: 第19行目 で
encoding='cp932'
のように引数を指定するとどのようなるか確認してください。
5.2 型の確認
DataFrameオブジェクトでは「列単位」で型 (type)
が統一されます。通常、型はファイル読み込み時に最適なものが自動設定されます。各列の「型」は、次のように
DataFrameオブジェクトの dtypes
プロパティ を使って確認できます。
%reset -f
import pandas as pd
fn = 'score-1.csv'
df = pd.read_csv(fn,encoding='utf-8') # 'score-1.csv' を読み込み
print(df.dtypes)実行結果は次のようになるはずです
(実際に実行して確認してください) 。最終行の
dtype: object は無視して構いません。
ID int64
氏名 object
性別 object
国語 int64
数学 object
英語 int64
理科 int64
社会 float64
備考 object
dtype: object列の要素に「文字列」が含まれる場合、型は
object
になります。列のうち「氏名」「性別」「備考」に加えて
「欠」という文字列を含む「数学」 も
object となっています。object
に対しては、算術演算や、合計・平均などの統計処理ができません。
また、列要素のすべてが「整数」に変換できる場合、型は
int64
になります。これは「64ビットの整数型」を意味しており
\(-2^{63}\) から \(2^{63}-1\)
までの整数値を扱うことができます。なお、\(2^{63}-1\) は 9,223,372,036,854,775,807 となります。
列要素に「実数値 (小数)」を含む場合、型は
float64
になります。「社会」の列には「洞木 ヒカリ」の成績
90.5 を含むため float64 となります
(繰返しになりますが、列内に整数型と浮動小数点数型を混在させること
はできません)。型が float64 の場合、整数値であっても
90.0 のように小数部のついた表示となります。
DataFrameに対して、各種操作 (列同士の計算などを含む) をするためには、不適切な値の修正をして、型を統一しておく必要があります。これらの処理を 前処理 (Preprocessing) と言います。
5.3 準備: インデックスの設定
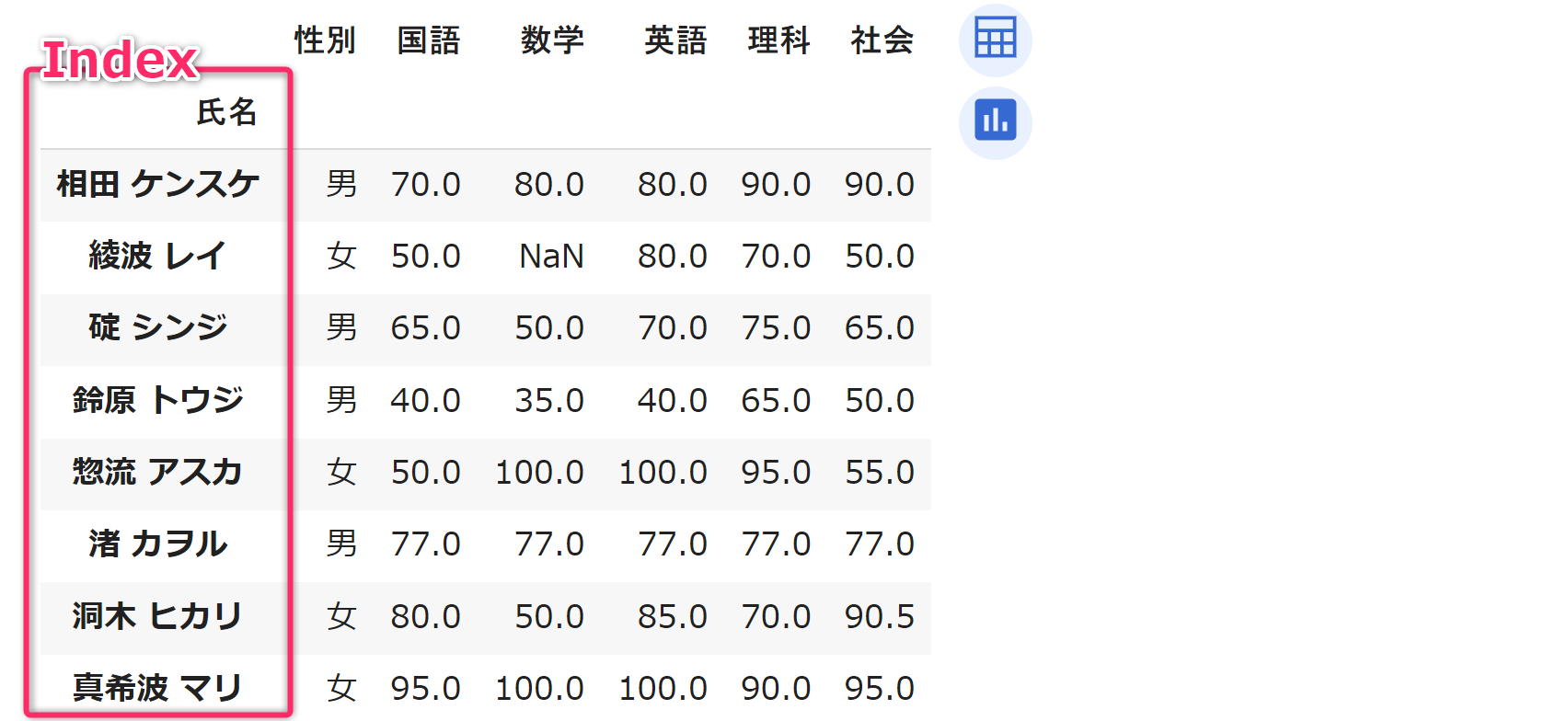
Pandas における インデックス (index) とは「行」を特定するためのラベルです。現時点ではインデックスとして 0 から 7 が自動的に設定されています。例えば、値を修正する場合には、この「インデックス」と「列名」を用いて位置を特定します。そのため、分かりやすい値をインデックスとして設定しておくことが推奨されます。
現在の「インデックス」は「ID」とも値がずれており、分かりづらい (混乱しやすい) ものとなっています。以降の作業のために「氏名」をインデックスに設定していきたいと思います。
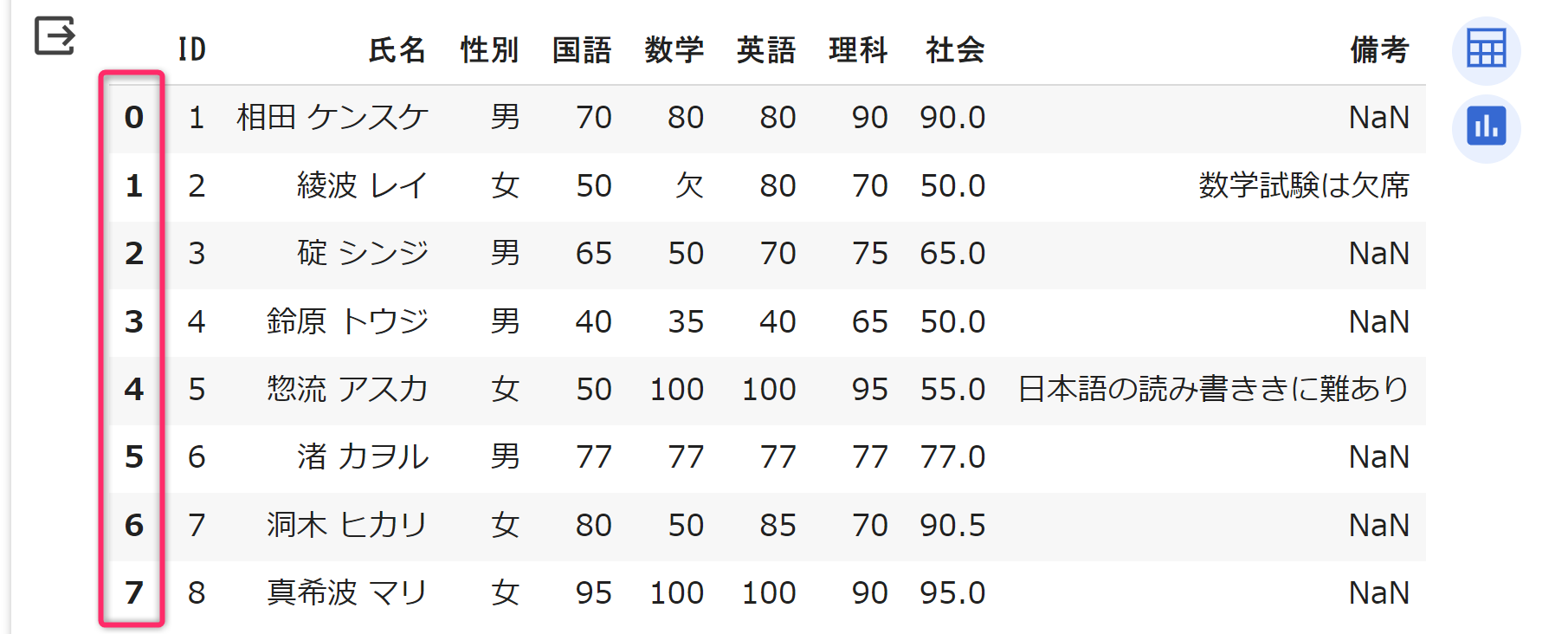
次のプログラムの 第06行目
のようにDataFrameオブジェクトの set_index
メソッドを使って
任意の「列」をインデックスに置き換えることができます。
%reset -f
import pandas as pd
fn = 'score-1.csv'
df = pd.read_csv(fn,encoding='utf-8')
df.set_index('氏名',inplace=True) # 列「氏名」をインデックスに設定
display(df)実行結果は次のようになります。「氏名」がインデックスになりました。なお、第06行目は
df = df.set_index('氏名')
のように記述することもできます。
演習1: 第06行目 を
df.set_index('氏名')
に書き換えるとどのようになるか確認してください。
演習2: 第06行目 を
df = df.set_index('氏名')
に書き換えるとどのようになるか確認してください。
演習3: 第06行目 を
df = df.set_index('氏名',inplace=True)
に書き換えるとどのようになるか確認してください。
inplaceオプション
DataFrameオブジェクト のメソッドには set_index
の他に inplace
オプションを指定できるものがいくつか存在します。基本的には
inplace=False
がデフォルトであり、オプションを明示的に指定しない場合は、これ
