1 準備
このテキストは、知能情報実験実習2 (前期) の「B班」の第6週目・07月25日 (金) の内容に関するものです。
前回のつづきの内容になります。具体的には、次の事項について学んでいきます。
- パスワードのハッシュ化
- セッションベース認証
- トークンベース認証 (JWT)
- Content Security Policy (CSP)
- Next.js ServerActions (Custom Invocation) ※おまけ
1.1 リモートリポジトリからプロジェクトの最新版を取得
リモートリポジトリ (GitHub上) でファイルが更新されています。ローカルのプロジェクトフォルダを最新版に更新するために、以下の手順で処理を実行してください。
以下の作業に失敗するときは…
現在のプロジェクトフォルダをリネームして、GitHub から再度プロジェクトをクローンしてください。
git clone https://github.com/TakeshiWada1980/web-sec-playground-1.git手順1: 前回クローンしたプロジェクトフォルダを VSCode で開いてください。
手順2: Ctrl+J
を押下して、VSCodeの下部にターミナルを表示してください。
手順3: 先週は week-5 というブランチ (≠ main
ブランチ) で作業していたはずです。もし week-5
での作業内容がコミットされていない状態で main ブランチに切り替えると、その変更が main 側のものとして扱われてしまう可能性
があります。それを防ぐため、以下の手順で、未保存のファイルを保存し、作業中の変更は全てコミットしておいてください。
git checkout week-5
# 未保存のファイルがある場合は保存してください
git commit --allow-empty -m "Finish week-5 branch"--allow-emptyを付けることで、仮に変更がなくても形式的にコミットが作成できます。
手順4: 最新の main ブランチを取得し、ローカルの
main に反映させます。
git checkout main
git fetch origin
git merge origin/mainmainブランチにローカルでの編集がなければ、コンフリクトは発生しないはずです。
手順5: プロジェクトに新しいパッケージが追加されています。依存関係を正しく反映させるために、以下のコマンドを実行してパッケージをインストールしてください。
npm i手順6: .env
という「環境変数設定ファイル」の内容を、以下のように書き換えてください。
DATABASE_URL="file:./app.db"
JWT_SECRET=ABCDEFG123456789UVWXYZJWT_SECRETは 認証機能における暗号化用のキー として使用します。安全性を確保するため、適当なランダムな英数字を用いた16文字以上の文字列に置き換えてください。文字数が不十分だと、動作時にエラーとなる可能性があります。
手順7: データベースのスキーマ (schema.prisma)
にも変更を加えています。prisma/app.db を削除後、以下を実行してください。
npx prisma db push
npx prisma generate
npx prisma db seed1.2 作業準備
ここからは week-6 というブランチを作成して、そこで作業を行なってください。
git checkout main # mainブランチであることを確認
git checkout -b week-6
git commit --allow-empty -m "Start week-6 branch"1.3 演習 30分
アプリを起動し、実際の操作とプログラムの読解を通じて 「ログイン」および「サインイン」に関する処理の理解・把握 を試みてください。詳細な解説については、このあとに行ないますが、まずは自分自身で理解に努め、疑問点や不明点を整理・明確化しておくこと が効果的な学びとなります。
以下の順序でプログラムや機能を理解・把握していくことを推奨します。ただし、あくまで目安であり、実際には 各ファイルを何度も往復しながら全体像を徐々に掴んでいく必要 があります。また、以下に示されている以外のファイルも必要に応じて参照 していく必要があります。
- ログイン
http://localhost:3000/loginsrc/config/auth.ts- このファイルで「セッションベース認証」と「トークンベース認証」を切り替えできます。
src/app/login/page.tsxsrc/app/api/login/route.ts
- ヘッダ
src/app/layout.tsxsrc/app/_components/Header.tsxsrc/app/_hooks/useAuth.tssrc/app/_contexts/AuthContext.tsxsrc/app/_contexts/sessionFetcher.tssrc/app/api/logout/route.tssrc/app/_contexts/jwtFetcher.ts
- サインアップ
http://localhost:3000/signupsrc/app/signup/page.tsxsrc/app/_actions/signup.ts
- 公開プロフィールの確認・編集
http://localhost:3000/member/aboutsrc/app/member/layout.tsxsrc/app/member/about/page.tsxsrc/app/_components/AboutView.tsxsrc/app/api/about-draft/route.tssrc/app/api/about/route.ts
2 ユーザのパスワード管理と認証/認可の機能
認証機能を備えたウェブアプリやウェブサービスを開発する場合、サーバーサイド (バックエンド) におけるユーザのパスワード管理 は避けて通れない重要な課題となります。パスワード管理を含む認証/認可の仕組みは、セキュリティの根幹であり、その適切かつ安全な実装と運用には高度な専門知識が求められます。
このような理由から、通常はフルスクラッチ (=フレームワークや既存のサービスを使わずにゼロから自前で構築すること) でアプリに認証/認可機能を実装することは推奨されていません🙅。
代わりに、ウェブアプリのフレームワークが提供する認証ライブラリ (=Next.js
であれば Auth.js (旧 NextAuth.js)、Flask であれば
flask_login など) や、クラウドサービス (Supabase、Auth0、Firebase Authentication)
などを利用することが推奨されています🙆♂️。
(プロンプト例)
Next.js の認証ライブラリ「Auth.js (@auth/nextjs)」は、どのような機能を提供してくれますか。
Next.js 開発において、Auth.js (@auth/nextjs) を利用せずに、フルスクラッチで認証/認可機能を実装することが必要になるのは、どのようなときですか。
こうした背景を踏まえ、昨年度のプログラミング3では BaaS (Backend as a Service) であるSupabaseを利用して、パスワード管理と認証の機能をアプリに組み込みました。
しかし、今回は「ウェブアプリの脆弱性評価」がテーマとなっているので、ライブラリの使用を最低限にとどめ、あえて パスワード管理と認証/認可の機能 を ゼロから実装 していたいと思います。
認証 (Authentication) と認可 (Authorization)
「認証」と「認可」は言葉として非常に似ていますが、ウェブアプリ開発の文脈では、次のように区別されるので注意してください。
- 認証 (Authentication) :
ユーザが「誰か?」また「本人であるか?」を確認するための仕組み。
- 例えば、パスワードのように「ユーザ本人しか知り得ない情報」を用いて、現在アクセスしているのが
admin@example.com本人であることを確認する処理が「認証」にあたります。
- 例えば、パスワードのように「ユーザ本人しか知り得ない情報」を用いて、現在アクセスしているのが
- 認可 (Authorization) : 認証されたユーザ (あるいは未認証のユーザ)
に対して、特定の情報や操作へのアクセスを許可するか否かを判断するための仕組み。
- 例えば、
admin@example.comとして認証されたユーザについて、/adminや/admin/posts/newに対するアクセスが許可されているかを確認し、それに応じて処理 (許可または拒否) をするのが「認可」にあたります。
- 例えば、
3 ユーザパスワードのハッシュ化
ウェブアプリに限らず、認証機能を提供するシステムでは「ユーザのパスワードは、元の文字列のまま保存せず、必ず『ハッシュ関数』で変換した値を保存する」という鉄則・大原則があります。これは、不正侵入等によって、万一、ユーザのパスワードを管理しているデータベースやファイルが漏洩 した場合でも、そこから「元のパスワード文字列」が解析され、その悪用による被害を防ぐため (=被害が発生するまでの時間を少しでも遅らせるため) です。
パスワードをハッシュ化して保存すべき理由として「たとえシステム管理者であっても、ユーザの生のパスワード文字列を閲覧できる状態にしておくべきではない」という考え方もあります。
3.0.1 定着確認
