1 概要・連絡
2年生の後期となりました。コース専門科目では「これまでに学んできたこと」を前提とする内容が一気に増加します。課題を提出したり、定期試験を終えたりするとそれまで「学んだこと」をキレイに忘れてしまう学生や、そもそも定着を前提としない勉強 (=学ぶことが目的ではなく、単位を取ることを目的にした勉強) になっている学生もいますが、専門科目でその方針をとると、いずれ「詰み」という状況に直面するので十分に注意してください。
一方で、それなりに学んできた学生については、これからの時期は科目の枠を越えて、点と点が線として繋がる瞬間 が増えて「学び」が面白くなってくると思います。
1.1 今回講義の達成目標
- リスト型とタプル型の特性の違いを理解し説明できる。
- NumPy の ndarray 型の特性を理解し、初期化や基本操作ができる。
- Google Colab. ノートブックを GitHub にプッシュすることができる。
1.2 連絡事項
- 小テストで 8点未満 の学生は、再度、次回に小テストを実施します。自己採点で8点未満と思う学生は準備しておいてください。
- 今回の講義では
%timeitなどの時間計測用の マジックコマンド も使用するのでGoogleColab.もしくはローカルPCに構築したJupyter環境の利用を推奨します。
2 リスト型 (List) の復習
Python の「リスト型」については第08回講義 のなかで取り上げました。また「2次元リスト」も第13回講義 のなかで取り上げました。
ここでは、後述する「タプル型」や、NumPy ライブラリ (「ナンパイ」と読む) の「ndarray型」と比較するために、リスト型の「特性」や「操作」を簡単に復習しておきます。
2.1 初期化と要素の参照
リスト型は、その「要素」として様々な型
(整数型、浮動小数点数型(実数型)、文字列型、ブール型など)
を「混在させること」が可能で、1次元の場合は
list-01.py の arr1
のように初期化ができまた。
また、2次元の場合は arr2
のように初期化ができました。この際、行ごとの要素数 (列数)
を変えることも可能でした。
%reset -f
arr1 = [29, 3.14, "円周率", False] # 様々な型を内包することが可能
arr2 = [[0.0, 0.1], # 行ごとの要素数が違っていても可
[1.0, 1.1, 1.2],
[2.0],
[3.0, 3.1, 3.2, 3.3]]
print(f'型確認 arr1 => {type(arr1)}') # 型確認 arr1 => <class 'list'>
print(f'型確認 arr2 => {type(arr2)}') # 型確認 arr1 => <class 'list'>
print(f'arr1 の長さ(要素数)は {None}') # => 4
print(f'arr2 の長さ(要素数)は {None}') # => 4
print(f'arr2[0] の長さ(要素数)は {None}') # => 2
print(f'arr2[1] の長さ(要素数)は {None}') # => 3演習: list-01.py
の第11行目から第14行目で期待する値
(# => ? で表記した値)
が出力されるようにプログラムを書き換えよ (=
f文字列のプレースホルダのなかの None
を適切なものに書き換えよ)。ヒント: 組み込み関数の len
関数を利用してください。ブラウザの横幅が狭い場合や、モバイル端末からアクセスしていると行番号が表示されないため注意ください。
2.2 要素の参照
リストを構成する「要素」にアクセスするための値
(例えば a[5] における 5 のこと) を インデックス あるいは 添え字
と呼び、これは「先頭要素を 0
番目」からカウントする特性がありました。このように「ゼロからカウントすること」を
ゼロオリジン と表現しました。
また、2次元配列の要素にアクセスするときのインデックスの指定順は、数学の「行列」の添え字の表記順と
同じでした。例えば
list-02.py の arr3
のなかの「14」という値を参照 (取得) したい場合は arr[0][2]
のように指定しました。
%reset -f
arr3 = [[26, 38, 14, 57], # 3行4列の2次配列の初期化
[39, 31, 94, 63],
[41, 72, 65, 24]]
# 演習1
a = 0
print(f'a = {None}')
# 演習2
print(arr3)
# 演習3
b = 0
print(f'b = {None}')演習1: arr3 の要素「31」を変数
a に取得せよ。
演習2: arr3
の要素「57」を「60」に書き換えよ。
演習3: arr3 の要素「24
(最終行の最終列の値)」を変数 b
に取得せよ。ただし、arr3[2][3]
以外の方法で取得 (参照)
すること。ヒント: インデックスに -1
を使用する方法と、リスト長さを取得する関数 len()
を使用する方法があります。どちらの方法でも末尾の値を取得 (参照)
できるようにしておいてください。
2.3 要素の追加
リスト型では append()
というメソッドを使って、リスト末尾に要素を 追加 することができました。なお「先頭」や「任意のインデックス位置」に要素を挿入することもできました。
以下のプログラムを実行して、その動作について確認と理解をしてください。
%reset -f
arr4 = ['A','B','C']
arr4.append('D') # 末尾に 'D' を挿入