(inplace=False) が適用されます。
inplace=True を指定せず
df.set_index('氏名')
とすると、変更を加えた新しい DataFrame
オブジェクトが生成され、それが戻り値として返されます。このとき、元々の
DataFrameオブジェクト である df
には変更は加えられません。変更後の DataFrame
オブジェクトを使用するためには
df2 = df.set_index('氏名') のように新しい変数 (例えば
df2 など)
に割り当てるか、df = df.set_index('氏名') のように
元の変数に上書きする必要 があります。
一方で、inplace=True を指定すると、元々の
DataFrame オブジェクト df を
直接変更 します。つまり、set_index
メソッドは「戻り値」を返さず (何もないことを意味する
None を戻り値として返して)、元の df
が変更されます。
5.4 前処理: 欠損値の設定
「綾波 レイ」の「数学」の成績は、現状で「文字列」の「欠」となっています。「欠」という文字列は、人間から見れば「(欠席によって) 成績が存在しない」ということが分かりますが、コンピュータ (=Pandasライブラリ) にはそのようには認識されません。
一般に「欠」や「-」「空白」のような記号で表記される
欠損値 (Missing Data) は、Pandas では NumPy の
np.nan
を使って与えます。また、そのように与えられた欠損値は、整形出力された表では「NaN
(Not a Number)」のように表示されます。
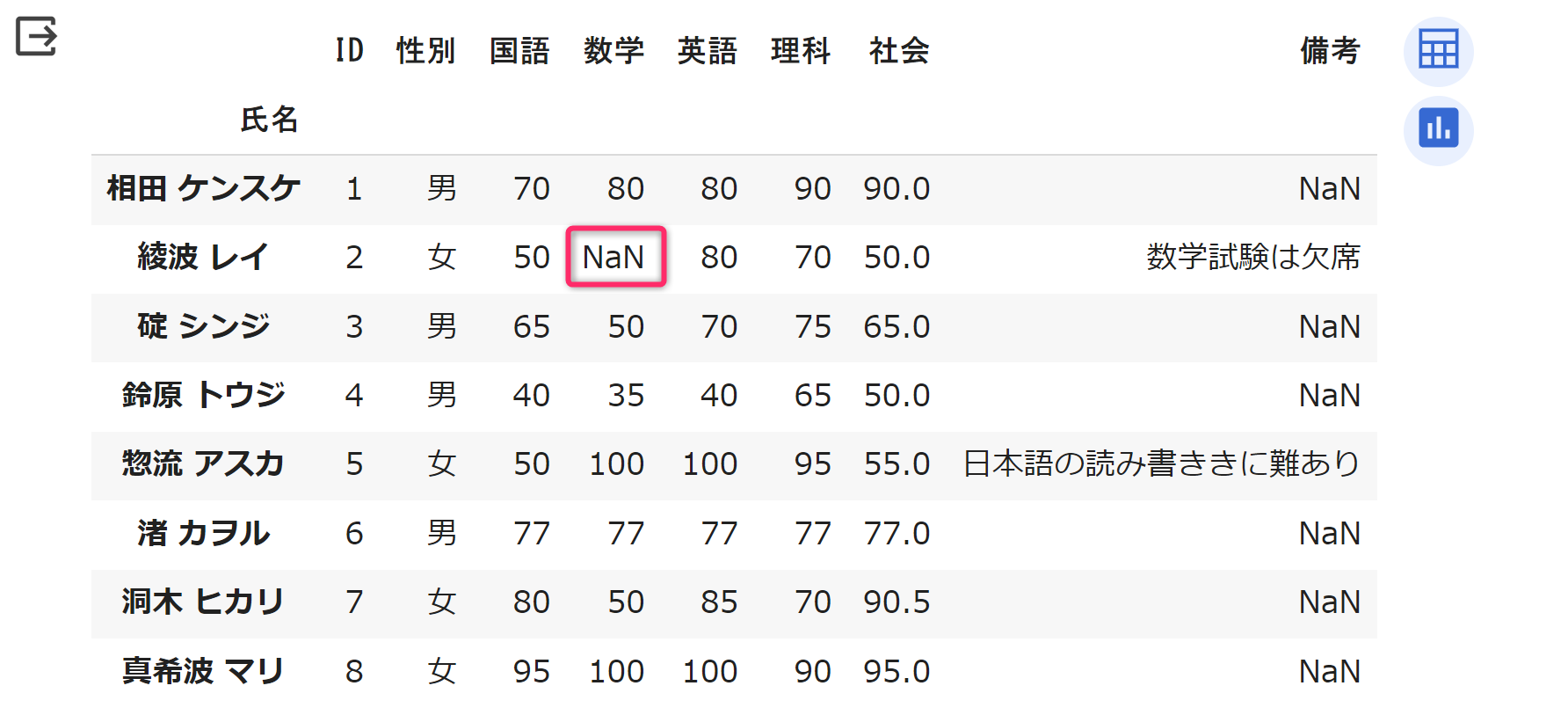
次のプログラムは、「綾波
レイ」の「数学」の成績を「欠」という文字列から、NaN
(=np.nan) へと書き換える例です。DataFrame
オブジェクトは df.loc['綾波 レイ','数学'] のように
df.loc[インデックス名,列名]
で値の参照/書き換えができます。
%reset -f
import pandas as pd
import numpy as np # 要インポート
fn = 'score-1.csv'
df = pd.read_csv(fn,encoding='utf-8')
df.set_index('氏名',inplace=True)
df.loc['綾波 レイ','数学'] = np.nan # インデックスと列名で位置を指定して値を変更
display(df)実行結果は次のようになります。「欠」であったものが「NaN」に変わっていることが確認できます。
なお、DataFrame
内に「欠」が多数存在する場合、上記の
df.loc['綾波 レイ','数学'] = np.nan
のように1個1個の位置を指定することは非常に面倒です。そのような場合は
df.replace('欠', np.nan, inplace=True)
のようにして一括処理ができます。Replaceは「置き換える」の意味です。
演習1: 第08行目 を
df.replace('欠', np.nan, inplace=True)
に書き換え、その結果について確認してください。
演習2:「洞木 ヒカリ」の「理科」の成績を
75 に修正してください。解答例 df.loc['洞木 ヒカリ','理科'] = 75。
5.5 前処理: 型の変換
現状で「国語」「英語」「理科」の型は
int64、「社会」の型は
float64、「理科」の型は object
のようにバラバラです。この状態では「5科目の合計点」などを適切に求めることができません。そのため、これらの列の「型」を全て
float64 に変換します。なお、これらは 成績 (得点)
なので int64 のほうが適切ですが int64 では NaN
を扱えない ため、float64 に変換します。
型の変換には astype メソッドを利用します
(astype には inplace
オプションはありません)。また、以降の処理で「ID」と「備考」の列は不要なので、ここで削除
(Drop) もしておきます。
%reset -f
import pandas as pd
import numpy as np
fn = 'score-1.csv'
df = pd.read_csv(fn,encoding='utf-8')
df.set_index('氏名',inplace=True)
df.loc['綾波 レイ','数学'] = np.nan
# 列の型変換
df['国語'] = df['国語'].astype(float) # int64 -> float64