- ウェブアプリの認証機能は、セキュリティや保守性の観点から一般にフルスクラッチで実装することが推奨されている。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- ユーザのパスワードを保存する際、平文のまま保存せず、ハッシュ化して保存するのが基本的なセキュリティ対策である。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切である
- 暗号化に関する文脈で「平文」の読み仮名を答えよ。
- 答え:ひらぶん
- ユーザが本人であるかを確認する処理は、認証 (Authentication) と認可 (Authorization)
のどちらに該当するか答えよ。
- 答え:認証 (Authentication)
- パスワードをハッシュ化して保存する目的のひとつは、データベースが漏洩した場合でもパスワードの復元を困難にすることである。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切である
- ハッシュ化されたパスワードは、秘密鍵を使った復号処理によって元のパスワードに復元することができる。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- Auth.js(@auth/nextjs)は、Firebase
Authentication や Supabase のような BaaS
に分類される。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
3.1 ハッシュ関数とは
ハッシュ関数 (一方向ハッシュ関数) とは、情報2の第09回講義で学んだように「入力情報のサイズに関係なく、元の情報を推測しにくい固定長データ (ハッシュ値) を出力する関数」です。
このハッシュ関数には 入力情報が1ビットでも異なると、出力されるハッシュ値が大きく変化する という特性があります。また、ハッシュ値から元の入力を推測するには、基本的にブルートフォース攻撃(総当たり攻撃)以外に現実的な方法がない という特性があります。
代表的なハッシュ関数 (アルゴリズム) としては、MD5 (エム・ディー・ファイブ)、SHA-1 (シャー・ワン / エス・エイチ・エー・ワン)、SHA-256 (シャー・ニゴロ / シャー・ニーゴーロク) などが知られています。このうち、SHA-256 は、HTTPSのデジタル証明書の署名アルゴリズムや、ビットコイン (ブロックチェーン) の検証やマイニングに使われている信頼性の高いハッシュ関数となっています。
TypeScript において SHA-256
によるハッシュ値を求める処理は次のように記述することができます。このプログラムは、プロジェクトフォルダの
.lab/SHA-256.ts に配置しています。
import { createHash } from "crypto";
const main = async () => {
const pw1 = "password";
const pw2 = "passworD";
const pw3 = "Password-Password-Password";
// SHA-256 ハッシュを生成
const hash1 = createHash("sha256").update(pw1).digest("hex");
const hash2 = createHash("sha256").update(pw2).digest("hex");
const hash3 = createHash("sha256").update(pw3).digest("hex");
console.log(`hash1 ${hash1}`);
console.log(`hash2 ${hash2}`);
console.log(`hash3 ${hash3}`);
};
main();実行結果は、以下のようになります。
hash1 5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8
hash2 9e78de733c6a51c0cc954c1d956d8929ad1310513e1042d81edc375219c6a2ef
hash3 0df12e29bcfff3d9eb71a6c196f7cc68df7c13300748eaa77350fc582381bcd8- 上記プログラムは、何度実行しても同じ結果が得られること
(=「同じ入力」からは「同じハッシュ値」が出力されること) を確認してください。
- Python を使って SHA-256ハッシュ を計算した例をこちらに示します。実行環境が異なっていても、同じ SHA-256 ハッシュ が出力されること を確認してください。
pw1とpw2のように 入力情報が1文字違うだけ でハッシュ値 (hash1とhash2) は まったく違う値になること を確認してください。pw1とp3のように 入力情報のサイズが違う場合でも、出力されるハッシュ値が「固定長」であること を確認してください。SHA-256 は、常に 256ビット (=16進数で64文字なので \(64^{16}=2^{256}\) ) の出力となります。
理論上は、異なる入力から同一のハッシュ値が生成される可能性(これを一般に「衝突」と呼びます)がありますが、これまでに SHA-256 ハッシュ において実際に衝突が確認された例はありません。万一、衝突を発見したときは報告しましょう (有名になれます🤩)。
MD5 や SHA-1 は非推奨
MD5 や SHA-1 といった古いハッシュ関数では、すでに実際の衝突例が報告されています。
特に MD5 に関しては、2004 年に研究者によって 異なる入力から同じハッシュ値を得る手法が公開されており、暗号学的には安全性が失われた とされています。したがって、セキュリティを要する用途には MD5 は非推奨で、SHA-256 などのより安全なハッシュ関数が推奨されています。
3.1.1 定着確認
- SHA-256
は、同じ入力に対して毎回異なるユニークなハッシュ値を出力する。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- SHA-256 によって得られる出力 (ハッシュ値)
の長さは、常に【 】ビットとなる。【 】にあてはまる適切な数値を答えよ。
- 答え:256
- SHA-256 によって得られる出力 (ハッシュ値)
を16進数の文字列とした表したとき、常に【 】文字となる。【 】にあてはまる適切な数値を答えよ。
0xの接頭辞を含めずに答えよ。- 答え:64
- 衝突耐性が破られたことが確認され、暗号学的な安全性が喪失されたとして現在非推奨とされているハッシュ関数について、代表的なものを答えよ。
- 答え:MD5、SHA-1
3.2 パスワードのハッシュ化
一般に、サーバサイドにおいて、パスワードはハッシュ関数を使用して次のように管理・照合されます。
- サインアップのとき :
クライアントから受け取ったパスワードにハッシュ関数を適用し、得られたハッシュ値を
hashed_passwordとしてデータベースに保存する。 - ログインのとき :
クライアントから受け取ったパスワードにハッシュ関数を適用して得られたハッシュ値と、データベースに保存されている
hashed_passwordを照合する。
以上の仕組みにより、平文のパスワード (生のパスワード文字列) をデータベースに保存することなく、安全にパスワード認証を実現すること ができます。
また、万一、不注意やハッキングなどよって hashed_password
が漏洩しても、そこから元の平文パスワードを推測するにはブルートフォース攻撃以外の手段がない
(=膨大な時間がかかる) ため、被害の拡大
(=漏洩したIDとPWで他のウェブサービスに不正ログインすること等)
を大幅に遅らせることができます。このため、漏洩を検知した段階で速やかに「ユーザへのパスワード変更要請」などの対策を講じることで、実質的な被害を最小限に抑えることが可能となります。
(プロンプト例)
ハッシュ化したパスワードから、元のパスワードを得るためには、ブルートフォース攻撃 (総当たり攻撃) が必要であると聞きました。ブルートフォース攻撃とは何ですか?
十分な長さを持ったパスワードに対しては、ブルートフォース攻撃は「事実上成功しない」ということを分かりやすく説明してください。
3.3 パスワードのハッシュに SHA-256 が適さない理由
ここまで、SHA-256 を例にパスワードのハッシュ化について説明してきました。しかし、実際のパスワードのハッシュ化に SHA-256 を使用することは、次のような理由から非推奨となっています。
そして、SHA-256 の代わりに bcrypt や Argon2 などの「パスワード保護に特化したハッシュ関数」を使用することが推奨されています。
- SHA-256 をそのまま使うと「レインボーテーブル攻撃」に対して脆弱
- 実際に確認してもらったように SHA-256 には 「同じ入力に対して、常に同じハッシュ値を出力する」 という特性があります。この性質を利用すれば、大量のパスワードとそのハッシュ値をセットにした「レインボーテーブル」と呼ばれる辞書を作成しておくことができます。そして、攻撃者はレインボーテーブルを用いることで、(ブルートフォース攻撃よりも) 短時間でハッシュ値から元のパスワードを割り出すことが可能となります。実際、よく使用されるパスワード (例えば、英国 National Cyber Security Centre のPwnedPasswordsTop100kなど) を対象としたレインボーテーブルなどがネットから簡単に入手可能となっています。