arr4.append('E')
print('arr4 = ',end='')
print(arr4) # => ['A','B','C','D','E']
arr5 = []
arr5.append(['A','B'])
arr5.append([]) # 末尾に 空のリスト [] を挿入
arr5[1].append('C') # 上で挿入した空リストの末尾に 'C' を挿入
arr5[1].append('D')
print('arr5 = ',end='')
print(arr5) # =>[['A','B'], ['C','D']]演習: arr5 の内容が
[['A','B'], ['C','D'], ['E','F']]
となるように第13行目以降にプログラムを追加せよ。
2.4 繰返し構文と組み合わせたリストの操作
リストを構成する要素に対する一括操作は「繰返し構文
(for文)」と組み合わせることで実現しました。例えば
list-04.py の arr6
の各要素に「5を加算」するためには 繰返し構文を2重にして利用しました。ここでは、特に第07行目で
range(len(arr6[i])) のように記述していること (これにより、各行の要素数が違っていても対応できること)
について、しっかりと理解してください。
%reset -f
arr6 = [[10, 20, 30, 40],
[50, 60, 70],
[80, 90]]
for i in range(len(arr6)):
for j in range(len(arr6[i])):
arr6[i][j] += 5
print(arr6)
# 演習
arr7 = [[20,30,40],[50,40,30]]
arr8 = [[10,20,10],[20,10,10]]
arr9 = []
print(arr9) # => [[30, 50, 50], [70, 50, 40]]演習: arr7 と arr8
を使って次のような行列計算をして arr9
に格納せよ。まずは arr9=arr7+arr8
では期待するような結果 ([[30, 50, 50], [70, 50, 40]])
に「ならないこと」を確認すること。
\[ \begin{bmatrix} 20 & 30 & 40 \\ 50 & 40 & 30 \\ \end{bmatrix} + \begin{bmatrix} 10 & 20 & 10 \\ 20 & 10 & 10 \\ \end{bmatrix} = \begin{bmatrix} 30 & 50 & 50 \\ 70 & 50 & 40 \\ \end{bmatrix} \]
2.5 スライス
Pythonのリストでは arr[3:] や arr[:3]
のような表記によりスライスという機能も利用できました。他のプログラム言語
(C/C++言語やJavsScriptなど)
ではあまり採用されていない表記ですが、Python (実務)
では頻繁に使われるので覚えておくようにしてください。
スライスは、次のようにリスト内の「指定範囲 (部分) を取得」する機能になります。
%reset -f
arr = list(range(1,11)) # rangeを使用した初期化
print(arr) # => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(arr[:3]) # arr[0]からarr[3-1]までスライス
print(arr[2:5]) # arr[2]からarr[5-1]までスライス
print(arr[4:]) # arr[4]から末尾までスライス
print(arr[5:5+3]) # arr[5]から要素3個をスライスなお、文字列についてもスライスを適用すること ができました。こちらも多用するので覚えておいてください。
演習: list-05.py の
arr から [2,3,4,5,6]
を取得するようなスライスを記述せよ。
2.6 浅いコピーと深いコピーの違い
第13回講義で丁寧に解説したようにリストを「複製 (コピー)」する場合には、その特性の違いに注意して「浅いコピー (Shallow copy)」と「深いコピー (Deep copy)」を使い分ける必要がありました。
%reset -f
import copy
# ■■ 浅いコピー ■■
arr10 = [10,20,30]
arr11 = arr10 # 浅いコピー
arr11[0] = 'A'
print('浅いコピー')
print(f'arr10 = {arr10}') # => arr10 = ['A', 20, 30] ← !!!
print(f'arr11 = {arr11}') # => arr11 = ['A', 20, 30]
# ■■ 深いコピー ■■
arr10 = [10,20,30]
arr11 = copy.deepcopy(arr10) # 深いコピー
arr11[0] = 'A'
print('深いコピー')
print(f'arr10 = {arr10}') # => arr10 = [10, 20, 30] ← :D
print(f'arr11 = {arr11}') # => arr11 = ['A', 20, 30]:D は海外でよく使われる顔文字です
(顔を90度傾けてみてください)。
この「浅いコピー」と「深いコピー」の問題は リストに限らず「辞書」や「クラス」でも同様に起きます。理解が難しい概念ですが、避けては通れないのでどこかの段階ではしっかりと理解してください。
3 タプル型 (Tuple)