df['数学'] = df['数学'].astype(float) # object -> float64
df['英語'] = df['英語'].astype(float) # int64 -> float64
df['理科'] = df['理科'].astype(float) # 〃
# 不要列の削除
df.drop(['ID','備考'], axis='columns', inplace=True)
print(df.dtypes) # 各列の型確認
display(df) # 内容確認
df.to_csv('score-2.csv') # 保存上記の実行結果は次のようになります。「ID」と「備考」の列が削除され、各科目の成績をあらわす列の型が
float64
になっていることが確認できます。第17行目 での
不要列の削除 では axis='columns'
を指定していますが、これを指定しないと 「列」ではなく、「ID」や「備考」というインデックスの「行」を削除しようと
するため注意してください。
また、第21行目 では、DataFrameオブジェクト の
to_csv メソッドを使って、前処理した内容を
score-2.csv として保存しています。カレントフォルダに
CSVファイル が生成されていることも確認てください。
性別 object
国語 float64
数学 float64
英語 float64
理科 float64
社会 float64
dtype: object複数の列をまとめて型変換
次のようにリストを使って、複数の列について同時に「型変換」をすることができます。
5.6 要約統計量の確認
Pandas の機能を使って「データ概要」を把握してみます。
まずは、前処理後に保存したデータ
(score-2.csv)
を再読み込みして、そのデータの「型」と「内容」について念のために確認します。次のプログラムの
第04行目 のように index_col
を指定すると 指定した列がインデックスとして使用される
ようになります。
%reset -f
import pandas as pd
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
print(df.dtypes)
display(df)実行すると、各列の型情報とともに、次のように「氏名」がインデックスに設定された DataFrameオブジェクト の内容が確認できるはずです。
これらについて、基本的な「要約統計量」を計算して出力させてみます。これには、DataFrameオブジェクトの
describe メソッドを使用します。
%reset -f
import pandas as pd
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
display(df.describe()) # 要約統計量の表示実行結果は次のようになります。なお、デフォルトでは小数点以下の表示桁数が大きく見づらいため、必要に応じて
第05行目 を
display(df.describe().round(1))
のように書き換えてください。.round(1)
メソッドで、小数部が1桁になるような丸め処理がされます。
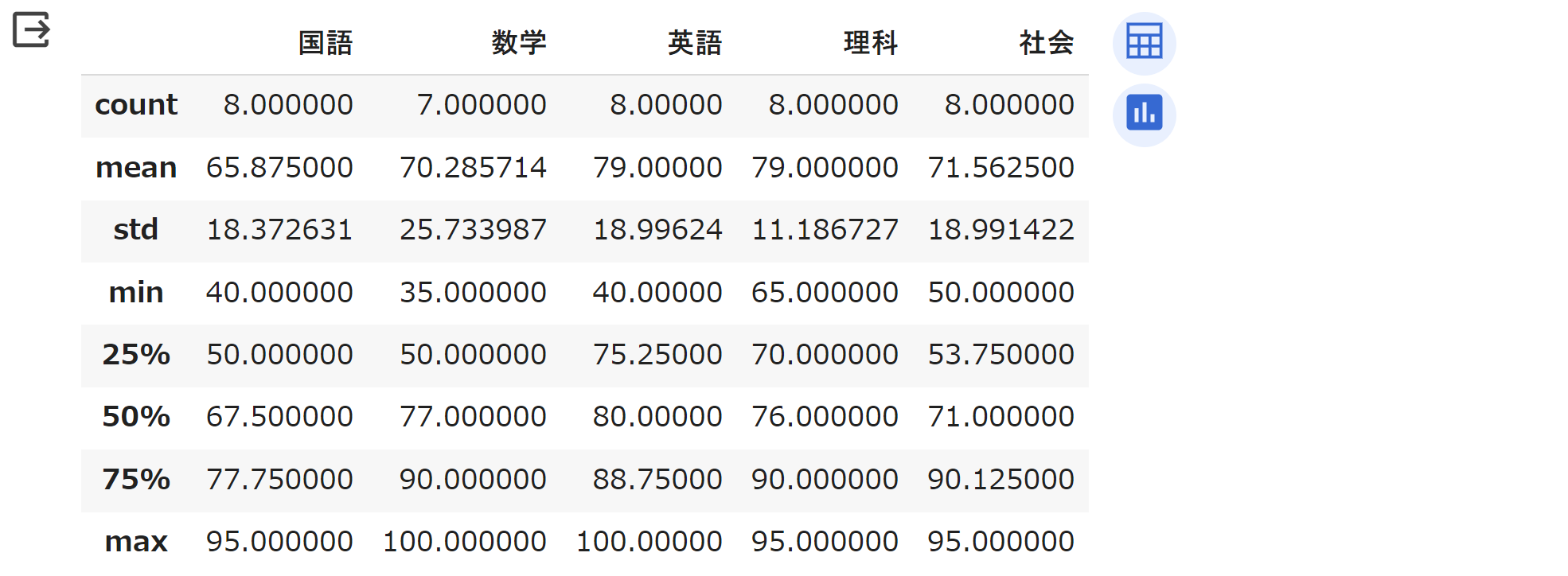
各行の項目は、次のような意味となります。
- count - データの個数
(
NaNを含めない個数) - mean - 算術平均
- std - 標準偏差(データの「ばらつき」の度合い)
- min - 最小値
- 25% - 第1四分位数 (データを小さい方から並べたときの 25% 地点の値)
- 50% - 中央値(メディアン)、第2四分位数
- 75% - 第3四分位数 (データを小さい方から並べたときの 75% 地点の値)
- max - 最大値
mean (平均値計算) などでは NaN
が除外されていることが確認できると思います。
5.7 簡易グラフ出力
DataFrameオブジェクト は 内部的に Matplotlib を呼び出して簡易的なグラフを描画する機能を持っています。ただし、DataFrame オブジェクトに「日本語テキスト」を含むときは、グラフに日本語を表示するためにjapanize-matplotlibをインポートする必要があります。
ModuleNotFoundError: No module named 'japanize_matplotlib'
が発生する場合は、次のように japanize-matplotlib を pip
でインストールしてください。
!pip install japanize_matplotlibGoogleColab環境では、独立したコードセルで
!