- SHA-256 のハッシュ計算は「高速」すぎる
- SHA-256 は、「デジタル署名」や「整合性のチェック」など、高速な処理が求められる用途に向けて設計されたアルゴリズムとなっています。しかし、その高速性が「パスワードのハッシュ化」においては、逆にセキュリティ上の弱点 となってしまいます。つまり、攻撃者は、SHA-256が高速であるという性質を故に 限られた時間やマシンパワーでも効率よくパスワード候補を次々と試すこと が可能になってしまいます。特に、GPU や専用ハードウェアを用いた並列処理と組み合わせたブルートフォース攻撃 に対して、SHA-256 を使ったパスワードハッシュは脆弱になります。
(プロンプト例)
SHA-256 によるパスワードのハッシュ化はレインボーテーブル攻撃に対して脆弱だ、という説明を授業で聞きました。いまいち理解できませんでした。分かりやすく解説してください。
SHA-256でハッシュ化したパスワードに対する「ブルートフォース攻撃」と「レインボーテーブル攻撃」について計算量 (時間計算量・空間計算量) を評価してください。
3.3.1 定着確認
- パスワード認証において、ログイン時にはユーザが入力したパスワードをハッシュ化してから、保存済みのハッシュ値と照合する。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切である
- SHA-256
をパスワードハッシュ化にそのまま使うと、同じ入力に対して常に同じハッシュ値を返す性質により、ブルートフォース攻撃が成立しやすくなる。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- パスワードハッシュ化の用途において、SHA-256 よりも推奨されるアルゴリズムを挙げよ。
- 答え:bcrypt や Argon2
- パスワードのハッシュ化において、SHA-256
のような高速な処理性能は、ブルートフォース攻撃に対する耐性を高める手段として有効である。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- レインボーテーブル攻撃とは、あらかじめ大量の【 】とそのハッシュ値を対応づけた辞書を用いて、照合によって元の入力を特定する攻撃手法である。【 】にあてはまる適切な語を答えよ。
- 答え:パスワード
3.4 パスワード保護に特化したハッシュ関数
パスワードのハッシュ化には、意図的に計算処理に時間を要する設計を持ち、「GPU」や「専用ハードウェア」などによる並列処理 が難しい「bcrypt」や「Argon2」といったハッシュ関数を使用することが推奨されています。
このうち、bcrypt (ビークリプト) は、1999年に開発され、現在でも広く使われているパスワードハッシュ関数となります。2015年の Password Hashing Competition では「Argon2」とともに最終選考に残っています。bcrypt は Blowfish暗号 をベースとしており、「Cost factor」と呼ばれるパラメータで計算時間を調整 できる仕組みを持っています。
(プロンプト例)
パスワードハッシュ関数「bcrypt」の「Cost factor」とは何ですか。
Argon2 の方が bcrypt よりも「新しく安全性も高い」と評価されているのに、認証ライブラリなどでは bcrypt のほうが標準採用されることが多いのはなぜですか。
bcrypt のベースとなっている「Blowfish暗号」とは、どのような特徴を持ったものですか。
以上のことから、bcryptは 様々なウェブフレームワークやクラウドサービスの認証機能で採用されています。Supabase の認証機能でもデフォルトのパスワードハッシュ化方式として bcrypt が使用されています。
- How are passwords stored?@ Supabaseの公式リファレンスの日本語訳
Supabase Authでは、ユーザーのパスワードのハッシュを保存するために、強力なパスワードハッシュ化関数である bcrypt を使用しています。保存されるのはハッシュ化されたパスワードのみです。パスワードハッシュを使ってユーザーになりすますことはできません。セキュリティを強化するため、各ハッシュには ランダムに生成されたソルトパラメータ が付与されています。
ハッシュは
auth.usersテーブルのencrypted_password列に保存されます。この列名は誤った命名(暗号学的ハッシュ化は暗号化ではないため)ですが、後方互換性のために維持されています。
3.4.1 定着確認
- Supabase における
auth.usersテーブルのencrypted_password列に保存されているパスワードは、暗号化されたものである。この説明は「適切である」か「適切ではない」かを答えよ。- 答え:適切ではない。暗号化ではなくハッシュ化が正しい。
- 暗号化とハッシュ化の違いを説明せよ。
- 答え:略。生成AIに採点してもらって。
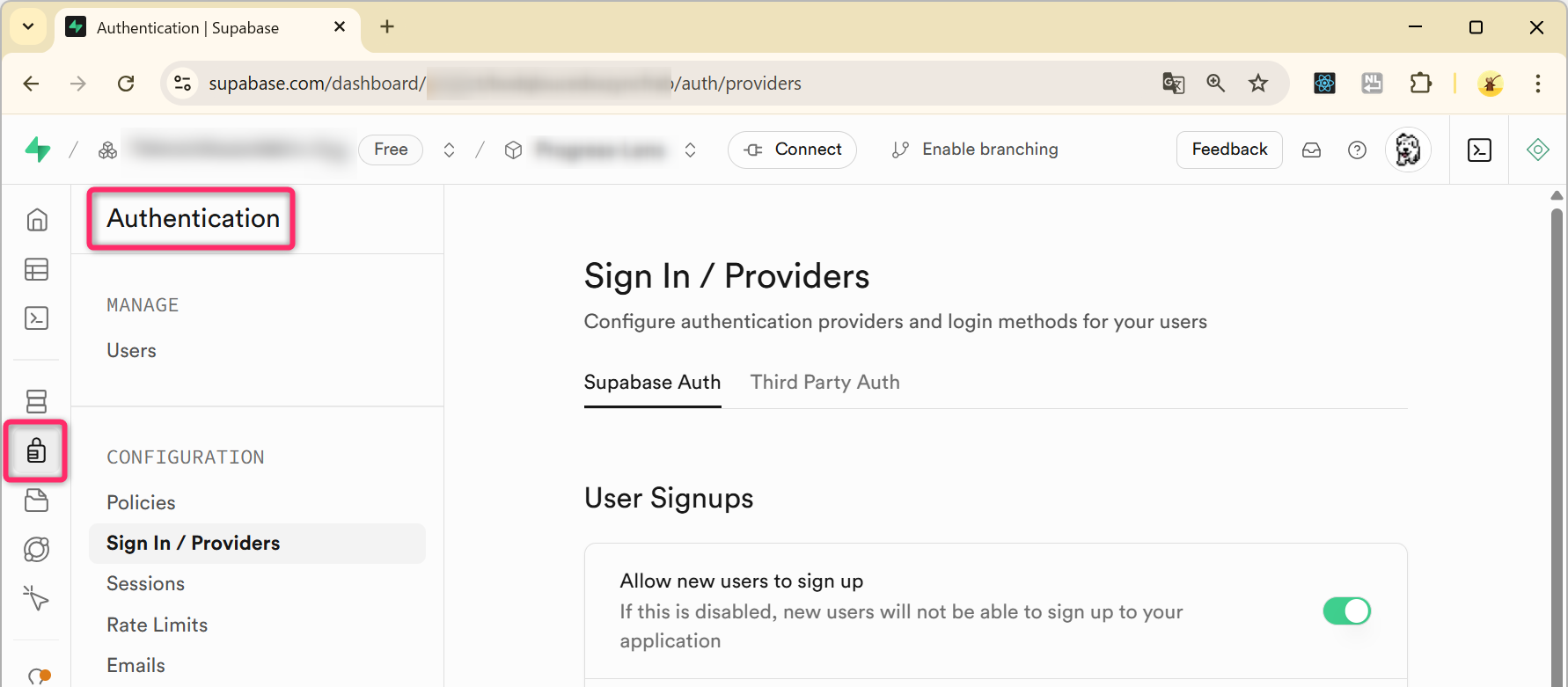
3.5 bcrypt でハッシュ化されたパスワードの確認 (Supabase)
実際にSupabaseにアクセスして auth.users
テーブルから encrypted_password 列の内容を確認してみてください。
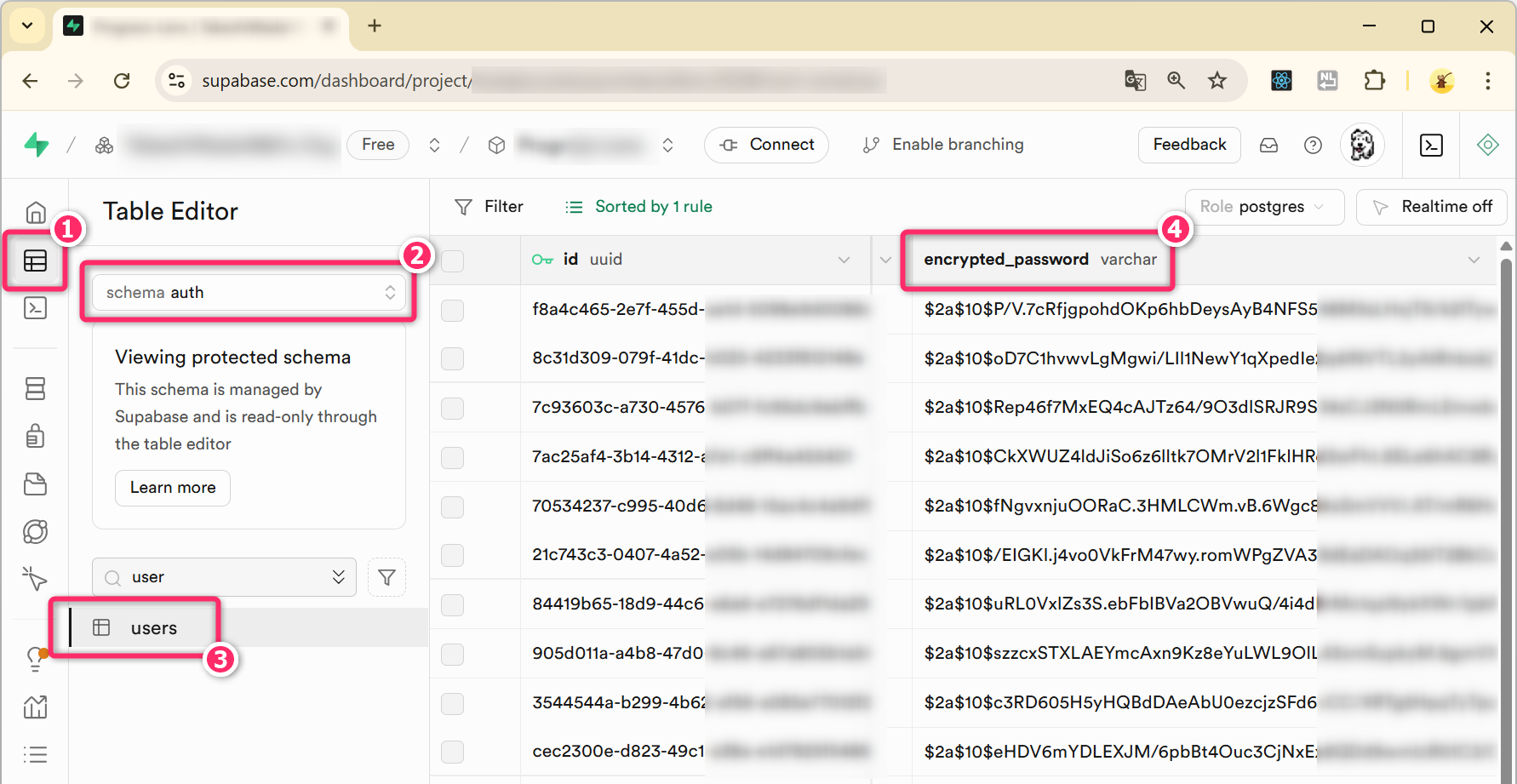
auth.users テーブルの encrypted_password
列には、以下のような文字列 (=ハッシュ化されたパスワード)
が格納されていることが確認できます。各値とも末尾から16文字分は意図的に x でマスク
(上書き) しています。
$2a$10$k7thHryjUJcy3O9Jo9hG7OepuIJVfibEuoB03xxxxxxxxxxxxxxxx$2a$10$ZRpWw4DghRAQF/zPCJr.mOZ21S9AgaLJUkUrZxxxxxxxxxxxxxxxx$2a$10$uRL0VxlZs3S.ebFbIBVa2OBVwuQ/4i4dIIrMoxxxxxxxxxxxxxxxx
この値 (=bcrypt関数によるハッシュ出力) は、次のような構成になっています。
| 部分 | 説明 |
|---|---|
$2a |
bcryptアルゴリズムの「バージョン」を表しています。$2a は、Blowfish
暗号ベースの bcrypt の「初期バージョン」であることを表しています。バージョンにより
$2b や $2y などの値が入ります。 |
$10$ |
「コストファクタ (Cost factor)」を表しています。10
であれば、2^10 = 1024
回の繰り返し計算を行うという意味になります。数値が大きいほど計算コストが増して ハッシュ化に時間 がかかるようになります (=ブルートフォース攻撃に対して強くなります)。 |
k7thHryjUJcy3O9Jo9hG7O |
「ソルト (salt)」を表しています
(詳細は後述)。 22文字のBase64エンコード文字列となります。 レインボーテーブル攻撃に対する対策になります。 |
epuIJVfibEuoB03xxxxxxxxx |
ハッシュ値の本体
を表します。 元のパスワードとソルトを元に計算したハッシュ値 (31文字)。 |
3.5.1 定着確認
- bcrypt では、Cost factor に応じてハッシュ化の処理回数が指数的に増加する。たとえば Cost
factor は「12」の場合、ハッシュ化処理は何回繰り返されるか。
- 答え:4096回 (\(2^{12}\))
- パスワードハッシュ関数として bcrypt
が推奨される理由のひとつに、GPUなどによる並列処理が困難な設計となっていることが挙げられる。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切である
3.5.2 レインボーテーブル対策の「ソルト」とは何か?
ハッシュ関数は、同じ入力に対して 常に同じ出力 (=ハッシュ値)
を生成します。そのため、A氏とB氏が、両者ともパスワードに password
という文字列を使っていた場合、同じハッシュ値 (SHA-256 の場合は
5e884898da280471... ) となってしまします。
hash("password") → 5e884898da280471...そのため、データベースのテーブルをみたとき「A氏とB氏のハッシュ値が同じ」= 「A氏とB氏は同じパスワードを使っている」=「単純なパスワードを使用している可能性が高い」
という攻撃のための足掛かりを与えてしまうことになります。また、5e884898da280471...
👉 password
という対応関係を持つため、レインボーテーブル攻撃に対して脆弱になります。
このような問題を解決するために登場するのが「ソルト」になります。
ソルト(Salt)は パスワードに付け加えるランダムな文字列 を指します。ここでのソルトは「塩」の意味で、料理に塩をひと振りするように、パスワードにひと工夫することで (=ランダムな文字列を加えることで)、ハッシュ値をユニークな値 (他とは重複しない値) にするというニュアンスがあります。
以下のようにパスワードにソルトを追加することで、同じパスワードを使っていても異なるハッシュ値 が生成されるようになります。
// A氏の場合 🧂Salt 👉 "abc123"
hash("password"+"abc123") → 25f6ec2d309a47...