Python には リスト (List) に似て非なる型として タプル (Tuple) という型 (データ構造) が存在します。簡単に言えば、タプルは「読み取り専用のリストのような型」と言えます。
3.1 タプルは変更不可
リストは a=[20,30] のように「角括弧
(大括弧)」で初期化していたのに対して、タプルは
tpl=(20,30)
のように「丸括弧」で初期化します。次のプログラムを実行して確認してください
(変数名を型名と同じ tuple にしたり、ファイル名を
tuple.py にすると機能しないので注意してください)
。
%reset -f
arr = [20,30] # [ ] により「リスト型」として初期化される
print(type(arr)) # => <class 'list'>
tpl = (20,30) # ( ) により「タプル型」として初期化される
print(type(tpl)) # => <class 'tuple'>先に解説したように
タプルは、初期化後に要素を変更したり、append()
メソッドで要素を追加したりすることはできません。
%reset -f
tpl = (20,30)
# 要素の「変更」は不可
tpl[0] = 40 # => TypeError: 'tuple' object does not support item assignment%reset -f
tpl = (20,30)
# 要素の「追加」も不可
tpl.append(50) # => AttributeError: 'tuple' object has no attribute 'append'ただし、以下のように丸ごと入れ替えることは可能です。なぜならば、変数に格納されるものは「データそのもの」ではなく、そのデータを指し示す「オブジェクトID」であるためです (このあたりの内部動作やオブジェクトID云々を忘れてしまった人は第13回講義の解説 を読み返してください)。
以上の変更可能/不可能の特性の違いさえ意識しておけば関数の引数にリストと同様にタプルを使用することができます。
リストとタプルは関数の引数として (ほとんどのケースで) 互換性がある
第08回講義
で学んだように random.choices は、引数
weights で与えた確率に従って、ランダムに
k
個の要素を選択して返す関数でした。これまでは、次のように引数を「リスト型」で与えてきました。
これは「タプル型」に置き換えることができます。
3.2 タプルを利用する価値はあるのか
タプルと採用することで「その値が変更不可であること」を明示できます。初期化以降、プログラムの途中で要素を変更することや 要素を追加や削除すること を意図しないケースでは、リスト型ではなくタプル型を使用することが望まれます。特にチーム開発では、タプル型にしておくことで 要素の変更を想定していないこと 、要素の追加や削除を想定していないこと を簡単にメンバーに共有することができるというメリットがあります。
また、リスト型はない タプル型のメリット として 辞書型 (dict型・連想配列型) の「キー」に使用できる点が挙げられます (辞書型について忘れてしまった学生は第12回講義を再読してください) 。
まずは文字列を辞書型のキーに利用する例 (復習) を以下に示します。
%reset -f
course = {'I':'知能情報', 'M':'エネルギー機械'} # 辞書の初期化
course['E'] = 'エレクトロニクス' # 初期化後の辞書に追加
course['D'] = 'プロダクトデザイン'
key = 'I'
print(f'{key} ... {course[key]}')
print()
# for構文の組合せた全列挙
for key in course.keys():
print(f'{key} ... {course[key]}')上記のプログラムでは、キー (key)
に「文字列」を使用しましたが、次のようにキーに「タプル」を使用することもできます。
%reset -f
timetable = {
('月',1) : 'プログラミング1',
('月',3) : '基礎物理2',
('月',5) : '微分積分2'
}
timetable[ ('火',1) ] = 'メディアデザイン入門'
timetable[ ('火',3) ] = '社会2'
key = ('水',1)
print(f'{key[0]}曜日 {key[1]}時限 ',end='')
if key not in timetable.keys(): # キーが存在するかチェック
print(f'に授業は登録されていません')
else:
print(f'は「{timetable[key]}」が開講されます')
key = ('月',3)
print(f'{key[0]}曜日 {key[1]}時限 ',end='')
if key not in timetable.keys():
print(f'に授業は登録されていません')
else:
print(f'は「{timetable[key]}」が開講がされています')上記では2個の要素を持ったタプルを使いましたが
('2I','火',3) や (2,'I','火',3)
のように3個以上の要素を持ったタプルもキーとして使用できます。
一方で、辞書型のキーに「リスト型」を使用すると
TypeError: unhashable type: 'list'
という実行時エラーが発生します。
3.3 タプル型とリスト型の相互変換
「タプル型」と「リスト型」は次のように相互変換できます。プログラムを実行して確認してみてください。特に