を先頭に付けて、ライブラリのインストールができます。
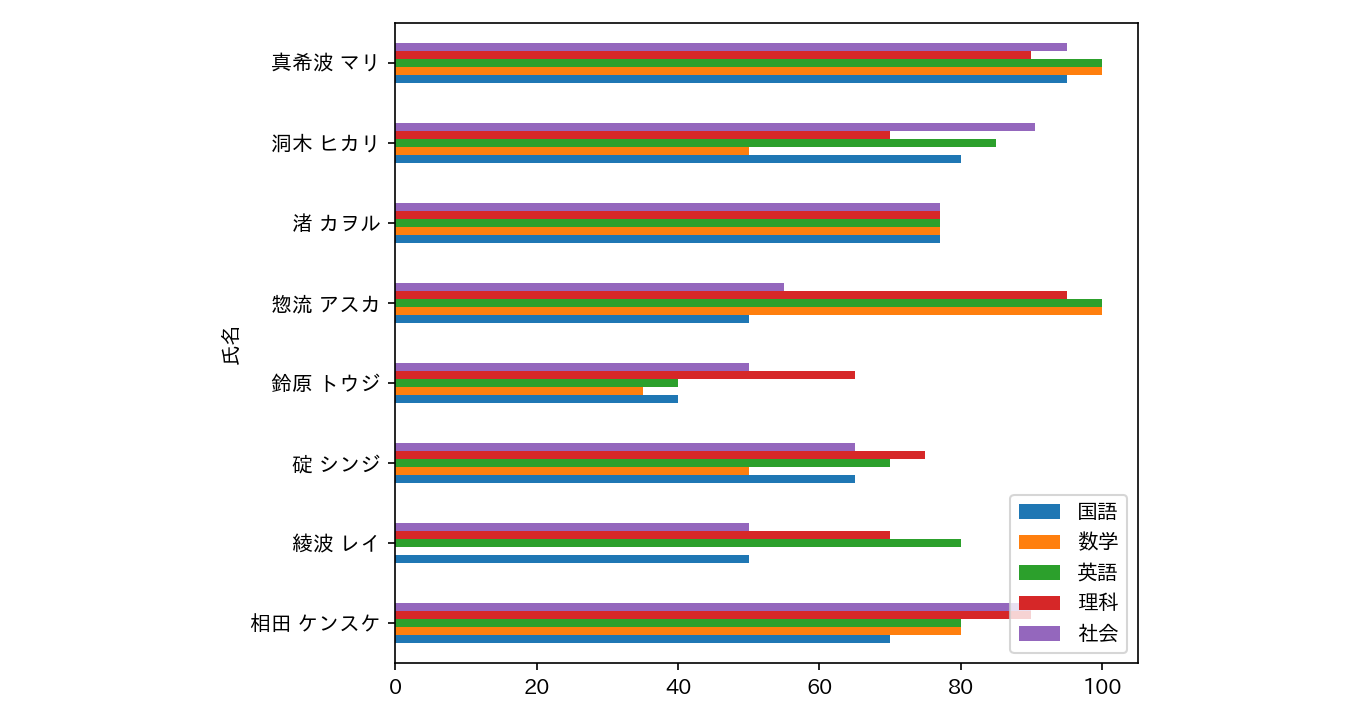
次のように df.plot.barh()
メソッドにより、簡易的な棒グラフを描画することができます。
%reset -f
import pandas as pd
import japanize_matplotlib # 日本語対応
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
df.plot.barh() # 水平の棒グラフ (簡易)実行すると次のようなグラフが出力されます。
また、第06行目 を df.plot.box()
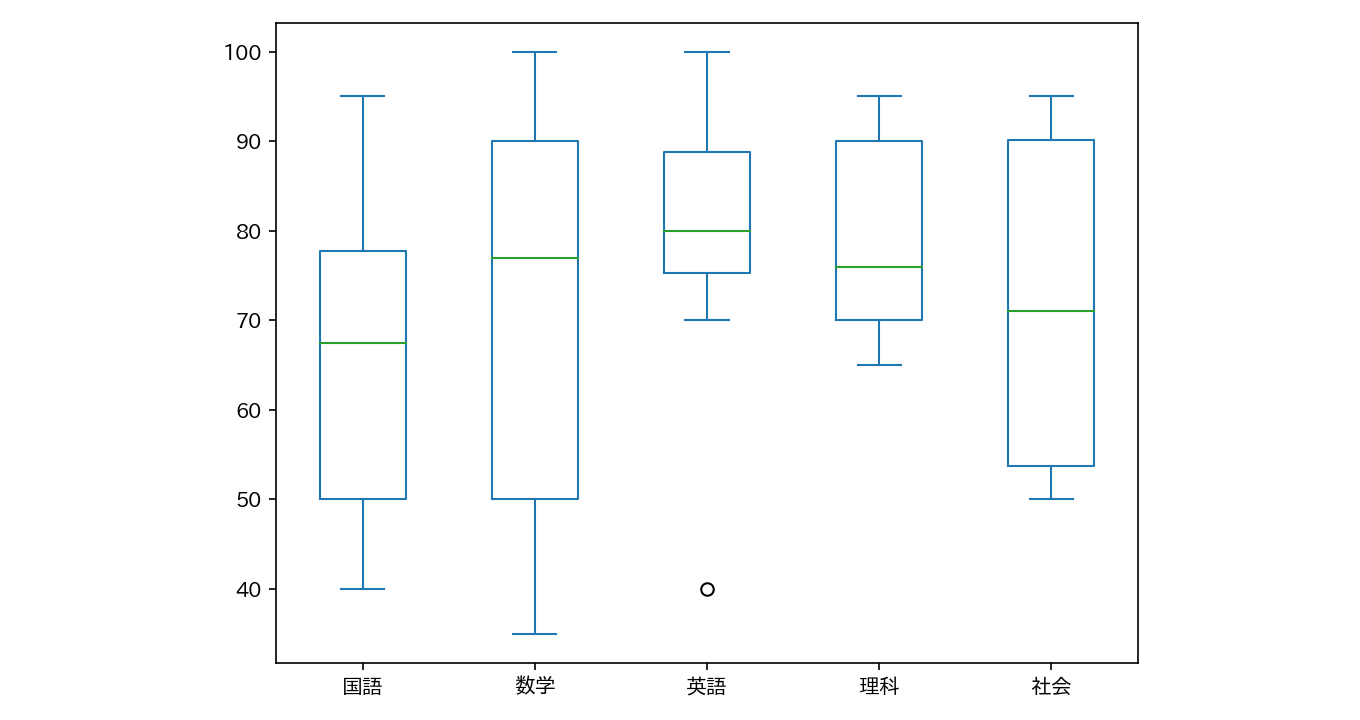
にすると、次のような 箱ひげ図 (ボックスプロット)
を描画することができます。英語の「〇」印は 外れ値
を表します。なお、箱ひげ図の読み取り方法は、「情報1」の第11回講義で学習済みです。
演習 import japanize_matplotlib
をコメントアウトしてプログラムを実行するとどのようになるか確認してください。
美しく体裁を整えたグラフを描画するためには…
DataFrameオブジェクトの plot.xxxx()
メソッドでは、Pandas の内部で Matplotlib
が呼び出されグラフが描画されます。ごく簡単にグラフを描画できますが、その体裁について細かな設定や調整をしたい場合は、次のように
Matplotlib 側から DataFrame
オブジェクトを参照 してグラフを描画する必要があります。
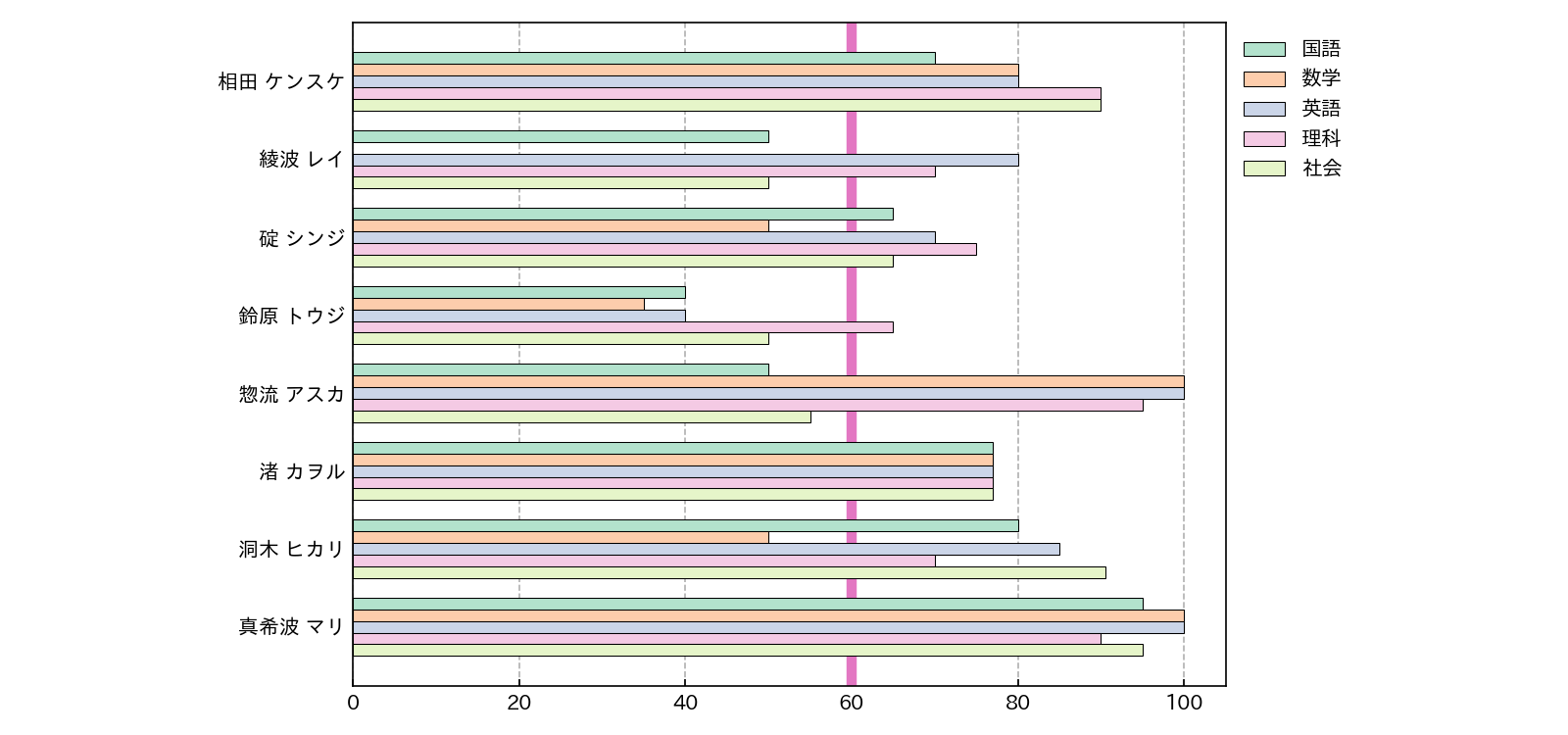
%reset -f
import numpy as np
import pandas as pd
import japanize_matplotlib
import matplotlib.pyplot as plt
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
n = len(df)
w = 1.2
cmap = plt.get_cmap('Pastel2')
fig,ax = plt.subplots(dpi=120,figsize=(8,5))
ax.axvline(60,c='tab:pink',lw=5,zorder=1)
for i,subject in enumerate(['国語','数学','英語','理科','社会']):
ax.barh( np.arange(n)+(w*i/n)-w*2/n, df[subject].values, height=w/n,
label=subject, color = cmap(i),edgecolor='black',linewidth=0.5)
ax.set_yticks(np.arange(n),df.index)
ax.invert_yaxis()
ax.tick_params(axis='y',length=0)
ax.tick_params(axis='x',direction='in')
ax.legend(loc='upper left', bbox_to_anchor=(1,1), frameon=False)
ax.grid(axis='x',ls='--')
ax.set_axisbelow(True)
plt.tight_layout()
plt.savefig('df-chart-03.png',dpi=150)
plt.show()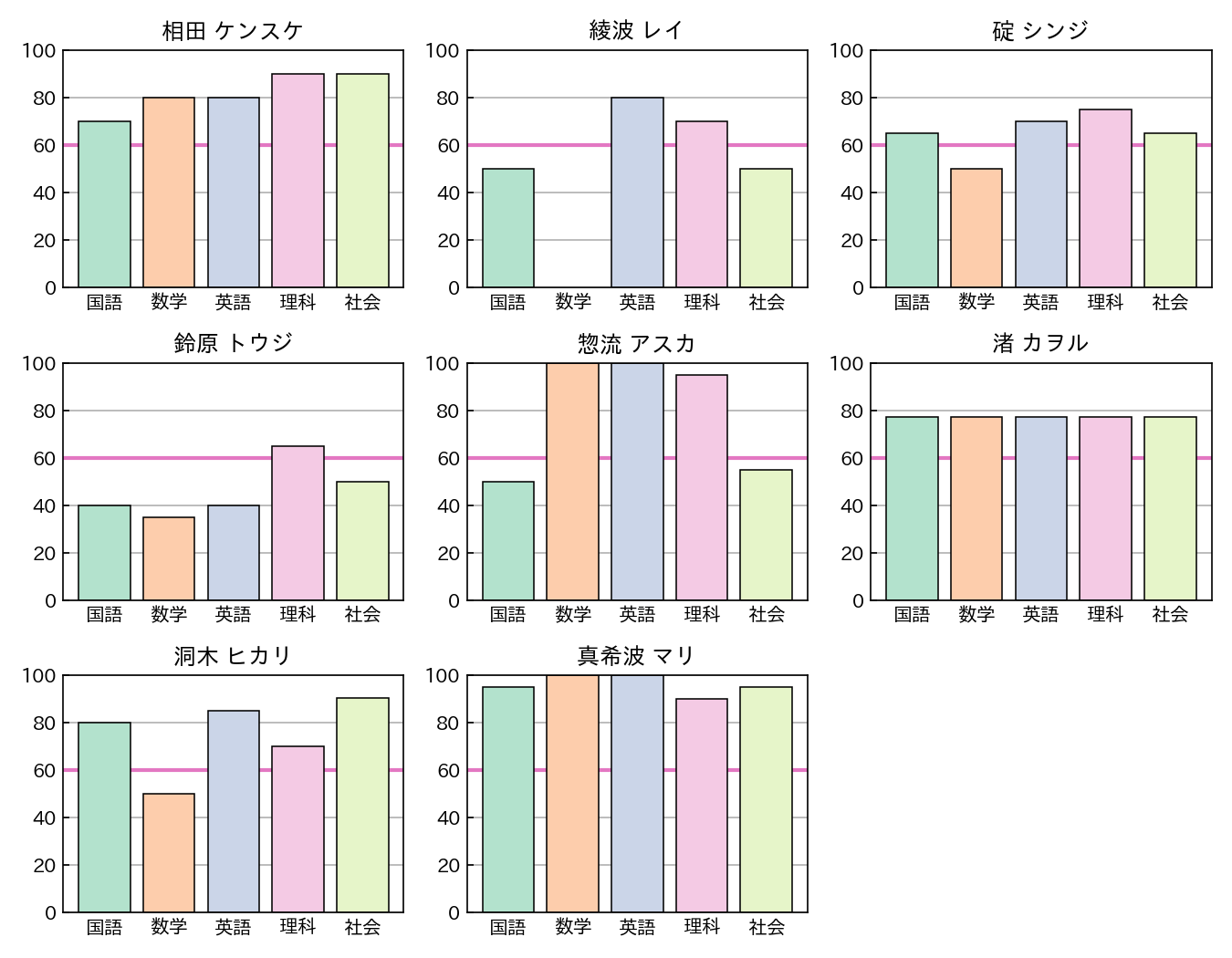