// B氏の場合 🧂Salt 👉 "xyz987"
hash("password"+"xyz987") → 1700a18247a815...そして、ソルトは ユーザ毎にランダムに生成する文字列 であるため、攻撃者がレインボーテーブルをあらかじめ用意することは 事実上不可能 (非現実的) となります。
ところで、「ソルト」を導入したとき、その運用に際して次のような問題が生じます。
🤔「ソルトを使ったのはいいけど、そのソルトはどこに保管しておけばいいの?」
例えば、ユーザ情報を管理しているテーブルに password_salt
のようなカラムをつくって、そこに保管するという手法が考えられますが、それだと管理が煩雑になります。
そこで、bcrypt では「パスワードハッシュとソルトを別に保存する」という煩雑さを避けるために ハッシュ値と一緒にソルトも保存してしまう という設計を採用しています。これにより、保存すべき情報はハッシュ文字列ひとつで済み、認証時も同じソルトを自動的に再利用することが可能になります。
(プロンプト例)
サーバサイドにおけるパスワード保護に「ソルト」が有効だと聞きました。ただ、bcrypt はパスワードハッシュの文字列のなかに、平文でソルトが記述されています。ソルトを平文にしていることはセキュティ上、危険だと思うのですが、なぜ、このような設計になっているのですか🤔
注意
bcrypt や Argon2 のようなパスワード保護に特化したハッシュ関数を導入しても、パスワードが記号などを含まない数文字程度の構成であれば、ブルートフォース攻撃によって短時間で解読される可能性があります。
セキュリティの根幹となるのは、あくまで パスワード自体の「複雑さ」と「長さ」となります。これらは、パスワード設定の入力フォームのバリデーションなどで制御することが可能です。zod と正規表現を組み合わせれば比較的簡単に実装できます。
3.5.3 定着確認
- bcrypt
を使用した場合、ユーザはログインに際してパスワードとともにソルトを入力する必要がある。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- レインボーテーブル攻撃において、同じパスワードを使っているユーザのハッシュ値が同一であることは、攻撃者にとって有利に働く。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切である
- bcrypt
では、ソルトとハッシュ値を別々に管理する必要があるため、データベースには2つのカラムが必要となる。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- ソルトを使用しても、同じパスワードを使っていればハッシュ値は必ず同じになる。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
3.6 bcrypt によるハッシュ生成
Node.js / TypeScript 環境における bcrypt
を使ったパスワードハッシュの生成と、その認証のサンプルプログラムを以下に示します。このプログラムは、プロジェクトフォルダの
.lab/bcrypt.ts に配置しています。
実行するためには、ターミナルから npx tsx .lab/bcrypt.ts
を入力してください。
import bcrypt from "bcryptjs";
const main = async () => {
const pw1 = "password";
const pw2 = "password"; // 同じパスワード
// パスワードからハッシュを生成
const hash1 = await bcrypt.hash(pw1, 10);
const hash2 = await bcrypt.hash(pw2, 10);
// ハッシュを表示 (同じパスワードでもソルトが異なるため、ハッシュは異なる)
console.log(`hash1 ${hash1}`);
console.log(`hash2 ${hash2}`);
// パスワードの検証 (パスワードとハッシュを比較)
// 第1引数が「パスワード」、第2引数が「ハッシュ値」
// 同じパスワードであれば true、異なるパスワードであれば false
const isPasswordValid1 = await bcrypt.compare("password", hash1);
const isPasswordValid2 = await bcrypt.compare("password", hash2);
const isPasswordValid3 = await bcrypt.compare("hoge!hoge!", hash1);
console.log("isPasswordValid1 => ", isPasswordValid1);
console.log("isPasswordValid2 => ", isPasswordValid2);
console.log("isPasswordValid3 => ", isPasswordValid3);
};
main();実行結果の一例を示します。ソルトは毎回ランダムに生成されるため、コンソール出力の 第01行目 と 第02行目 は実行毎に値が変化することに注意してください。
hash1 $2b$10$wY.L4KV4poYRZNQrrRFcGuri/Nc.S0MXhl/lszfzcnWyKJ/XXskv2
hash2 $2b$10$lHgbtPJgku5.HmROQDEkCebWkbSIkZ7gyNYQUg327Lv8NptGI1Tga
Match true
Match true
Match falsebcrypt.hash関数に、パスワード (平文) と、コストファクタを与えることで、ランダム生成されたソルトを使ったパスワードハッシュが得られることを確認してください。bcrypt.compare関数を使うことでパスワードの照合が簡単にできることを確認してください。- コストファクタを大きな値 (例えば
15~18ぐらい) に設定すると、ハッシュの「生成」や「検証 (比較)」に体感できるレベルで時間がかかることを確認してください。- bcrypt では、コストファクタを1増やすと、計算時間が 約2倍 になります。
bcryptjs の詳細についてはhttps://www.npmjs.com/package/bcryptjsを参照してください。
(プロンプト例)
Supabase が提供する認証機能では、パスワードハッシュに bcrypt を利用しているということで、その出力は
$2a$10$...のようになっていました。一方で、bcryptjsでパスワードハッシュを生成したら$2b$10$...のようになっていました。$2a$や$2b$はバージョンの違いということですが、両者では具体的にどのような違いがありますか。また、異なるバージョンで互換性はありますか。
Node.js では、パスワードハッシュのライブラリとして
bcryptjsとbcryptがありますが、両者の違いを教えてください。どちらを使うべきですか🤔
3.7 演習
現在、プロジェクトでは、ユーザのパスワードを平文のままデータベースに保存し、それを利用してログイン認証を行なっています。これを bcrypt を使って、安全にパスワードを管理するように改修してください。
主に、以下のファイルの変更が必要になります。
改修後は、データベースのシーディング処理 (npx prisma db seed)
を再実行し、シーディングに含まれるユーザのログイン処理が正常にできることを確認してください。また、新規ユーザのサインアップ
(/signup) およびログインが問題なく機能することを確認してください。
4 ユーザ認証機能
前回の実験実習でも確認したようにウェブサーバは、基本的に ステートレスなシステム (=状態を持たない/状態を保持しない仕組み) となっています。これは「バックエンドは、リクエストごとに独立して処理が完結するように実装しなければならない」ということになります。
重要なポイント
バックエンド処理のなかでデータベースに保存しなかった情報 (例えば、変数に格納した値など) は、以降のリクエスト処理に引き継がれません。仮にデータベースに保存した場合でも、以降のリクエスト処理のなかで参照したい場合は 明示的にデータベースから読み込み処理をする必要 があります。
例えば、Next.js の バックエンド処理 (=src/app/api 以下に記述する処理)
において、あるリクエストを受けて、以下のように変数に値をセットしても…
userName = "寝屋川タヌキ"isAuthenticated = true