タプル型とリスト型の「丸括弧」と「角括弧」の違いが、初期化や
print 関数の出力に表われていること
に注意してください。
%reset -f
a = [20,30] # 変数a にリスト型のオブジェクトを格納
print(type(a)) # => <class 'list'>
print(f'a={a}') # => a=[20, 30]
print()
t = tuple(a) # リスト型→タプル型に変換
print(type(t)) # => <class 'tuple'>
print(f't={t}') # => t=(20, 30)%reset -f
t = (20,30) # 変数a にタプル型のオブジェクトを格納
print(type(t)) # => <class 'tuple'>
print(f't={t}') # => t=(20, 30)
print()
a = list(t) # タプル型→リスト型に変換
print(type(a)) # => <class 'list'>
print(f'a={a}') # => a=[20, 30]これらの変換は x=int('10') により文字列型
'10' を 整数型 (int型)
に変換できたことと同じです。既に学習済みですが
float、str で同様に「実数型
(浮動小数点数型)」「文字列型」に変換することができます。
演習 : 次のプログラムを実行したときの第07行目の出力を予想せよ。また、実際にプログラムを実行して確認せよ。
%reset -f
a = [10,20,30]
t = tuple(a)
print(f't={t}') # => t=(10, 20, 30)
a[1] = 50
print(f't={t}') # => ???4 NumPy
4.1 NumPyとは
NumPy (ナンパイ) は Numerical Python の略称でPythonの数値計算のためのライブラリ (モジュール)です。数値計算や科学技術計算に関連する「計算」や「処理」を簡潔なコードで記述可能で、またライブラリの本体が「C言語」で実装されていることから、非常に高速な処理が可能なことが特長になっています。
また、NumPy
は、その他の様々なPythonライブラリでも内部的に使用されており、それらライブラリとデータをやり取りするときには
(=引数として与える、戻り値として受け取るときには)
NumPy の ndarray
型が頻繁に使用されます。例えば、データ処理ライブラリの「Pandas」や可視化ライブラリの「Matplotlib」「Seaborn」、画像処理ライブラリの「OpenCV」、機械学習関連ライブラリの「scikit-learn」「TensorFlow」「PyTorch」などを効率よく利用するためには「NumPy
の基礎知識」が必要となります。
4.2 NumPyのインポートとndarray型
GoogleColab. 環境ではデフォルトで NumPy
がインストールされているので、インポートすればそのまま利用することができます。また、ローカルPCに環境を構築した場合
(仮想環境を構築した場合) は、コマンドラインから
pip install numpy で NumPy
をインストールしてください。
常に最新版の pip を使用すること
久しぶりに pip を実行する場合は、以下のコマンドで pip を最新版にアップグレードしてください。少しでもバージョンが古いと正常動作しないことがあります。詳しくは、第09回講義のpipの基本を再読してください。
python -m pip install --upgrade pipNumPy
がインストールされた環境では、次のようにライブラリを読み込みます。慣例的に
np
という略称で利用するので覚えておいてください。また、ライブラリの名称は「NumPy」ですが、インポートするときは全て小文字で
numpy と記述する点にも注意してください。
次のプログラムを実行して、その結果を確認してください。
%reset -f
import numpy as np # numpy をインポート
A = np.array([[20,30,40],[50,40,30]])
B = np.array([[10,20,10],[20,10,10]])
# print(type(A)) # => <class 'numpy.ndarray'>
print(A+B)上記は、次の行列の和を計算するプログラムです。
\[ A=\begin{bmatrix} 20 & 30 & 40 \\ 50 & 40 & 30 \\ \end{bmatrix},\ \ \ B=\begin{bmatrix} 10 & 20 & 10 \\ 20 & 10 & 10 \\ \end{bmatrix}\]
先ほど「繰返し構文と組み合わせたリストの操作」のセクションの「演習」で、同じ計算をしてもらいましたが、それよりも格段に直感的で簡潔なコードになっていることが分かると思います。また、ここでは実感がないと思いますが NumPy を使ったほうが 実行にかかる時間も格段に短くなっています。
第06行目のように NumPy では行列 (ベクトル) は
ndarray という 型 (データ構造)
で扱います。「データ分析」や「画像処理」「可視化」「機械学習」などのライブラリを使うときは
ndarray 型でデータを与える /
データを受け取ること
が頻繁にあるので頭のなかに入れておいてください。
参考:NumPyを使わずに行列の和を求める場合との比較
NumPy
ライブラリを使わずに「リストとfor文を組み合わせ」で「行列の和」を求めるプログラム例を示します。ndarray