%reset -f
import numpy as np
import pandas as pd
import japanize_matplotlib
import matplotlib.pyplot as plt
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
fig,axis = plt.subplots(dpi=120,figsize=(9,7),ncols=3,nrows=3)
for i,ax in enumerate(axis.flatten()):
if i < len(df) :
ax.axhline(60,lw=2,c='tab:pink',zorder=1)
ax.bar(df.columns[1:],df.iloc[i][1:], edgecolor='black',
linewidth=0.75, color=plt.get_cmap('Pastel2').colors)
ax.tick_params(axis='x',length=0)
ax.tick_params(axis='y',direction='in')
ax.set_ylim(0,100)
ax.set_yticks(range(0,101,20))
ax.grid(axis='y')
ax.set_axisbelow(True)
ax.set_title(df.index[i])
else :
ax.axis('off')
plt.tight_layout()
plt.savefig('df-chart-04.png',dpi=150)
plt.show()5.8 DataFrameのサブセットの取得
DataFrame から特定の列や行を選択して作成されるオブジェクトを (DataFrameの) サブセットと言います (サブセットとは数学の用語で「部分集合」を意味します)。
例えば、性別と理系科目の列だけを選択したサブセット
df2 は、次のように作成できます。
%reset -f
import pandas as pd
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
df2 = df[['性別','数学','理科']] # サブセットの作成
display(df2)実行すると次のようになります。なお、第05行目
を df2 = df['性別','数学','理科'] のように
間違えて書く人が多い ので注意してください
(この場合、どのようになるか確認してみてください)。
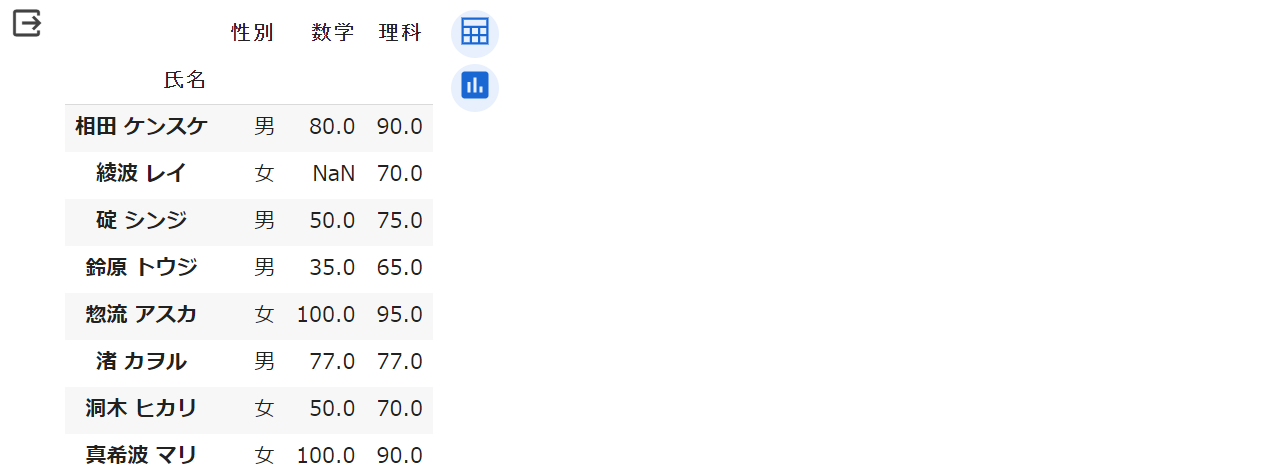
また、列の指定は、次のように変数を経由して行なうこともできます。また、このサブセットの作成を利用することで 列の順番を並べ替えしたり、不要な列の削除 したりすることもできます。
%reset -f
import pandas as pd
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
subjects = ['理科','英語','数学','国語','社会']
df2 = df[subjects] # リストを与えて特定列のサブセットを作成
display(df2)また「行」については以下のように スライス を使ってサブセットを取得することができます。スライスについては第17回講義で学習済みです。
%reset -f
import pandas as pd
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
df2 = df.iloc[3:] # ゼロオリジンで3行目以降を取得