… 次のリクエストを処理するときには userName や isAuthenticated
の内容は リセット されています
(これが「ステートレスである」ということです)。これは userName や
isAuthenticated が「グローバル変数」であっても同じ です。
バックエンドの実行環境は、リクエストごとに新しく立ち上がる可能性があるため、グローバル変数であっても値が残っていることは保証されません。これは、特に「Vercel」のようなサーバレス型のホスティングサービス環境において顕著になります。
また、大規模なシステムでは、負荷分散のための仕組みとして、処理が複数の実行環境に振り分けられることがあるため、グローバル変数に一時的に保存しても、それが次の処理で使えるとは限りません。
以上のように、ウェブがステートレスなシステムである以上、バックエンドではリクエストごとに「毎回」認証・認可に関する判定処理を行なう必要があります。
そして、それに対応するかたちで、クライアント側でも (原理的には) すべてのリクエストに認証情報を含めて送信する必要 があります。しかし、たとえ HTTPS によって通信が暗号化されていたとしても、「ID + パスワード」という極めて機密性の高い情報を何度も送信すること は、潜在的なセキュリティリスクとなるため避けたいという問題があります。
4.1 「セッションベース認証」と「トークンベース認証」
そこで、バックエンドでは「ID」と「パスワード」を使った認証が済んだユーザに対しては、「トークン (Token)」と呼ばれる 「期限付きの一時的な会員証のようなもの を発行し、クライアントに渡します。そして、以降は、その「トークン」を用いてリクエスト毎の認証・認可処理を行なう という仕組みが、広く採用されています。
トークンとは
トークン (Token) というのは聞きなれない言葉で「イメージしずらい」と思います。トークンは、本人確認を行なったあとに発行される「期限付きの一時的な会員証」のようなものと考えてください。
たとえば、ネットカフェを初めて利用するときは、マイナンバーカードや免許証を用いて厳密に本人確認が行なわれます。しかし、その手続きが済むと「会員証」が発行され、以降はその会員証を持参・提示するだけでネットカフェを利用できるようになります。この「会員証」があることで 紛失すると大変なことになるマイナンバーカードや免許証を毎回持ち歩かずに済む というメリットがあります。
トークンとは、そのような存在だと考えてください。
以上のようにして発行される「認証トークン」については、
- トークンに記載される内容
- サーバー側でトークンをどのように照会・検証するか
- クライアントがどのようにトークンをサーバーへ送信するか
…といった設計の違いによって、代表的な2つの認証方式である 「セッションベース認証」と「トークンベース認証」 に分類されます。
例えば、プログラミング3では Supabase を利用した認証・認可の機能を実装しましたが、これは 「JWT を使ったトークンベース認証」 が用いられていました。実は。
この実験実習の教材web-sec-playground-1は、「セッションベース認証」と「トークンベース認証」を比較しながら違いを理解できるように、両者を切り替えられる設計となっています。
// ▼▼ 認証モードにあわせていずれかを有効にする
const AUTH_MODE = "session" as "session" | "jwt";
// const AUTH_MODE = "jwt" as "session" | "jwt";
// 認証モードの設定 (ここは変更しない)
export const AUTH = {
mode: AUTH_MODE,
isSession: AUTH_MODE === "session",
isJWT: AUTH_MODE === "jwt",
} as const;4.2 セッションベース認証の概要
セッションベース認証は、昔から利用されている典型的な認証方式になります。なお、ここでの「セッション」とは、サーバー側がユーザごとのログイン状態や一時的な情報を識別・管理するために用いる仕組みのことです。
このセッションベース認証に用いられる「トークン」には セッションIDのみ (=UUIDのような推測困難なランダム文字列のみ) が記載されます。たとえるなら、会員証に 「会員番号」だけ が印字されているイメージです。
初回のログイン処理と、以降の認証認可のプロセスは次のようになります。
4.2.1 [1] サーバ側:ログインリクエストの処理
クライアントからログインリクエストが送られてきたら、まず id や
password を使ってユーザ認証を行ないます。認証に成功したら
セッションID (=ランダムなUUID)
を生成し、それをキーとして「ユーザID」や「セッションIDの有効期限」などをデータベースに保存します。そして
Set-Cookie
ヘッダに「セッションID」をセットしてクライアントにレスポンスを返します。
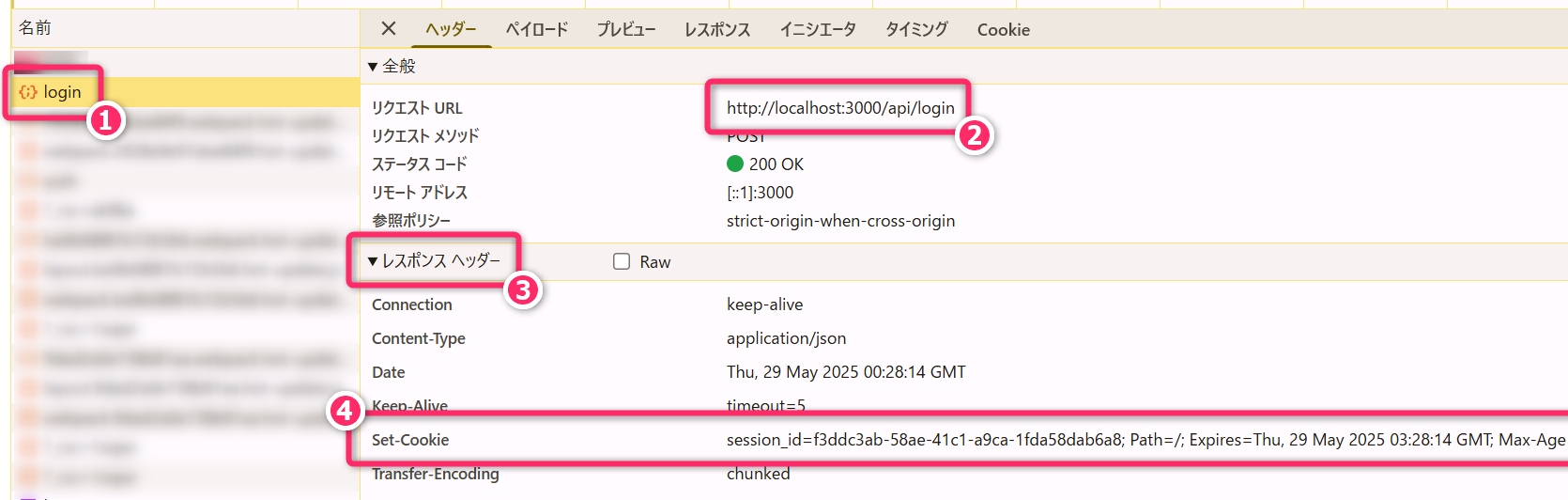
4.2.2 [2] クライアント側:ログインレスポンスの処理
ブラウザは、サーバからのレスポンスに含まれる Set-Cookie
ヘッダを自動的に読み取り、ドメインと紐付けて「セッションID」を保存します。
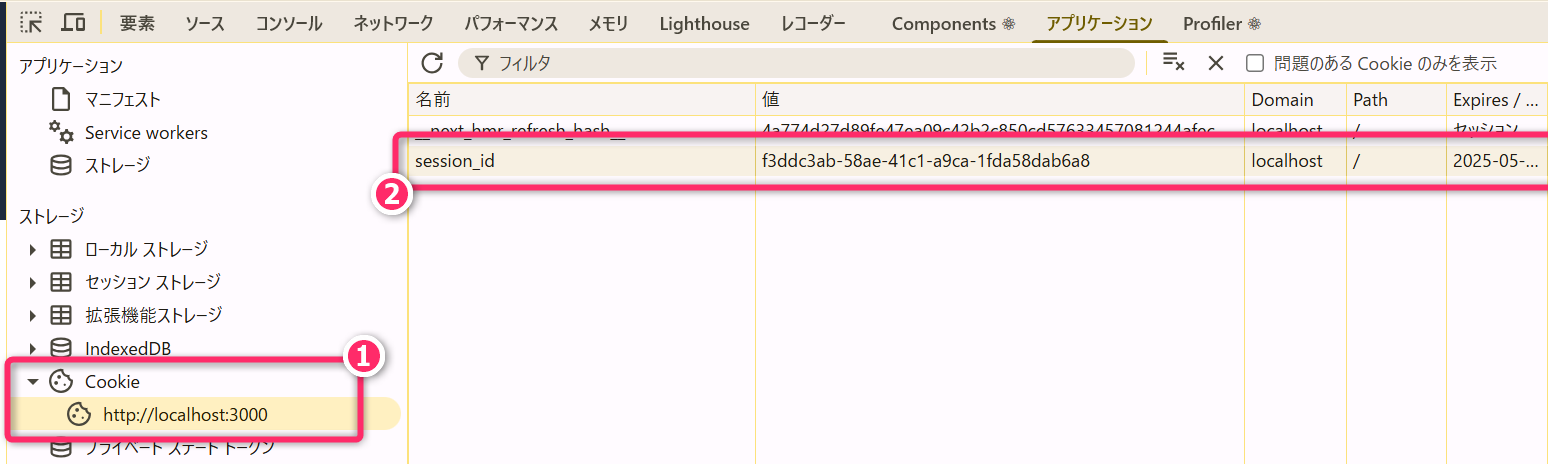
4.2.3 [3] クライアント側:ログイン後のリクエスト送信処理
以降、サーバのリソースにアクセスする際
(例えば、ユーザがリンクを押下したときや、JavaScriptから fetch
を実行したとき)、ブラウザは自動的に Cookie
ヘッダに「セッションID」をつけたHTTPリクエストを送信するようになります。
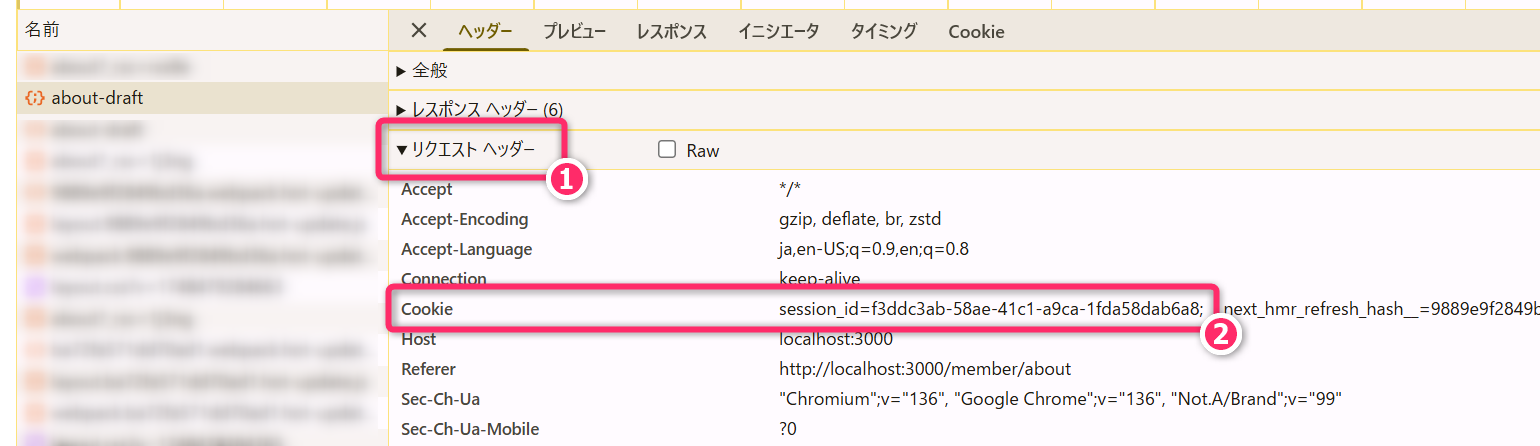
4.2.4 [4] サーバ側:リクエストに対する認証・認可の処理
リクエストのCookie
ヘッダから「セッションID」を読み取り、それをキーとしてデータベースから「ユーザID」などを取得します。
もし、対応する「ユーザID」が存在しなかったり、存在していても 「セッションIDの有効期限」が切れている場合 は、認証失敗とします (必要に応じてログインページにリダイレクトさせたりします)。
そうでなければ、認証成功として、そのユーザの「ID」や「ロール」に基づいてバックエンドの処理 (データベースの CRUD 処理など) を行ない、その結果をレスポンスします。
CRUD: 「Create (作成) 」「Read (読み取り)」「Update (更新)」「Delete (削除)」
4.2.5 [5] ログアウト処理
サーバ側で、[1] で作成した「セッションID」とユーザ情報を紐付けていたレコードを削除します。これにより、今後、この セッションID が使われても、該当するユーザ情報が取得できなくなります。
さらに、クライアント側の Cookie
に保存されている「セッションID」を削除 するため、Set-Cookie ヘッダに
Max-Age=0
属性を設定したレスポンスを返します。これによって、ブラウザに保存されていた Cookie
は即座に無効となり、以降のリクエストでは Cookie
として「セッションID」が送信されなくなります。
(プロンプト例)
Cookie を削除したいときに、
Max-Age=0を設定した Cookie をレスポンスのSet-Cookieヘッダにセットするのはなぜですか。
以上のように、セッションベース認証では、トークンの内容は「セッションID」のみで、それを Cookie を利用して送受信します。また、ユーザ認証は、サーバ側でデータベースに問い合わせること (=「セッションID」をキーとして「ユーザID」や「セッションIDの有効期限」を照会すること) で行ないます。
セッションベース認証の「課題」は、認証処理のたびに必ずデータベースへ問い合わせる必要があるという点です。 一般に、サーバー処理の中でデータベースアクセスは比較的コストが高く、システム全体の処理速度を下げる要因(=ボトルネック) となる可能性があります。
4.2.6 定着確認
- セッションベース認証において、ログイン時に発行される「トークン」には、ユーザ名やロールなどのユーザ情報が直接的に含まれている。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- セッションベース認証では、ログイン後のリクエストにおいてクライアントは自動的にセッションIDを送信する。これは、通常、何という
HTTPヘッダ にセットされて送信されるか?