型では単に A+B で計算できましたが、List
型では2重ループを使用する必要があります。
ベクトルや行列の 実数倍 (スカラー倍)
は、変数 A が ndarray 型とすれば
4*A や A*(-2)
のように計算できます。また、積 は変数
A と B が ndarray
型とすれば np.dot(A,B) あるいは A@B
により計算ができます。
%reset -f
import numpy as np
A = np.array([[ 1, 3],[ 2, 5]])
B = np.array([[ 2,-1],[-3, 1]])
#【実数倍】 例:2A-B
X = 2*A-B
print(X)
#【積】 例:A・B
Y = A@B # もしくは np.dot(A,B)
print(Y)ndarray 型の積の計算に関する注意
* 演算子を使用すると、いわゆる行列の積
(matrix product) ではなく アダマール積 (Hadamard
product) が計算されるので注意してください。
演習1: 行列 \(A\) と 行列 \(B\) が次のように与えられるとき \(2(A-4B)+3(A+2B)\) を NumPy を利用して求めよ。また、適切な結果が得られていることを手計算と比較して確認せよ。※「ベクトル・行列」の教科書 p.47 の 問3.3
\[ A=\begin{bmatrix} 0 & 1 \\ 5 & 2 \\ \end{bmatrix},\ \ \ B=\begin{bmatrix} 0 & -1 \\ 4 & 2 \\ \end{bmatrix}\]
演習2: 次の行列の積を計算せよ。※「ベクトル・行列」の教科書 p.49 の 問3.4 (5)
\[ X=\begin{bmatrix} 2 & -4 & 3 \\ 1 & 2 & -3 \\ \end{bmatrix}\begin{bmatrix} 1 & -3 & 2 \\ -1 & -2 & 1 \\ -2 & 0 & 5\\ \end{bmatrix}\]
4.3 要素の参照
2次元以上の ndarray 型では
要素にアクセスする方法
として、次のような表記も使用できます。
%reset -f
import numpy as np
a = np.array([[ 1, 3],[ 2, 5]])
print(f'ndarray型の変数 a の1行0列目の値は => {a[1][0]}')
print(f'ndarray型の変数 a の1行0列目の値は => {a[1,0]}') # 注目- リスト型に対しては
a[1,0]のような参照ができないので注意してください。 ndarray型ではa[1,0]を使用したほうが処理上では効率的であり、またエラーが発生した場合にも原因が特定しやすいです。
4.4 ブロードキャスト
NumPy には ブロードキャスト (形状の自動変換) という機能があります。これは「形状が異なる行列同士の四則演算」や「行列とスカラーの加算・減算」の際に自動で適用される機能になります。
例えば、次のような「行列からスカラーを減じる計算」は数学的には通常許されませんが、NumPy ではブロードキャスト機能により可能になります。この例では、スカラー値の「3」がブロードキャストにより、2行3列の行列に自動変換 されて計算が行われます。
\[ \begin{bmatrix} 3 & 4 & 5 \\ 6 & 7 & 8 \\ \end{bmatrix} - 3 \]
つまり、NumPy では、自動的に次のように解釈されて計算されます。
\[ \begin{bmatrix} 3 & 4 & 5 \\ 6 & 7 & 8 \\ \end{bmatrix} - \begin{bmatrix} 3 & 3 & 3 \\ 3 & 3 & 3 \\ \end{bmatrix} = \begin{bmatrix} 0 & 1 & 2 \\ 3 & 4 & 5 \\ \end{bmatrix} \]
実行結果は次のようになります。
[[0 1 2]
[3 4 5]]4.5 余談:行列の整形出力
GoogleColab. 環境や Jupyter 環境では次のように行列を整形出力することができます。
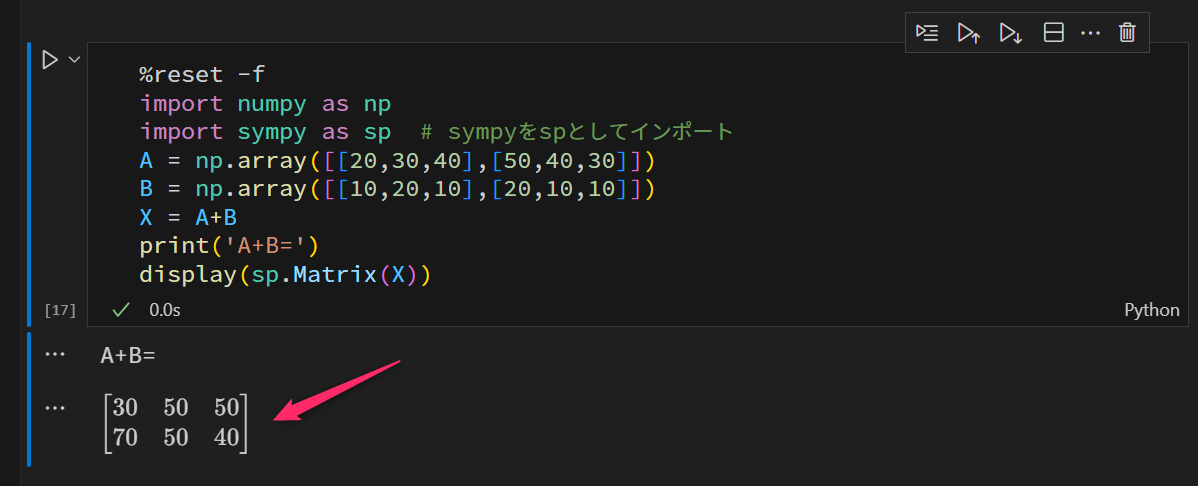
%reset -f
import numpy as np
import sympy as sp # sympyをspとしてインポート
A = np.array([[20,30,40],[50,40,30]])
B = np.array([[10,20,10],[20,10,10]])
X = A+B
print('A+B=')
display(sp.Matrix(X)) # ndarray型の行列を整形出力実行結果は次のようになります。
高度な整形出力
次のように高度な整形出力もできます。sp.latex(...)
により LaTeX形式の数式 (文字列)
に変換し、display(Math(..))
によりそれをレンダリング出力します。
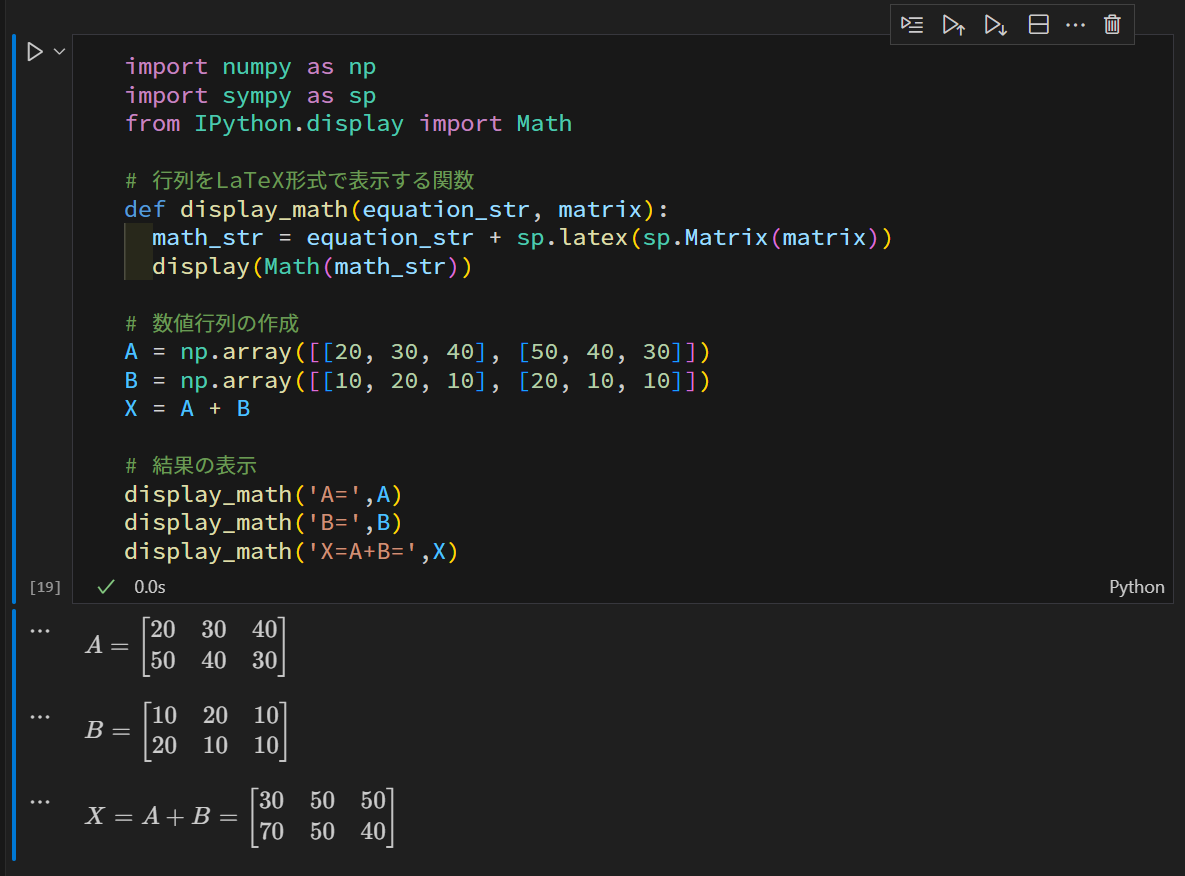
%reset -f
import numpy as np
import sympy as sp # sympyをspとしてインポート
from IPython.display import Math
# 行列をLaTeX形式で表示する関数
def display_math(equation_str, matrix):
math_str = equation_str + sp.latex(sp.Matrix(matrix))