display(df2)5.9 集計処理
ここでは、DataFrame オブジェクト を対象に「合計」や「平均」などを求める集計処理を行なう方法を紹介します。DataFrame オブジェクト の各種メソッドを使うことで、繰返し構文を使わずに処理できる点に着目してください。
まずは、各学生について、国語・数学・英語・理解・社会の「5科目」の試験成績に対して「合計 (Sum)」、「平均 (Mean)」、「欠点科目数」を求めてみたいと思います。
次のプログラムを実行してみてください。
%reset -f
import pandas as pd
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
subjects = ['国語','数学','英語','理科','社会']
df['合計'] = df[subjects].sum(axis='columns')
df['平均点'] = df[subjects].mean(axis='columns')
df['欠点科目数'] = (df[subjects] < 60).sum(axis='columns')
display(df)実行結果は、次のようになります。
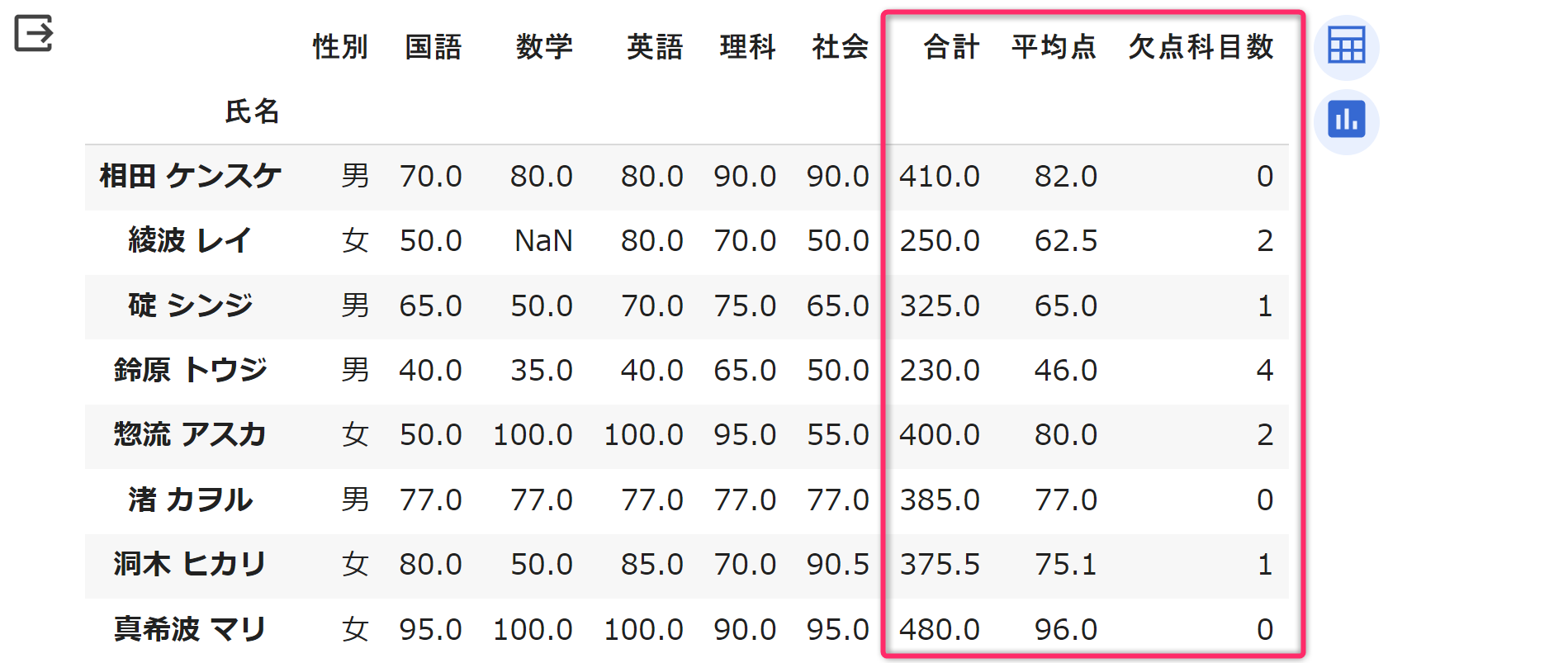
第08行目 では、DataFrame
に「合計」という「列」を新規に作成して、そこに各科目の点数の合計を格納しています。df[subjects].sum(axis='columns')
は
df[['国語','数学','英語','理科','社会']].sum(axis='columns')
の意味であり、「国語」「数学」「英語」「理科」「社会」の「列
(columns)」を対象に合計 (sum)
を求める処理になります。sum メソッドのオプションで
axis='columns' を指定しないと 行方向 (縦方向) の合計を求める処理
になってしまうので注意してください。また、このオプションは
axis=1 のように数字で指定することもできます。
第09行目 では、同様の考え方で
mean
メソッドを使って「平均」を求める処理をしています。sum
や mean の他に、最大値を求める max
メソッド、最小値を求める min メソッド、中央値 を求める median
メソッドなどがあります。
第10行目 では「60点未満の科目数」をカウントしています。この部分は、やや複雑なので 第10行目 を以下のように分解して、2段階で考えていきます。
解説1.py の 第01行目 では
df[subjects] < 60 の結果を df2
に代入し、第02行目
では整形出力しています。出力の結果、df2
は次のような内容を持った DataFrameオブジェクト
であることが分かります。
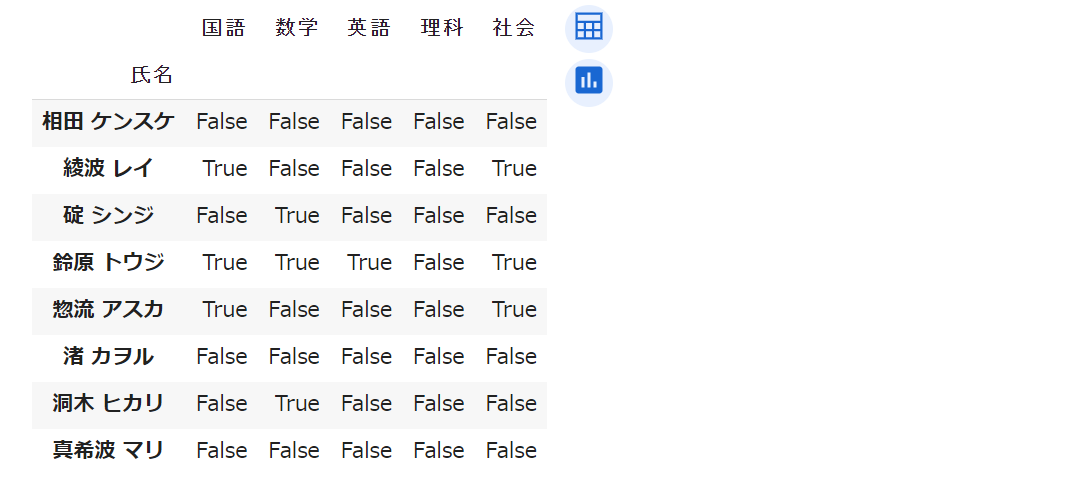
df2 のなかで True
となっている箇所は、元々の df
で値が「60未満」だった箇所です。例えば、鈴原トウジの国語が
True になっているのは、元々の df で
40.0 であっためです。このように DataFrame
オブジェクトに比較演算子を適用すると
(df[subjects] < 60 のようにすると)、真偽値の
DataFrame オブジェクトが生成されます。
そして、解説1.py の 第03行目
では、真偽値を値に持った df2 に対して
df2.sum(axis='columns') として、列方向 (横方向)
の合計を求めています。sum や mean
などのメソッドで、True は「1」、False