- 答え:
Cookie
- 答え:
- 通信量の削減とデータベース照合処理の高速化・効率化のため、セッションIDはできるだけ短く単純な文字列である方が望ましい。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- セッションベース認証において、クライアント側では JavaScript を使って
Set-Cookieヘッダのデータを読み取り、Cookie に保存する必要がある。この説明は「適切である」か「適切ではない」かを答えよ。- 答え:適切ではない
- セッションベース認証の課題のひとつは、すべての認証処理においてデータベースアクセスが必要となる点である。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切である
4.3 トークンベース認証 (JWT) の概要
トークンベース認証は、近年になって広く使われるようになった認証方式になります。特に
フロントエンドとバックエンドが分離されたSPA (Single Page Application)
や、IoTシステム
などでは主流な認証方式となっています。この認証方式の特徴は、IDとパスワードによる認証が成功したユーザについて、そのユーザの情報 (たとえば「id」「name」「role」など) と
改竄防止の署名
を内包した「トークン」を発行し、それをクライアント側に渡してしまう点にあります。
トークンには、例えば以下のような任意の情報を含めることができます。イメージとしては、「会員証」に 「会員番号」「氏名」「会員ランク (ブロンズ/シルバー/ゴールド) 」「有効期限」など が印字されているイメージです。
id(ユーザID)email(ログインID)name(表示名)role(ADMINorUSERのような権限)exp(トークンの有効期限)
このような情報を「JWT (JSON Web Token)」と呼ばれるフォーマットでまとめ、仮に内容が改竄 された場合でもサーバ側で検出できるような 署名(Signature) を付加し、それをトークンとします。
トークンベース認証の初回のログイン処理と、以降の認証認可のプロセスは次のようになります。なお、トークンベース認証 (Supabaseの認証機能を利用したもの) については、プログラミング3の第11回講義で、既に学んでいる内容です (実際に課題として実装もしてもらっています)。
4.3.1 [1] サーバ側:ログインリクエストの処理
クライアントからログインリクエストが送られてきたら、まず id や
password
を使ってユーザ認証を行ないます。認証に成功したら、そのユーザに対応する情報(id,
name, role など)を含む「JWT」を作成し、それを
レスポンスのボディ としてクライアントに返します。
- JWT には、サーバだけが参照可能な「秘密鍵」 を使って改竄検出のための署名をします。
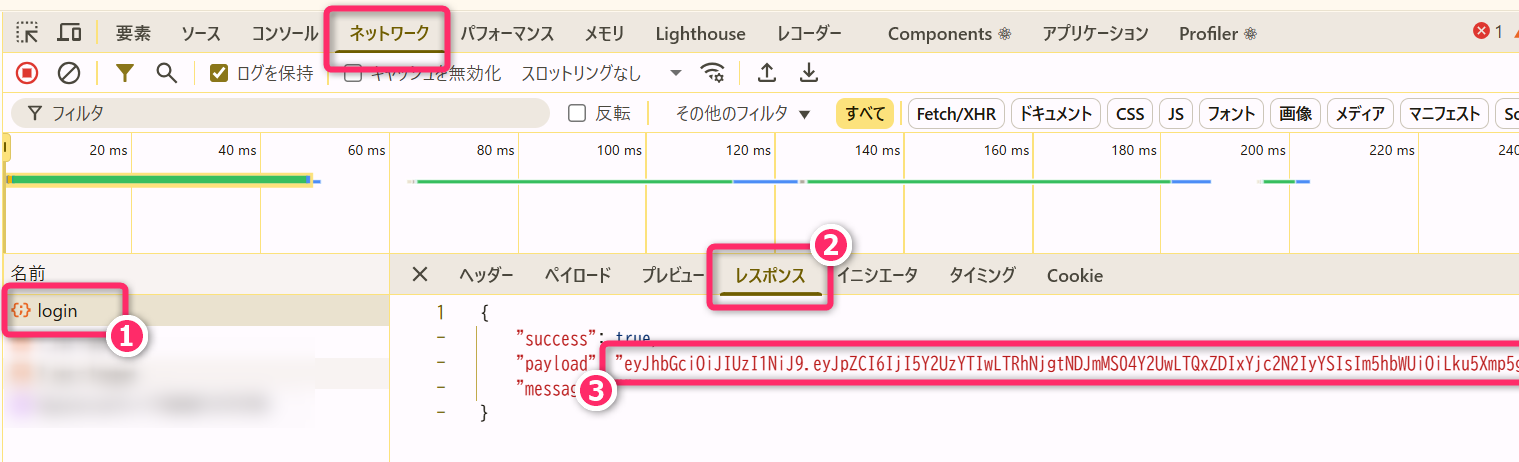
上記の eyJhbGciOiJIUzI1NiJ9... が JWT
となります。Base64でエンコードされているため分かりづらいですが、ユーザの id や
email などの情報が内包されています。
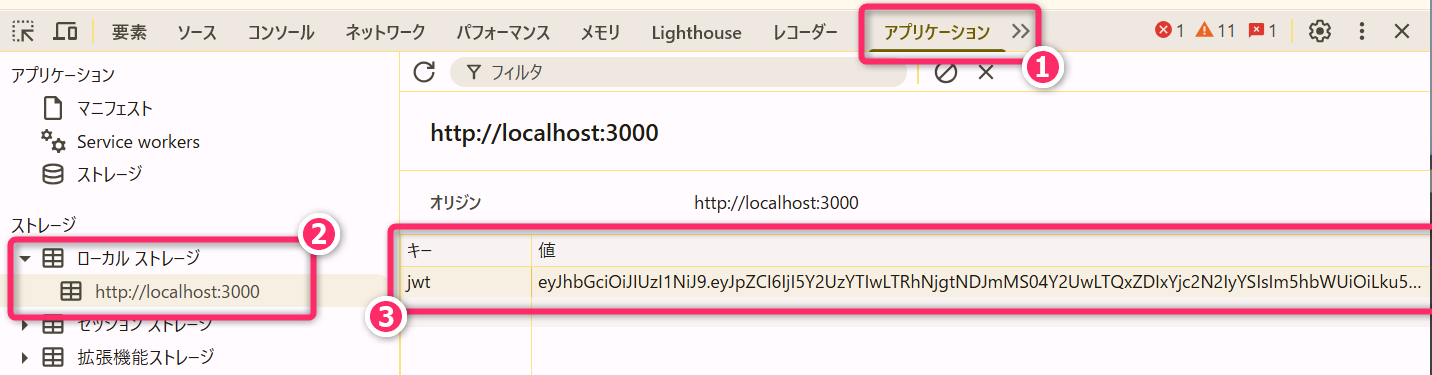
4.3.2 [2] クライアント側:ログインレスポンスの処理
ログイン処理のレスポンスとして JWT を受け取ったクライアントは、それを手動で ウェブブラウザの LocalStorage (または SessionStorage) のなかに保存します。
- LocalStorage (ローカルストレージ) については、プログラミング3の第05回講義で既に学習済みです。
(プロンプト例)
ウェブアプリ開発で、以前に LocalStorage は使用したことがあります。さきほど、SessionStorage という言葉を聞きました。なんですかこれ?
4.3.3 [3] クライアント側:ログイン後のリクエスト送信処理
ユーザ認証が必要な URI
にアクセスする際、先ほどローカルストレージに保存しておいた「JWT」を
HTTPリクエストの Authorization ヘッダに付けて送信します。
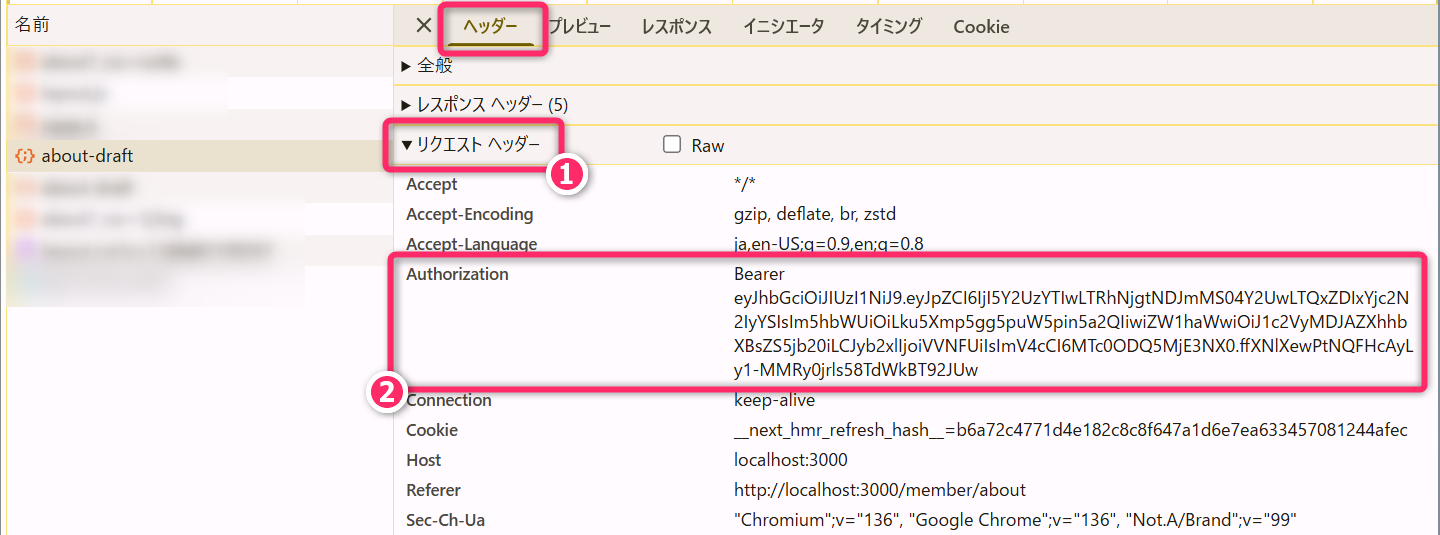
Authorizationヘッダは、自動付与される Cookie とは違って JavaScriptで明示的にセットする必要があります。
const ep = "/api/about-draft"
const jwt = localStorage.getItem("jwt");
const headers: HeadersInit = {};
if (jwt) headers["Authorization"] = `Bearer ${jwt}`;
const res = await fetch(ep, {
credentials: "same-origin",
cache: "no-store",
headers,
});(プロンプト例)
JWTによるトークンベースの認証システムを開発しています。HTTPリクエストの Authorization ヘッダに指定する
Bearerってなんですか?Authorization: <JWT>ではなくAuthorization: Bearer <JWT>にする理由って何ですか?🤔
4.3.4 [4] サーバ側:リクエストに対する認証・認可の処理
サーバ側では、リクエストヘッダに含まれた JWT
を受け取り、(サーバだけが参照可能な秘密鍵を使って) その署名を検証 (=JWT の内容が不正に改竄されていないことの確認) します。署名が正しく、かつ
JWT の有効期限が切れていなければ、トークンに含まれる id や role
が正しい情報であると見なして、その情報を使って認証や認可を行ないます。
署名検証に失敗すれば、内容が改竄されていると判断して、ログインページにリダイレクトさせたりします。
- この [4] のプロセスのなかでは データベースに対するアクセス が発生していないことに注意してください。
4.3.5 [5] ログアウト処理
クライアント側において、JavaScript を使って LocalStorage のなかの JWT を削除します。
以上のように、トークンベース認証では、ログイン処理以外ではデータベースに問い合わせることなくユーザの認証・認可を行なうことができます。また、「JWT」という自己完結型トークンの特性を活かして、クライアント側でも、LocalStorage
の JWT から name や role を読み込み、それに応じた UI
を提供することが可能になります。
なお、トークンが一度漏洩すると第三者でも署名の内容が有効なうちは自由にアクセスできてしまうため、トークンの保存場所や取り扱いには細心の注意が必要
となります。特に LocalStorage は、Cookie
の「HttpOnly属性」のような設定ができないので、XSS攻撃
を受けると、JWTは簡単に流出してしまいます。
(プロンプト例)
Next.js を使ったウェブアプリ開発について学んでいます。いま、JWTを使ったトークンベース認証についての解説を読んでいるのですが、そこに「JWTという自己完結型トークンの特性を活かして、クライアント側でも、LocalStorage の JWT から
nameやroleを読み込み、それに応じた UI を提供することが可能になります。」と書いてありました。意味が分かりません😭。特に「nameやroleを読み込み、それに応じた UI を提供する」ってどういうことですか?