display(Math(math_str))
# 数値行列の作成
A = np.array([[20, 30, 40], [50, 40, 30]])
B = np.array([[10, 20, 10], [20, 10, 10]])
# 行列の加算
X = A + B
# 結果の表示
display_math('A=',A)
display_math('B=',B)
display_math('X=A+B=',X)以下、ローカル環境に構築したJupyterで実行したときのスクリーンショットです。
なお、display(Math(..)) は汎用性があるので NumPy
とは無関係に次のように利用もできます。
%reset -f
from IPython.display import Math
eq1 = r'\lim_{n \to -1}\frac{-1}{(x+1)^2}=-\infty'
eq2 = r'\sin^{-1}\frac{\sqrt{3}}{2}=\frac{\pi}{3}'
display(Math(eq1))
display(Math(eq2))実行すれば、出力セルに次のように美しくレンダリングされた数式を得ることができます。数式のLaTeX表記については、第06講義や「TeX 数式」などでウェブ検索してください。
\[ \lim_{n \to -1}\frac{-1}{(x+1)^2}=-\infty \] \[ \sin^{-1}\frac{\sqrt{3}}{2}=\frac{\pi}{3} \]
4.6 ndarray型とリスト型の違い
NumPy の ndarray
型は、Python標準のリスト型と違い、次のような制約があるので注意してください。
ndarrayは「同じデータ型の要素」で構成する必要があります。異なるデータ型の要素を混在させることはできません。ndarrayは作成後、そのサイズを変更することができません。要素の追加や削除をしたい場合、新しいndarrayを作成する必要があります。ndarrayは、各次元ごとに同じサイズを持つ配列のみが扱えます。[[10,20,30], [40,50], [60]]のように各行の長さが違うような配列 (=「ジャグ配列」や「不規則配列」という) を扱うことはできません。
4.7 ndarray型の初期化
ここまでに扱ってきたように ndarray
型は、np.array()
関数の引数に「リスト型」を与えて初期化することができました。
%reset -f
import numpy as np
a = [[1,2,3],[4,5,6]]
print(f'変数 a の型は {type(a)}') # => 変数 a の型は <class 'list'>
A = np.array(a) # a を引数に np.array() で ndarray を作成(初期化)
print(f'変数 A の型は {type(A)}') # => 変数 A の型は <class 'numpy.ndarray'>この他に np.arange() や np.linspace()
を利用して ndarray を作成 (初期化) ができます。
4.7.1 np.arange() による初期化
0.00 から 3.00 まで
0.25 刻みの値 (=等差数列)
を得たいときは np.arange() の「第1引数(開始値)」に
0.00、「第2引数(終了値(未満))」に
3.01、「第3引数(間隔・等差)」に 0.25
を与えます。なお、リストを生成する range() では 「間隔」を小数値で与えることができませんでした。
実行結果は、次のようになります。x.size
で要素数を得ることができます。終了値は「以下」ではなく「未満」の指定になることに注意してください
(第2引数に 3.00
を指定すると、どのように結果が変わるかを確認してください) 。
x.size => 13
[0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. 2.25 2.5 2.75 3. ]4.7.2 np.linspace() による初期化
np.linspace() では「開始値
(以上)」と「終了値
(以下)」と「分割数」与えて ndarray
型を生成することができます。例えば「0.00」以上「3.00」以下の範囲を13等分
(結果的には0.25刻み) にする場合は次のようにします。
実行結果 (ndarray型の変数xの内容)
は、先ほどと同じく次のようになります。第04行目の
assert文 について忘れてしまった学生は第11回講義を再読してください。
[0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. 2.25 2.5 2.75 3. ]4.8 ndarray型とリスト型の相互変換
NumPyの「ndarray型」と「リスト型」は次のように相互変換できます。実際にプログラムを実行して確認してみてください。
%reset -f
import numpy as np
p = list(range(10,16)) # リスト型を生成
print(type(p)) # => <class 'list'>
print(f'p={p}') # => p=[10, 11, 12, 13, 14, 15]
print()
q = np.array(p) # リスト型→ndarray型に変換
print(type(q)) # => <class 'numpy.ndarray'>
print(f'q={q}') # => q=[10 11 12 13 14 15]%reset -f