は「0」として扱われます。これにより、欠点科目数のカウントができています。
演習1: 集計処理.py の第08行目を
sum(axis=1)
としても同じ結果が得られることを確認してください。また
sum(axis='rows') あるいは sum(axis=0)
とすると、どのような結果になるか確認してください。
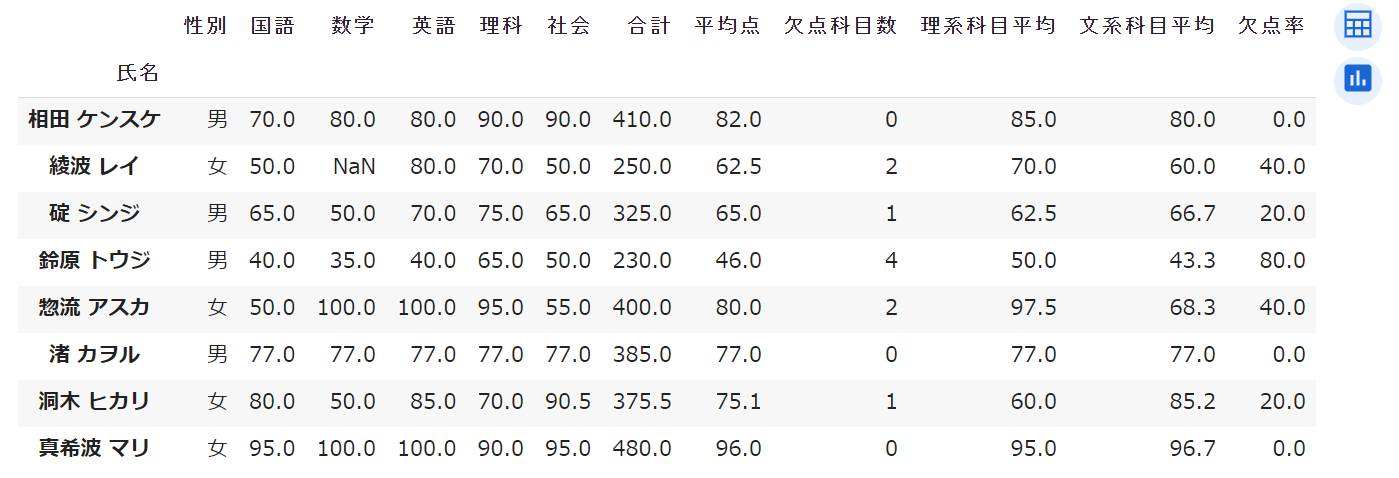
演習2:「理系科目平均」と「文系科目平均」という列を作成し、適切な値が表示されるようにしてください。小数以下の桁数も適切に表示するようにしてください。
- 解答例:
df['理系科目平均'] = df[['理科','数学']].mean(axis='columns').round(1) - 解答例:
df['文系科目平均'] = df[['国語','英語','社会']].mean(axis='columns').round(1)
演習3:「欠点率」という列を作成し、適切な値が表示されるようにしてください。
- 解答例:
df['欠点率'] = (df[subjects] <span 60).sum(axis='columns')/5*100
(参考)
5.10 ラムダ式を使った変換
DataFrameオブジェクト の map
メソッドを使うと、DataFrame内の「各要素」に対して「任意の関数
(ラムダ式)を適用すること」ができます。map は、元の
DataFrameオブジェクトを 変更せずに、新しい
DataFrameオブジェクト を戻り値として返します。
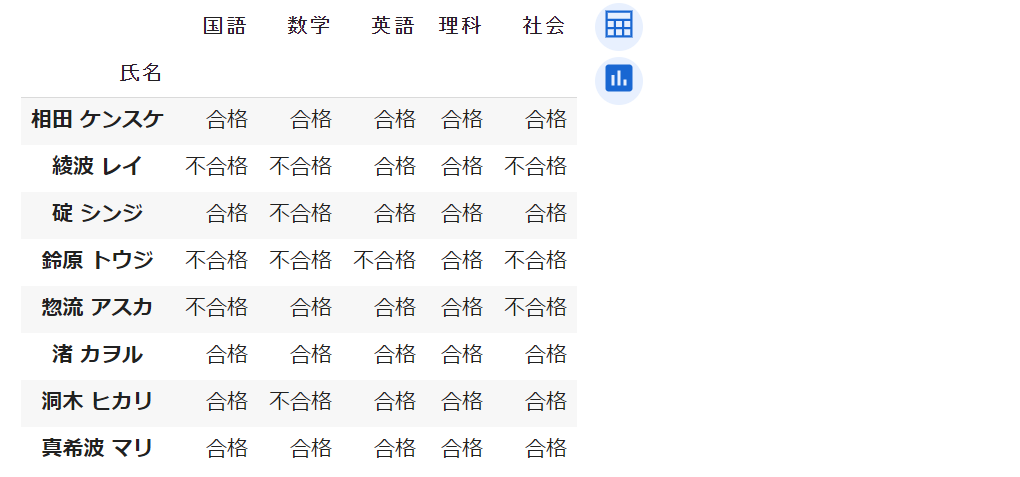
以下のプログラムは map メソッドを使って
60点未満を「不合格」、60点以上を「合格」という文字列
に置き換えた df2 という DataFrameオブジェクト
を作成・生成出力する例です。ここでは
lambda p: '合格' if p >=60 else '不合格'
という条件式を含んだ「ラムダ式」を利用しています。
%reset -f
import pandas as pd
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
subjects = ['国語','数学','英語','理科','社会']
df2 = df[subjects].map(lambda p: '合格' if p >=60 else '不合格' )
display(df2)
# display(df) # df は影響を受けていない。実行結果は次のようになります。
なお print(df2.dtypes)
を実行すると次のようになります (各列の型が float64
から object (文字列)
になっていることが確認できます)。
国語 object
数学 object
英語 object
理科 object
社会 object
dtype: object演習
90点以上を「秀」、90点未満80点以上を「優」、80点未満70点以上を「良」、70点未満60点以上を「可」、60点未満を「不可」のような文字列に置き換えた
DataFrameオブジェクト df3
を作成し、出力してください。なお、このような多段階の条件分岐をラムダ式で扱うことは適切ではないので、通常の関数定義を利用してください。
(ヒント) 上記の 合格・不合格.py
をラムダ式を使用せずに通常の関数定義を使って記述すると、次のようになります。
%reset -f
import pandas as pd
def grade_converter(p):
if p >= 60 :
return '合格'
else :
return '不合格'