トークンベース認証では、JWT を LocalStorage に保存することが多いようですが、HttpOnly属性 をつけて
Set-Cookieで JWT をサーバから送ってもらったら、XSS対策もできて超安全だと思います。JWT を LocalStorage に保存しておくと嬉しい理由って何なんですか🤔。UI/UX に関連してのメリットでもあるのですか?
4.3.6 定着確認
- JWT (JSON Web Token)
には改竄検出のために「署名」が含まれており、この署名はサーバ側だけが知っている「秘密鍵」を用いて生成される。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
- JWTを LocalStorage に保存した場合、JavaScript から自由に読み書きできるが、LocalStorage
に保存する際に「HttpOnly属性」を設定すれば、JavaScript からの参照が制限されて XSS対策
となる。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない。「HttpOnly属性」は Cookie に設定するもので、LocalStorage にそれに相当するものはない
- JWT によるトークンベース認証において、トークンに含まれる
roleの値をもとに、フロントエンドで表示内容を変えるようなUI制御が可能である。この説明は「適切である」か「適切ではない」かを答えよ。- 答え:適切である
- JWTをHTTPリクエストで送信する際は、Authorization ヘッダに
Bearer <JWT>の形式で明示的に設定する必要がある。この説明は「適切である」か「適切ではない」かを答えよ。- 答え:適切である
- JWTの署名に使われる秘密鍵はクライアントにも配布されており、署名検証はクライアント側でも可能である。この説明は「適切である」か「適切ではない」かを答えよ。
- 答え:適切ではない
4.4 JWT のデコード
JWT は「JSON Web
Token」の略であり、その名前のように本質的には「JSON形式のデータ」となっています。しかし、HTTP
リクエストの Authorization ヘッダにセットして送信する都合で Base64 形式でエンコード (符号化)
されています。そのため、`eyJhbGciOiJIUzI1NiJ9... のような
一見すると意味不明な文字列 となっています。
(プロンプト例)
JWTの勉強をしていて「Base64エンコード」という言葉がでてきたのですが、これは何ですか?「Authorizationヘッダにセットする都合でBase64にエンコードされている」って書いてありましたが、それって「どんな都合」ですか😅
… とはいえ、JWT は Base64 でデコード (復号化) すれば 元のJSON形式に戻すことができ、その内容を確認すること ができます。デコードは、プログラムでも可能ですが、以下のサイトでも簡単にデコードして JWT の内容を確認することが可能です。
各サイトで、実際に以下の「JWT」を貼り付けてデコードしてみてください。
eyJhbGciOiJIUzI1NiJ9.eyJpZCI6IjI5Y2UzYTIwLTRhNjgtNDJmMS04Y2UwLTQxZDIxYjc2N2IyYSIsIm5hbWUiOiLku5Xmp5gg5puW5pin5a2QIiwiZW1haWwiOiJ1c2VyMDJAZXhhbXBsZS5jb20iLCJyb2xlIjoiVVNFUiIsImV4cCI6MTc0ODQ5MjE3NX0.ffXNlXewPtNQFHcAyLy1-MMRy0jrls58TdWkBT92JUw4.5 JWT 生成・デコード・署名検証を行なうプログラム
Node.js / TypeScript 環境において、JWT の生成
(署名付き)、Base64デコード、改竄されていないこと/有効期限を過ぎていないことを確認するための検証
(確認) を行なうサンプルプログラムを以下に示します。jose
というライブラリを使用しています。
このプログラムは、プロジェクトフォルダの .lab/jwt-1.ts
に配置しています。npx tsx .lab/jwt-1.ts で実行することができます。
import { SignJWT, jwtVerify, decodeJwt } from "jose";
// JWTの秘密鍵 (通常は環境変数として設定して、そこから取得する)
const JWT_SECRET = "ABCDEFG123456789UVWXYZ";
const main = async () => {
// JWTのペイロード (本体のデータ)
const payload = {
id: "12345",
name: "寝屋川タヌキ",
role: "USER",
};
const secret = new TextEncoder().encode(JWT_SECRET);
const tokenMaxAgeSeconds = 5; // トークンの有効期限(秒単位) 5秒!
const expiresAt = new Date(Date.now() + tokenMaxAgeSeconds * 1000);
// [1] JWTの生成
const jwt = await new SignJWT({ ...payload })
.setProtectedHeader({ alg: "HS256" })
.setExpirationTime(expiresAt)
.sign(secret);
console.log(`[1] JWT: ${jwt}\n`);
// [2] JWTのデコード (署名を検証せずにペイロードを取得)
const decoded = decodeJwt(jwt);
console.log(`[2] Decoded : ${JSON.stringify(decoded, null, 2)}\n`);
// [3] JWTの有効期限を確認
const now = new Date();
const expirationDate = new Date(decoded.exp! * 1000);
const toJST = (date: Date) =>
date.toLocaleString("ja-JP", { timeZone: "Asia/Tokyo" });
console.log(`[3a] Current Date: ${toJST(now)}`);
console.log(`[3b] JWT Expiration Date: ${toJST(expirationDate)}\n`);
// [4a] JWTの検証1
try {
const verified = await jwtVerify(jwt, secret);
console.log(`[4a] Verified : ${JSON.stringify(verified, null, 2)}\n`);
} catch {
console.error("[4a] JWT verification failed.");
}
// JWTの有効期限が切れ待ち (10秒待機)
const wait = 10;
process.stdout.write(`Waiting for ${wait} seconds... `);
for (let i = 0; i < wait; i++) {
await new Promise((resolve) => setTimeout(resolve, 1000));
process.stdout.write(".");
}
console.log("\n");
// [4b] JWTの検証2 (有効期限切れのJWTを検証) → 失敗するはず
try {
const verified = await jwtVerify(jwt, secret);
console.log(`[4b] Verified : ${JSON.stringify(verified, null, 2)}\n`);
} catch {
console.error("[4b] JWT verification failed.");
}
};
main();4.5.1 演習
- 上記のプログラムを実行し、その結果を確認しながらプログラムを読解・理解してください。
.lab/jwt-2.tsは、JWTに対する改竄を検知する実験 のプログラムなります。こちらについても、同様に読解・理解をしてください。
4.6 比較
「セッションベース認証」と「トークンベース認証」について簡単に比較すると次のようになります。
| 観点 | セッションベース認証 | トークンベース認証 (例: JWT) |
|---|---|---|
| トークンの送信方法 | HttpRequest の Cookie 属性には HttpOnly と Secure を設定 |
HttpRequest の HeaderAuthorization: Bearer <JWT> |
| トークンの記載内容 | セッションIDのみを含む | JWT (JSON Web
Token)id、name、role、exp (有効期限)
などの任意の情報を 署名付き で含む |
| サーバー側での照会・検証方法 | セッションIDをキーにデータベースから情報を取得して検証 | トークンの署名を検証 して内容の正当性を確認 |
5 セッションベース認証の詳細
教材ウェブアプリを「セッションベース認証」で動作させるためには
src/config/auth.ts を以下のように設定してください。
5.1 演習
以下の参考に、セッションベース認証の処理 (実装) について読解してください。
5.1.1 サーバ側:ログインリクエストの処理
src/app/api/login/route.ts第59行目~src/app/api/_helper/createSession.ts
5.1.2 クライアント側:ログインレスポンスの処理
- ブラウザが自動で処理するため明示的なプログラムは不要
5.1.3 クライアント側:ログイン後のリクエスト送信処理
- ブラウザが自動で処理するため明示的なプログラムは不要
5.1.4 サーバ側:リクエストに対する認証・認可の処理
src/app/api/about-draft/route.ts第15行目~、第25行目~
src/app/api/_helper/verifySession.ts
5.1.5 ログアウト処理
src/app/_components/Header.tsx第14行目src/app/_contexts/AuthContext.tsx第39行目~src/app/api/logout/route.ts
6 トークンベース認証の詳細
教材ウェブアプリを「トークンベース認証」で動作させるためには
src/config/auth.ts を以下のように設定してください。
6.1 演習
以下の参考に、トークンベース認証の処理 (実装) について読解してください。
6.1.1 サーバ側:ログインリクエストの処理
src/app/api/login/route.ts第68行目~src/app/api/_helper/createJwt.ts
6.1.2 クライアント側:ログインレスポンスの処理
src/app/login/page.ts第102行目~
6.1.3 クライアント側:ログイン後のリクエスト送信処理
src/app/member/about/page.tsx第63行目~
6.1.4 サーバ側:リクエストに対する認証・認可の処理
src/app/api/about-draft/route.ts第15行目~、第25行目~
src/app/api/_helper/verifyJwt.ts
6.1.5 ログアウト処理
src/app/_components/Header.tsx第14行目src/app/_contexts/AuthContext.tsx第39行目~
7 Content Security Policy (CSP)
CSP (Content Security Policy) は、ウェブページに読み込ませるコンテンツの「種類」や「読み込み元」 を制限するためのセキュリティ機能となります。XSS攻撃 (クロスサイトスクリプティング攻撃) や、意図しない外部リソースの読み込みを防ぐために使用されます。
通常、CSP は HTTPレスポンス の Content-Security-Policy
として設定します。HTML の <meta>
タグで指定することもできますが、すべてのポリシーが有効になるわけではなく、また適用のタイミングにも制限があるため、CSP
はヘッダで指定することが基本となります。
たとえば、次のような Content-Security-Policy
ヘッダが、HTTPレスポンスに設定されていたとします。
Content-Security-Policy: default-src 'self'; script-src 'self' https://example.comこのとき、「ウェブブラウザ」のセキュリティ機能によって、次のような制限が働きます。
default-src 'self'の指定により、画像やフォントなどのリソースが 自分自身(=同じオリジン)からしか読み込めなくなり、それ以外の場所からの読み込みはブラウザによってブロックされます。例えば、この設定では Googleフォント は利用できなくなります。script-src 'self' https://example.comの指定により、JavaScriptファイルは 同一オリジン またはhttps://example.comから読み込まれたものだけが実行可能になります。