import numpy as np
q = np.arange(10,16) # ndarray型を生成
print(type(q)) # => <class 'numpy.ndarray'>
print(f'q={q}') # => q=[10 11 12 13 14 15]
print()
p = q.tolist() # ndarray型→リスト型に変換
print(type(p)) # => <class 'list'>
print(f'p={p}') # => p=[10, 11, 12, 13, 14, 15]ここでは、リスト型と ndarray 型 では print 関数で出力したときの表示
(カンマの有無) が違うこと また 等差数列を生成するときの関数 /
メソッドの名前が微妙に違うこと (range と
arange ) に注意してください。
演習1: [10, 15.5, 20]
のような整数型 (int) と浮動小数点数型
(float) が混在するリストを ndarray
型に変換しようとするとどうなるか確認せよ。また
[10, 15.0, 20] の場合はどうなるか確認せよ。
演習2: タプル型 を ndarray
型に変換するためにはどうすればよいか。逆に ndarray
型を タプル型 に変換するためにはどうすばよいか。
5 NumPyを活用した数学関数計算とグラフ描画
5.1 数学関数の計算
NumPy を利用すると数学関数の「数値計算」を効率的に実行することができます。例えば \(y=2x+3\) について \(0\le x \le 1.0\) の範囲における \(0.1\) 刻みの \(y\) の値は次のように計算できます。
%reset -f
import numpy as np
x = np.linspace(0.0,1.0,11) # 0.0 から 1.0 の範囲を11等分
print(f'x = {x}')
y = 2*x + 3 # ブロードキャストによる計算
print(f'y = {y}')NumPyの初期化とブロードキャスト計算によって 繰り返し構文を用いることなく簡潔にコードが記述できていることが分かります。実行結果は次のようになります
(ここでは、見やすいようにスペースを追加しています)。print
関数で ndarray
型を出力すると「3.0」は「3.」のように省略表示される点に注意してください。
x = [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
y = [3. 3.2 3.4 3.6 3.8 4. 4.2 4.4 4.6 4.8 5. ]5.2 グラフ描画
第11回講義 で簡単に紹介したように Python には Matplotlib (マットプロットリブ) という 可視化支援ライブラリ があります。Matplotlib は シンプルなグラフ描画 から Excelでは不可能な高度な可視化 (Visualization) までを幅広くサポートしており、様々な場面で利用されています。
Matplotlib
にはリスト型でデータを与えることも可能ですが、ndarray
型にも対応しています。特に多次元の配列については、リスト型ではなく
ndarray 型で与えることが現実的になります。
以下に、NumPy で関数 \(f(x)=-x^3+3x^2+9x-27\) について、\(-4\le x \le 4\) の範囲を数値計算したものを Matplotlib により可視化する例を示します。プログラムを実行して結果を確認してください。
%reset -f
import numpy as np
import matplotlib.pyplot as plt # Matplotlib の読込み
x = np.linspace(-4,4,101)
y = -x**3 + 3*x**2 + 9*x -27
assert type(x) == np.ndarray # x は ndarray型であることを確認
assert type(y) == np.ndarray # y は 〃
fig,ax = plt.subplots(dpi=120)
# ax.plot(x,y)
ax.scatter(x,y,marker='o',s=15,alpha=0.5) # x と y を与えて丸を描画
ax.axhline(0,c='black',lw=0.5) # y=0 に太線を描画
ax.axvline(0,c='black',lw=0.5) # x=0 に太線を描画
ax.grid() # グリッドの表示
plt.show()このプログラムでは、特に 第12行目
で「ndarray 型の x と
y」を描画データとして Matplotlib
の関数に与えている点に注意してください。
演習1: 第05行目 を
x = np.linspace(-4,4,51)
に変更するどうなるか予想し、実際に結果を確認せよ。
演習2: 第05行目 を
x = np.linspace(-4,6,101)
に変更するどうなるか予想し、実際に結果を確認せよ。
演習3: 第12行目 の引数
marker='o' を marker='x'
に変更して結果を確認せよ。
演習4: 第12行目 をコメントアウトして、第11行目 をアンコメントして結果を確認せよ。
6 画像処理
画像処理ライブラリであるOpenCVにおいて「画像」は
NumPy の ndarray 型として扱われます。
前期の「情報2」の第05回講義
で学んだように、ラスター形式の画像(ビットマップ形式の画像)は、通常、2次元に並べられた数値によって表現されます。Python