fn = 'score-2.csv'
df = pd.read_csv(fn,encoding='utf-8',index_col='氏名')
subjects = ['国語','数学','英語','理科','社会']
df2 = df[subjects].map(grade_converter)
display(df2)6 大学編入試の問題に挑戦 (1)
大学編入学 (学力選抜) の情報系学科の 専門試験 では C言語を用いたデータ構造とアルゴリズム に関する問題がよく出題されます。
「C言語」については3年生の前期科目「プログラミング2」で詳しく学びますが、その基本文法は「マイクロコンピュータ」の授業で既に学んでいるはずです。さらに「データ構造とアルゴリズム」は 特定のプログラミング言語に依存しない ため (つまり、これまでに本科目で Python言語 を用いて学んできた内容を応用できるため)、現段階でも十分に解答できる問題 が多数あります。
以下に紹介する問題は、豊橋技術科学大学「情報・知能工学課程」の令和5年度の編入学試験問題 (https://www.tut.ac.jp/exam/entrance/past.html) から抜粋したものです。即答できる問題ではありませんが、PCを道具に使って取り組めば、現時点でも十分に解ける内容となっています。
リスト1 は, 3つの変数, a と b と
M のそれぞれにある自然数を入力として与えたとき,
変数の値を出力する C言語プログラム
である。以下の空欄 [A] ~ [C]
に入れる適切なものを答えよ。ただし, int型は 32bit であるとし,
扱う自然数はint型で表現できるものとする。
リスト1において,
aに4,bに2,Mに5を入力したとき, 19行目の値 は [A] である。また,aに4,bに8,Mに5を入力したとき, 19行目のnの値は [B] である。また,aに 4,bに256,Mに5を入力したとき, 19行目の値は [C] である。
#include <stdio.h>
int main(void){
int i, a, b, M;
int n = 1;
printf("自然数を入力:");
scanf("%d", &a);
printf("自然数を入力:");
scanf("%d", &b);
printf("自然数 M を入力:");
scanf("%d", &M);
for(i=1; i<=b; i++) {
n=(a*n)%M;
}
printf("n = %d\n",n);
return 0;
}実際の試験ではPC(各種言語の実行・開発環境)を使用することはできません(紙と鉛筆、頭だけを用いて解答する必要があります)。しかし、入試勉強として取り組む際には、単に問題を眺めて挑むのではなく PCを使って実際に手を動かしてコーディング・実行し、それを通じて理解を深め、思考力を鍛えること を強く推奨します。上記の問題であれば 第19行目 の周辺に、ループ毎の変数値を出力する文を追加することは非常に効果的です。
C言語の実行開発については、昨年度の「情報1」の第10回講義で紹介しているようにPaiza.IOなどのウェブブラウザから利用可能な オンライン型のC言語の実行開発環境 を利活用してください。
- Paiza.IO で試すときは、
scanf("%d", &a);の部分はa=4;のように書き換えて実行することをお勧めします。
また、C言語プログラム を Pythonプログラム に移植することで 「理解が深化する」 「勘違いに気づく」「実装力が鍛えられる」といった効果があります。一見すると遠回りのように思えるかもしれませんが、実際には非常に効果的で効率的な学習法です。