これ以外にも、CSP には様々な設定が可能です。script-src ‘self’ https://example.com を指定すると、JavaScriptファイルは 同一オリジン または https://example.com から読み込まれたものだけが実行可能になります。
(プロンプト例)
CSP として、レスポンスヘッダに
Content-Security-Policy: default-src 'self'を設定したら、Googleフォントが機能しなくなってしまいました。どのようにすればよいですか。
ウェブアプリを開発しています。CSP (Content Security Policy) には、どのような項目があり、それによってどのようなセキュティ設定ができますか。分かりやすく解説してください。
CSP を適切に設定すれば、仮に「サニタイズ処理」や「エスケープ処理」に不備があったとしても、XSS攻撃のような「外部からの悪意あるスクリプトの実行」を防ぐことができます。しかし、XSS対策は、ブラウザのセキュリティ機能である CSP に頼るのではなく、アプリ側の「サニタイズ処理」や「エスケープ処理」で対策することが大原則となります。あくまで CSP は 「最後の砦」 と考えてください。
CSPに関する注意
ストア型XSS(Stored XSS)が仕掛けられていたとしても、CSP(Content Security Policy)が適切に構成されており、それを正しく解釈できるブラウザでアクセスすれば、XSS攻撃は無効化されます。しかし、CSPに十分に対応していないブラウザからアクセスしたときには、XSS攻撃がそのまま実行されてしまいます。
Next.js では next.config.ts で CSP
を設定することができます。詳しくは、以下の参照してください (記事の後半に
next.config.ts の設定例があります)。また、適切に CSP
が設定されたかどうかは、デベロッパツールのレスポンスヘッダから確認することができます。
(プロンプト例)
Next.js 15 (TypeScript) において
next.config.tsで CSP を設定する方法について教えてください。また、一般的な設定例を示してください。なお、Googleフォントを使っているので、それは制限したくありません。
8 おまけ:Next.js ServerActions (Custom Invocation)
Next.js 13.4 以降では、APIルート (=src/app/api/ 以下に route.ts
を設ける枠組み) を使わずに、バックエンド処理
を直接的に記述できる仕組みとして「ServerActions」が導入されています。これを活用することにより、フロントエンドとバックエンドの連携が、かなりシンプルに書けるようになります
(開発の生産性がグッとあがります🤩)。
ただし、すべてのAPIルートを無条件に ServerActions
に置き換えられるわけではなく、いくつかの条件や前提がある点に注意が必要です。特に、ServerActions
は useEffect の内部で呼び出すことができない点に注意が必要です。
このプロジェクトでは、サインアップ (/signup) のバックエンド処理
(新規登録のユーザ情報のデータベースへの書き込みなど) を、APIルートを設けずに ServerActions
で記述しています。
// フォームの送信処理
const onSubmit = async (signupRequest: SignupRequest) => {
try {
startTransition(async () => {
// ServerActions (Custom Invocation) の利用
const res = await signupServerAction(signupRequest);
if (!res.success) {
setRootError(res.message);
return;
}
setIsSignUpCompleted(true);
});
} catch (e) {
const errorMsg =
e instanceof Error ? e.message : "予期せぬエラーが発生しました。";
setRootError(errorMsg);
}
};上記の 第69行目 で ServerActions の仕組みを利用して以下に示す
src/app/_actions/signup.ts の signupServerAction
という処理を呼び出しています。
以下に ServerActions の本体を示します。ファイル先頭に "use server"; のように記述しているのがポイントです。
"use server";
import { prisma } from "@/libs/prisma";
import { signupRequestSchema } from "@/app/_types/SignupRequest";
import { userProfileSchema } from "@/app/_types/UserProfile";
import type { SignupRequest } from "@/app/_types/SignupRequest";
import type { UserProfile } from "@/app/_types/UserProfile";
import type { ServerActionResponse } from "@/app/_types/ServerActionResponse";
// ユーザのサインアップのサーバアクション
export const signupServerAction = async (
signupRequest: SignupRequest,
): Promise<ServerActionResponse<UserProfile | null>> => {
try {
// 入力検証
// 💀 現状では日本語のPWも受入れてしまう -> SignupRequest のバリデーション見直し
const payload = signupRequestSchema.parse(signupRequest);
// 💡スパム登録対策(1秒遅延)
await new Promise((resolve) => setTimeout(resolve, 1000));
// 既に登録済みユーザのサインアップではないか確認
const existingUser = await prisma.user.findUnique({
where: { email: payload.email },
});
if (existingUser) {
// 💀 このアカウントがシステムに存在することを知らせてしまうことになる。
// 認証メールを送信するなどの方法が望ましい
return {
success: false,
payload: null,
message: "このメールアドレスは既に使用されています。",
};
}
// パスワードのハッシュ化
// 💀 ハッシュ化せずにPW保存(ダメ絶対)
const hashedPassword = payload.password;
// const hashedPassword = await bcrypt.hash(payload.password, 10);
// ユーザの作成
const user = await prisma.user.create({
data: {
email: payload.email,
password: hashedPassword,
name: payload.name,
},
});
// レスポンスの生成
// 💀 パスワードは無論、不要な情報はレスポンスしない。
const res: ServerActionResponse<UserProfile> = {
success: true,
payload: userProfileSchema.parse(user), // 余分なプロパティを削除,
message: "",
};
return res;
} catch (e) {
const errorMsg = e instanceof Error ? e.message : "Internal Server Error";
console.error(errorMsg);
return {
success: false,
payload: null,
message: errorMsg,
// 💀 エラーメッセージはユーザに見せない方が良い
// システム内部構造や依存関係をユーザに漏らす可能性がある
// message: "サインアップのサーバサイドの処理に失敗しました。",
};
}
};本来、データベースの操作はバックエンドでしか許されていない処理 となります (クライアントサイドで prisma のような ORM は読み込めません)。それにも関わらず、あたかもクライアント側からバックエンド処理を直接的に呼び出しているように記述できること が、Server Actions のセールスポイントになっています。ただし、実際には、内部的にAPIエンドポイントがつくられ、それを叩いている仕組みになります。
この仕組みを正しく理解せずに使ってしまうと、セキュリティ上のリスクを生む可能性があります。とても便利な仕組みですが、「何がクライアント側に公開されるのか」「どの処理が安全なのか」をよく考えた上で使うようにしてください。
8.0.1 参考
こちら のリポジトリは、同じ機能を持つ画面を、以下の4バージョンで実装して比較したものです。ServerAction に興味があるひとは参考にしてみてください。
- CSR (Client Side Rendering) only PG3で扱った手法
- SSR (Server Side Rendering) only
- Hybrid1(CSR+SSR+ServerAction(Custom Invocation))
- Hybrid2(CSR+SSR+ServerAction(Progressive Enhancement))
9 実装課題2
実装課題2として、以下の内容に取り組み、その GitHubリポジトリ (Public) の「URL」 を Teams に提出してください。
- 本教材web-sec-playground-1
を参考に「トークンベース認証」もしくは「セッションベース認証」の
いずれかを用いた認証・認可機能を備えたウェブアプリ を Next.js
で実装してください。また、教材には実装されていない何らかの認証・認可に関する機能 を
2つ以上実装 してください。何も思いつかなければ、以下を実装してみてください。
- 連続N回のログイン失敗でアカウントロックする機能
- サインアップのときに確認用パスワードを要求するようなUI機能
- サインアップのときにパスワード強度を表示するような機能
- パスワードの変更機能
- サインアップにおけるメールアドレスのリアルタイムの重複チェック機能
- CAPTCHA (bot対策)
- 秘密の質問によるパスワードリセット機能
- ログイン試行の間隔制限機能
- ログイン履歴の表示機能
- チェックボックス「次回からログインIDを自動入力する」な機能
- キーロガー対策のソフトウェアキーボードによるパスワード入力機能
- 提出期限:2025年08月31日 (日) 23時59分 (これ以降に確認・評価します)
- Teamsで評価をフィードバックした後は、修正版の再提出・追提出があっても原則として再評価はしません。
- 想定取り組み時間:最低でも「8時間以上」を費やしてください。
なお、アプリが認証・認可機能 (および、それを確認できる要素) を持っていれば OK で、アプリ自体が何らかの機能を提供する必要はありません。
9.1 評価の観点
- GitHubリポジトリの README.md
の内容を「5点満点」、ソースコードを「5点満点」で「合計10点満点」で評価します。「7.6点」を標準とします。
- 評価に際しては、まず README.md を読んでから、それに関係しそうなソースコードを確認します。そのため、README.md に書かれていない内容は、実装していても評価でスルーされる可能性があります。実装した機能や創意工夫した箇所は、詳細に README.md に記載してください。
- README.md には 最低でも3枚以上の「画像」、もしくは、1つ以上の「動画」 を含めてください。
- 基本的に
mainブランチのソースコードを確認します。- 評価の際、(基本的には) アプリを起動させる予定はないので環境変数等の共有は不要です。
- ガチガチに セキュアな設計 としてしてください。
- パスワードは bcrypt を使ってハッシュ化して保存、Cookie を使う場合は適切な属性を設定、CSP も適切に設定するなどを講じてください。
- web-sec-playground-1 をベースに開発するときは、使用しない認証方式に関連するコードやコメント、「ニュース」や「ショップ」に関連するコード (処理や型) は全て削除 してください。残っている場合は減点とします。
9.2 その他
- 実装指示「教材には実装されていない何らかの認証・認可に関する機能」については拡大解釈して OK です。悩む場合は、Teamsのチャットで相談してください。
- 作成したリポジトリは、ポートフォリオ (作品集) のなかに追加しておくことを強くお勧めします。
- 提出されたリポジトリは、知能情報コースの教員と学生に共有することがあります。