の OpenCVライブラリ では効率性や機能性の理由から これら画像を「リスト型」ではなく、2次元または3次元の「ndarray
型」として扱います。
以下に、OpenCV において NumPy が使われていることが確認できるプログラムを示します。なお、プログラムを実行する場合は lenna_256x256.png を実行フォルダに配置してください。GoogleClab.の場合は画像をアップロードしてください。
{kind=link}
ここでは、特に第22行目
のネガポジ変換処理 (
img_r = 255 - img ) で NumPy
のブロードキャスト機能が効果的に活用されていることに注目してください。画像のネガポジ変換について忘れてしまった学生は、「情報2」の第05回講義資料の
p.84 を参照してください。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 画像表示(Matplotlibのimshowを利用)
def show_image(img):
plt.imshow(img,cmap='gray')
plt.axis('off')
plt.show()
# 画像をグレースケール(8bit)で読み込み
img = cv2.imread('lenna_256x256.png',cv2.IMREAD_GRAYSCALE)
# 変数imgが格納するオブジェクトの基本情報の確認
print(f'img は {type(img)} 型のデータで、',end='')
print(f'次元は {img.ndim}、サイズは {img.shape} です。')
# 画像の出力
show_image(img)
# 反転処理と処理後画像の出力
img_r = 255 - img
show_image(img_r)ndarray 型は .ndim で次元数
(number of dimensions)
が取得可能です。また、.shape
で配列の形状、つまり、各次元のサイズ
(2次元であれば行数と列数)
が取得可能です。これらは、開発中やデバッグでよく使用するので覚えておいてください。
7 NumPyを活用した高速計算
NumPy
を使用すると配列に関連する計算を高速に実行することができます。次のプログラムは
0以上1未満の乱数を 10,000,000
個生成し、それを配列に格納して平均値を求める例です。この例ではNumPyを「使わない場合」と「使う場合」の計算時間を比較しています。%timeit
は GoogleColab. または Jupyter のマジックコマンドであり、指定した行のコードの「平均実行時間」を繰り返し試行することにより計測する機能
です。
%reset -f
import numpy as np
# 10,000,000個の乱数を生成
q = np.random.rand(10_000_000)
p = q.tolist()
# リストとして平均値を計算
assert type(p) == list
%timeit sum(p)/len(p)
# ndarray として平均値を計算
assert type(q) == np.ndarray
%timeit q.mean()実行結果の一例を示します。
60.3 ms ± 835 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
7.78 ms ± 664 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)この結果から、NumPyを使用した場合、配列の平均値を計算する時間が格段に短くなっていることが分かります。これは NumPy ライブラリが「C言語」で実装されており、そこで計算が実行されているためです。
60.3 ms ± 835 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
は、「このプログラム (当該行の文) は平均して 60.3 ミリ秒で実行され
835マイクロ秒 の標準偏差があります。この計測は 7回
の試行で行われ、各試行は 10回
繰り返されました」という意味になります。
8 GoogleColab の ノートブックを GitHub にプッシュする方法
Google Colab.で作成したノートブックは、既存の GitHubリポジトリ に追加して一般公開することができます。以下に手順を示します。
- GitHubにリポジトリを作成しておきます。完全に「空」のリポジトリ
(=ブランチが存在ない状態のリポジトリ) には
GoogleColab からプッシュできないので、
README.mdなどを作成しておいてください。
- Google Colab. でノートブックを作成します。
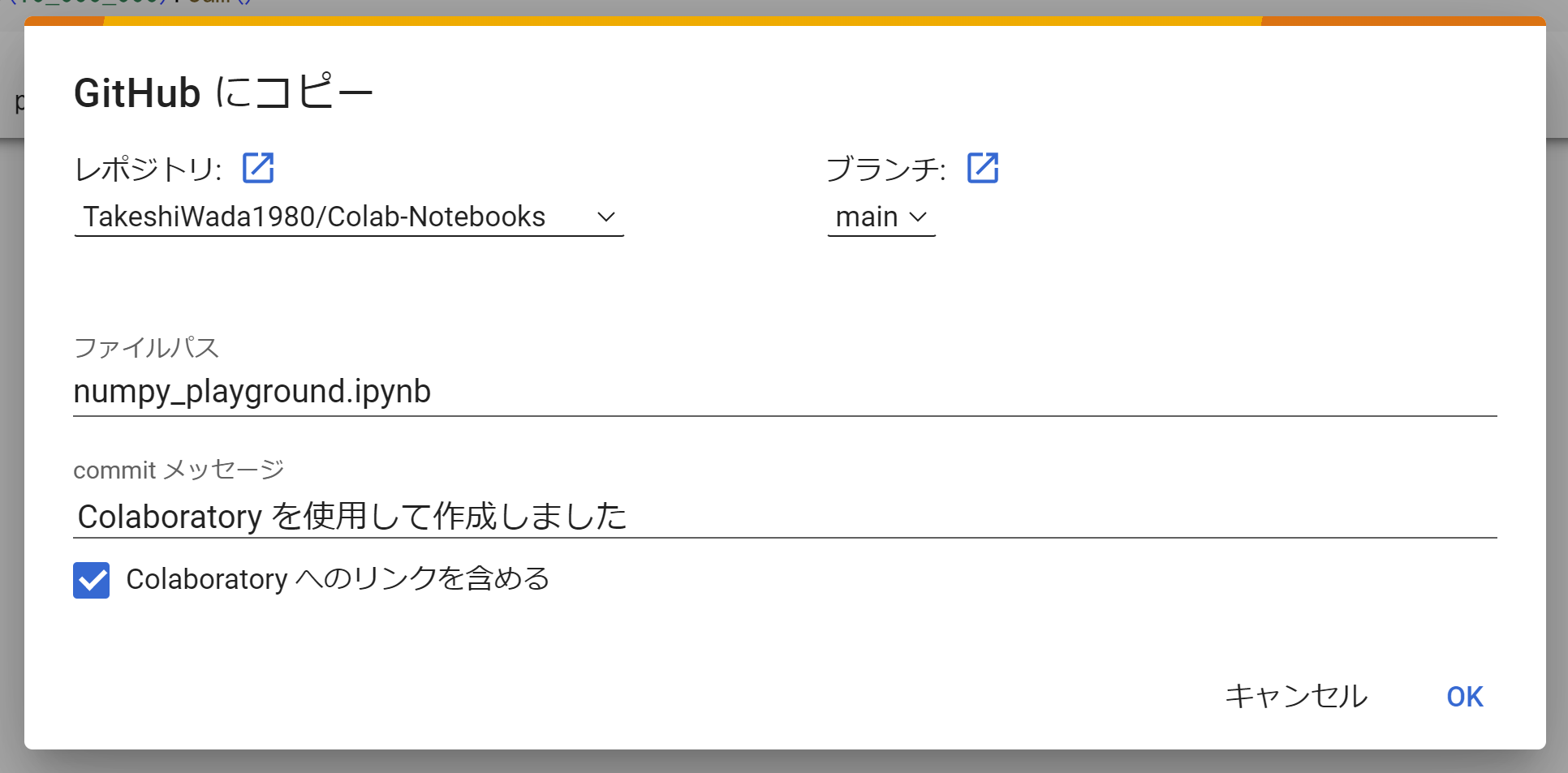
- Colab. のメニューから「ファイル」-「GitHubにコピーを保存」を選択します。なお初回時は「Colaboratory が GitHub からの認証を待機しています」と表示され、認証ダイアログが立ちあがるので認証情報を入力してください。
- ノートブックをコミット・プッシュする先の「リポジトリ」や「ブランチ」を選択し、「コミットメッセージ」を設定して「OK」を押下してください。
- コミットとプッシュに成功するとブラウザのタブが立ち上がって GitHub に移動します。
以上の手順により、GoogleColab. で作成したプログラムを GitHub で公開することができます。